Clear Sky Science · it
Un algoritmo di riconoscimento delle immagini per pezzi ad alta frequenza e a grana fine basato su un'architettura di rete multi-ramo
Occhi più intelligenti per i pezzi di fabbrica
Le fabbriche moderne dipendono da telecamere e computer per smistare migliaia di pezzi metallici quasi identici a grande velocità. Quando questi pezzi differiscono solo per minuscoli dettagli superficiali, anche i software di riconoscimento delle immagini avanzati possono confondersi, portando a errori di smistamento, ritardi nella produzione e costi aggiuntivi. Questo studio presenta un nuovo modo per far "vedere" alle macchine e distinguere componenti molto simili, promettendo una produzione automatizzata più affidabile, flessibile ed efficiente.
Perché è difficile distinguere parti simili
In molte linee di produzione, i cosiddetti pezzi ad alta frequenza—parti metalliche piatte prodotte in grandi quantità—devono essere classificati in dozzine di categorie. La sfida è che i pezzi appartenenti alla stessa categoria possono mostrare texture superficiali complesse, mentre parti di categorie diverse possono apparire quasi identiche dall'alto. Le variazioni di illuminazione e di posizionamento davanti alla telecamera rendono il problema ancora più difficile. Questo tipo di compito rientra in ciò che gli informatici chiamano riconoscimento a grana fine: non si tratta solo di distinguere un’auto da una persona, ma di separare due pezzi molto simili basandosi su indizi sottili.
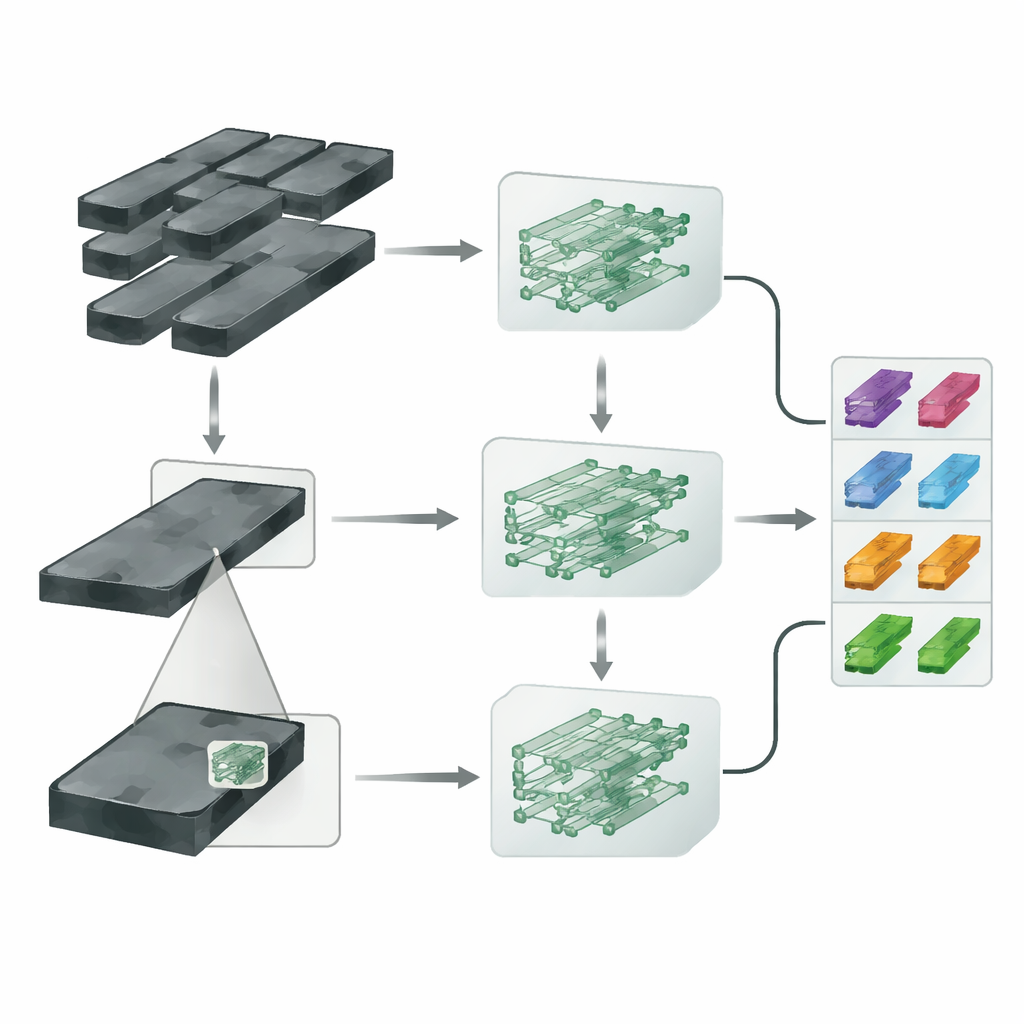
Un doppio approccio per osservare ogni pezzo
I ricercatori partono da una rete neurale compatta nota come EfficientNet-B0 e la trasformano in un sistema multi-ramo che chiamano MBEN. Invece di fornire alla rete solo l’immagine intera del pezzo, lasciano innanzitutto che il modello individui approssimativamente quale area dell’immagine contiene le informazioni più distintive. Un modulo speciale di rilevamento di regioni, addestrato in modo debolmente supervisionato, crea una sorta di mappa di calore che evidenzia le zone chiave probabili, quindi ritaglia una patch più piccola intorno a quell’area. L’immagine completa percorre un ramo della rete (il ramo globale), mentre il primo piano ritagliato percorre un altro ramo (il ramo locale). Questo progetto permette al sistema di apprendere sia l’aspetto generale sia le differenze localizzate e minute che separano un tipo di pezzo dall’altro.
Insegnare al modello ciò che conta davvero
Fornire due viste non basta; la rete deve anche essere addestrata a concentrarsi sulle distinzioni rilevanti. Per farlo, gli autori progettano un modulo di aumento della funzione di perdita—regole che guidano come la rete si aggiusta durante l’allenamento. Una parte di questo modulo spinge il sistema a prestare maggiore attenzione alle categorie che al momento trova più confuse, in modo che non diventi troppo sicuro sui casi facili trascurando quelli difficili. Un’altra componente incoraggia le immagini dello stesso tipo di pezzo a finire vicine nella rappresentazione interna della rete, mentre spinge tipi diversi più lontano. Insieme, questi meccanismi modellano una mappa interna delle categorie più chiara, migliorando la probabilità che immagini nuove e non viste vengano classificate correttamente.
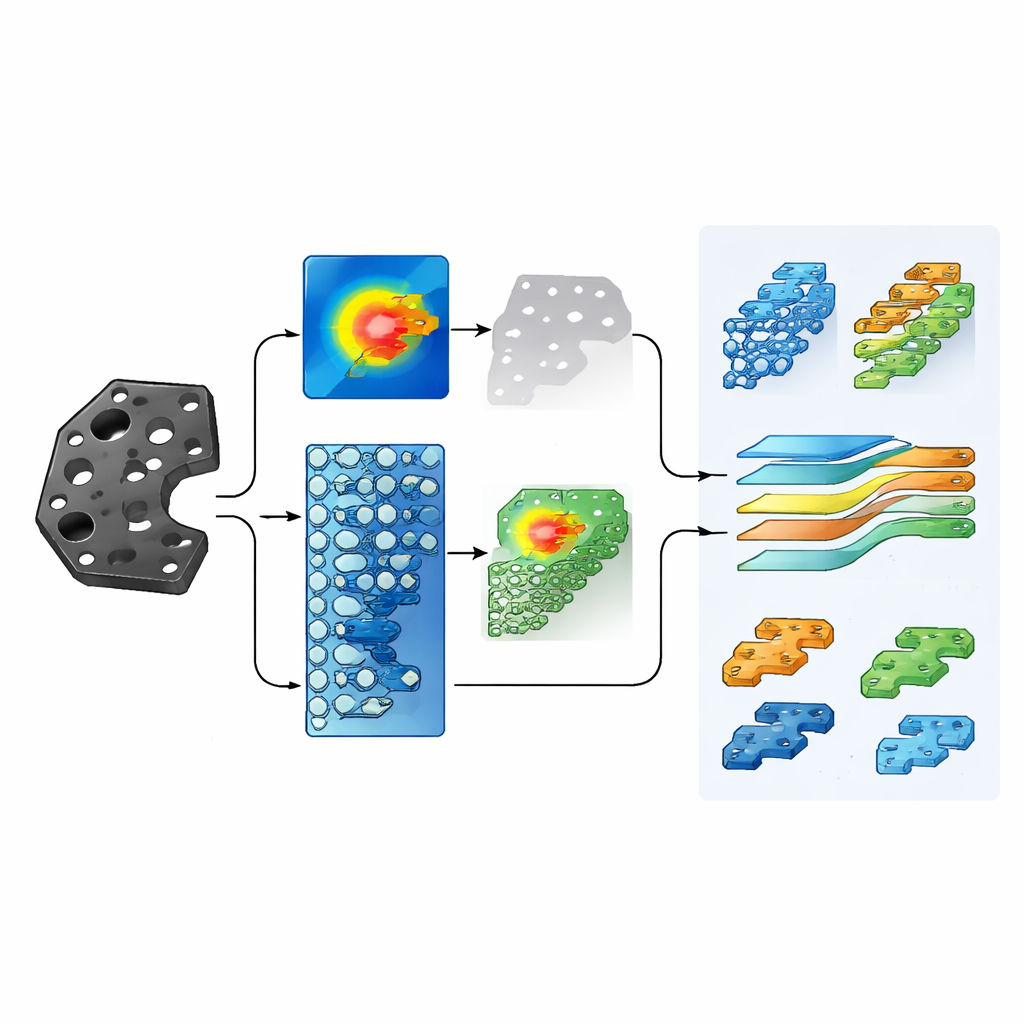
Fondere il quadro d’insieme con il dettaglio
Dopo che i rami globale e locale hanno prodotto ciascuno le proprie predizioni, un modulo di fusione dei rami le combina in una decisione finale. I ricercatori regolano quanto ciascun ramo debba contribuire, scoprendo che dare un peso leggermente maggiore all’immagine globale ma fare ancora forte affidamento sul primo piano funziona meglio. Testano il metodo su un dataset personalizzato di 20 tipi di pezzi ad alta frequenza fotografati con illuminazione realistica da stabilimento, con migliaia di immagini aumentate tramite tecniche di data augmentation come rotazioni e ritagli casuali. Il sistema MBEN raggiunge un’accuratezza del 98,75%—diversi punti percentuali in più rispetto a una serie di metodi esistenti per il riconoscimento a grana fine—pur utilizzando risorse computazionali relativamente modeste.
Cosa significa per la produzione reale
Lo studio mostra che combinare il contesto dell’immagine intera, patch di dettaglio scoperte automaticamente e regole di addestramento attentamente progettate può rendere la visione artificiale molto più affidabile per compiti industriali difficili. Per i produttori, tali miglioramenti potrebbero tradursi in meno errori di smistamento, meno ispezioni manuali e maggiore flessibilità nel passare tra molti tipi di prodotti simili. Sebbene il lavoro non affronti ancora il problema dei dati sbilanciati del mondo reale, in cui alcuni tipi di pezzi sono molto più rari di altri, i risultati suggeriscono che occhi digitali più intelligenti e selettivi possono stare al passo con linee di produzione sempre più precise e variegate.
Citazione: Deng, J., Sun, C., Lin, J. et al. An image recognition agorithm for fine-grained high-frequency workpieces based on a multi-branch network architecture. Sci Rep 16, 11067 (2026). https://doi.org/10.1038/s41598-026-41639-4
Parole chiave: riconoscimento di immagini industriali, classificazione a grana fine, controllo qualità automatizzato, visione artificiale nella produzione, reti neurali