Clear Sky Science · it
Un dataset 3D facciale con topologia standardizzata e diversità di emozioni e unità d’azione per asiatici orientali
Perché i volti digitali contano
Dalle videochiamate alla realtà virtuale, le nostre vite sono piene di volti digitali. Tuttavia molti dei sistemi informatici alla base di questi volti sono addestrati su dati limitati, spesso concentrati sulle popolazioni occidentali e su un ristretto insieme di espressioni. Questo articolo presenta AST-Face, un nuovo dataset 3D facciale incentrato su giovani adulti dell’Asia orientale che mira a fornire ai ricercatori basi migliori per animazione, studi sull’emozione e interazione uomo–computer.
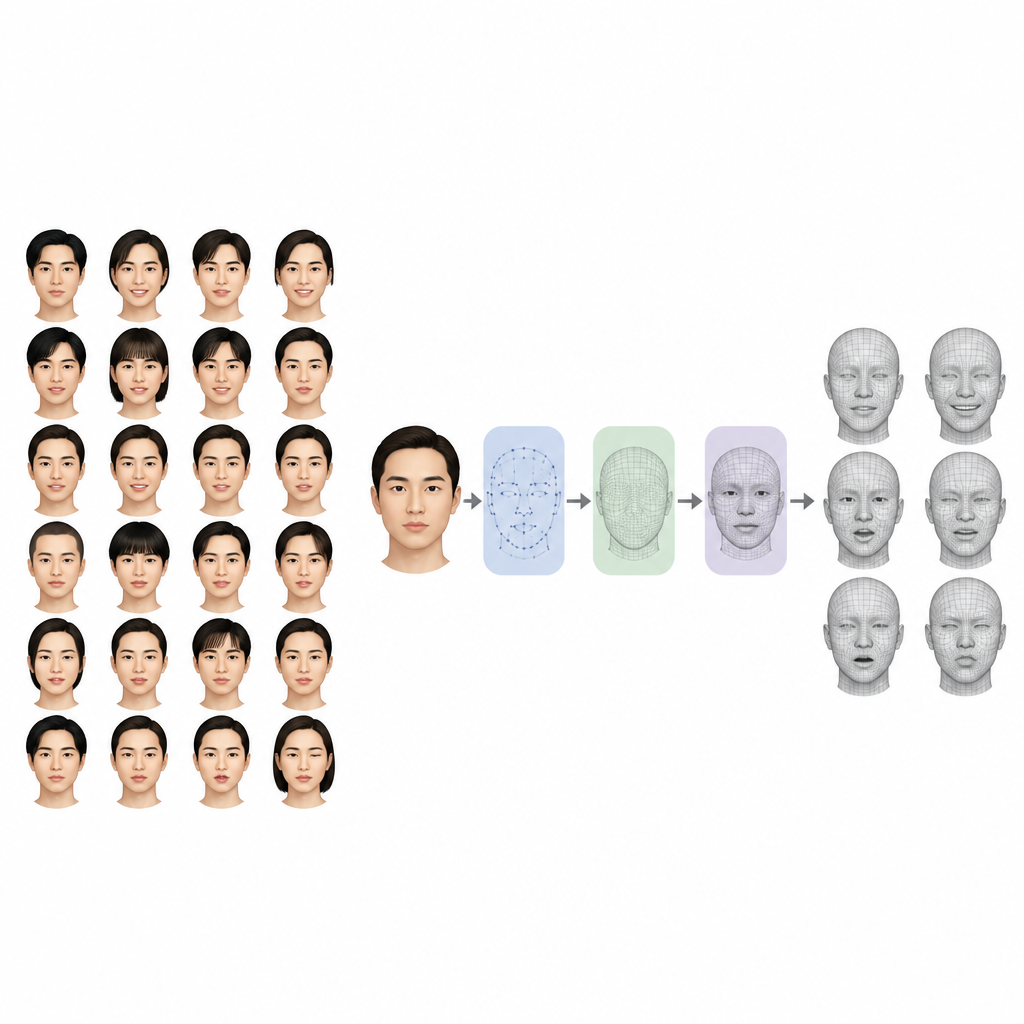
Cosa contiene la nuova raccolta di volti
Il dataset AST-Face include scansioni 3D dettagliate di 98 partecipanti dell’Asia orientale di età compresa tra 18 e 30 anni. Per ciascuna persona il team ha acquisito un volto neutro, sei emozioni comuni (felicità, rabbia, tristezza, sorpresa, paura e disgusto) e nove movimenti facciali specifici basati sui muscoli. Questi movimenti seguono un sistema noto che scompone le espressioni in piccole unità d’azione, come sollevare la parte interna delle sopracciglia o tirare gli angoli della bocca. Un sottoinsieme di volontari ha inoltre consentito foto a colori sincronizzate da tre angolazioni della camera, creando una risorsa più ricca per studi che combinano forma 3D e immagini convenzionali.
Come sono stati catturati e puliti i volti
Per rendere i dati affidabili e comparabili, i ricercatori hanno costruito un apparato di acquisizione rigorosamente controllato. Uno scanner 3D ad alta precisione ha registrato i dettagli fini di ogni volto mentre tre fotocamere a colori filmavano da sinistra, centro e destra. L’illuminazione regolabile ha ridotto ombre e riflessi, e un dispositivo di posizionamento ha aiutato i partecipanti a mantenere una posa stabile. Tutti hanno seguito lo stesso copione di registrazione: prima un volto neutro rilassato, poi le sei emozioni e infine le nove unità d’azione, ognuna guidata da personale formato. Successivamente le scansioni grezze sono state pulite eliminando lo sfondo e le aree del collo, allineando la posa della testa, correggendo le proprietà della superficie ed estraendo 84 punti di riferimento standard su ogni volto.

Rendere ogni volto confrontabile
Una sfida centrale nella ricerca sui volti 3D è che le scansioni grezze non condividono la stessa struttura digitale. Possono differire nel numero di punti che contengono e in come questi punti sono connessi, il che rende difficile confrontare il sorriso di una persona con quello di un’altra. AST-Face affronta questo eseguendo ogni scansione attraverso un processo di allineamento in due fasi. Prima, un modello facciale flessibile viene adattato per catturare movimenti ampi come bocche aperte e sopracciglia sollevate. Poi un avanzato algoritmo di corrispondenza deforma delicatamente una mesh template condivisa in modo che tutti i volti finali abbiano conteggio di punti e connettività identici. Questa struttura unificata permette ai ricercatori di confrontare i volti punto per punto tra persone ed espressioni senza dover progettare complessi pipeline di pre-elaborazione propri.
A cosa possono servire i dati
Il dataset finito offre diversi livelli di informazione: mesh 3D standardizzate, punti di riferimento, mappe dettagliate di come ogni espressione differisce dal volto neutro e etichette verificate per ogni emozione e unità d’azione. I file resi pubblici escludono qualsiasi texture identificabile, mentre le scansioni grezze e le immagini a colori sono disponibili sotto un accordo d’uso dei dati per proteggere la privacy dei partecipanti. Con questa struttura, AST-Face può supportare un’ampia gamma di lavori, dall’animazione facciale più naturale guidata da controlli simili ai muscoli, ai modelli di apprendimento automatico che studiano come le espressioni variano tra gli individui, fino a sistemi cross-modali che collegano forma 3D e immagini 2D.
Cosa significa per i volti digitali futuri
In termini semplici, AST-Face offre ai ricercatori un set di volti 3D di alta qualità e ben organizzato dell’Asia orientale che parlano tutti lo stesso linguaggio digitale. Combinando espressioni diverse, etichette muscolo-based accuratamente verificate e una struttura di mesh condivisa, il dataset rende più facile costruire e testare algoritmi che richiedono movimenti facciali coerenti e realistici. Pur concentrandosi su un gruppo di età specifico ed espressioni posate sotto illuminazione controllata, aiuta a colmare le lacune demografiche nelle risorse esistenti e pone una base più chiara per volti digitali futuri più inclusivi e accurati.
Citazione: Zhao, Y., Gong, G., Li, Y. et al. A Topology Standardized 3D Facial Dataset with Emotion and Action Unit Diversity for East Asians. Sci Data 13, 735 (2026). https://doi.org/10.1038/s41597-026-07098-2
Parole chiave: dataset 3D facciale, espressione facciale, volti dell’Asia orientale, unità d’azione, standardizzazione della topologia