Clear Sky Science · fr
Modèle hybride explicable d’apprentissage automatique pour prédire le retard de croissance et identifier les facteurs de risque clés chez les enfants éthiopiens de moins de cinq ans
Pourquoi la prédiction de la croissance des enfants compte
Dans les pays à faibles revenus, de nombreux enfants ne grandissent pas aussi grands ni aussi robustes qu’ils le devraient en raison d’un manque prolongé de nourriture adéquate, de maladies et de mauvaises conditions de vie. Cette condition, appelée retard de croissance (stunting), nuit à l’apprentissage, à la santé et aux revenus futurs. En Éthiopie, plus d’un enfant de moins de cinq ans sur trois est touché. L’étude résumée ici examine comment un nouveau type de programme informatique peut aider les agents de santé à repérer quels enfants sont les plus à risque, en utilisant des informations déjà recueillies par les enquêtes, tout en expliquant comment et pourquoi le programme en arrive à ses conclusions.
Voir le retard de croissance comme autre chose qu’un chiffre
Les chercheurs ont commencé par les données de l’Enquête démographique et de santé éthiopienne de 2019, qui contient des détails sur des milliers d’enfants de moins de cinq ans et leurs familles. Pour chaque enfant, l’enquête enregistre la taille et l’âge afin que le niveau de retard de croissance puisse être regroupé en trois catégories : croissance normale, retard de croissance modéré ou retard de croissance sévère. Comme beaucoup moins d’enfants se trouvent dans le groupe sévère que dans le groupe normal, l’équipe a rééquilibré les données avec soin afin que l’ordinateur apprenne à reconnaître les trois catégories équitablement plutôt que d’être biaisé vers la plus fréquente. Ils ont ensuite nettoyé, transformé et vérifié les informations pour s’assurer qu’elles convenaient à l’analyse.
Mélanger deux outils intelligents en un seul
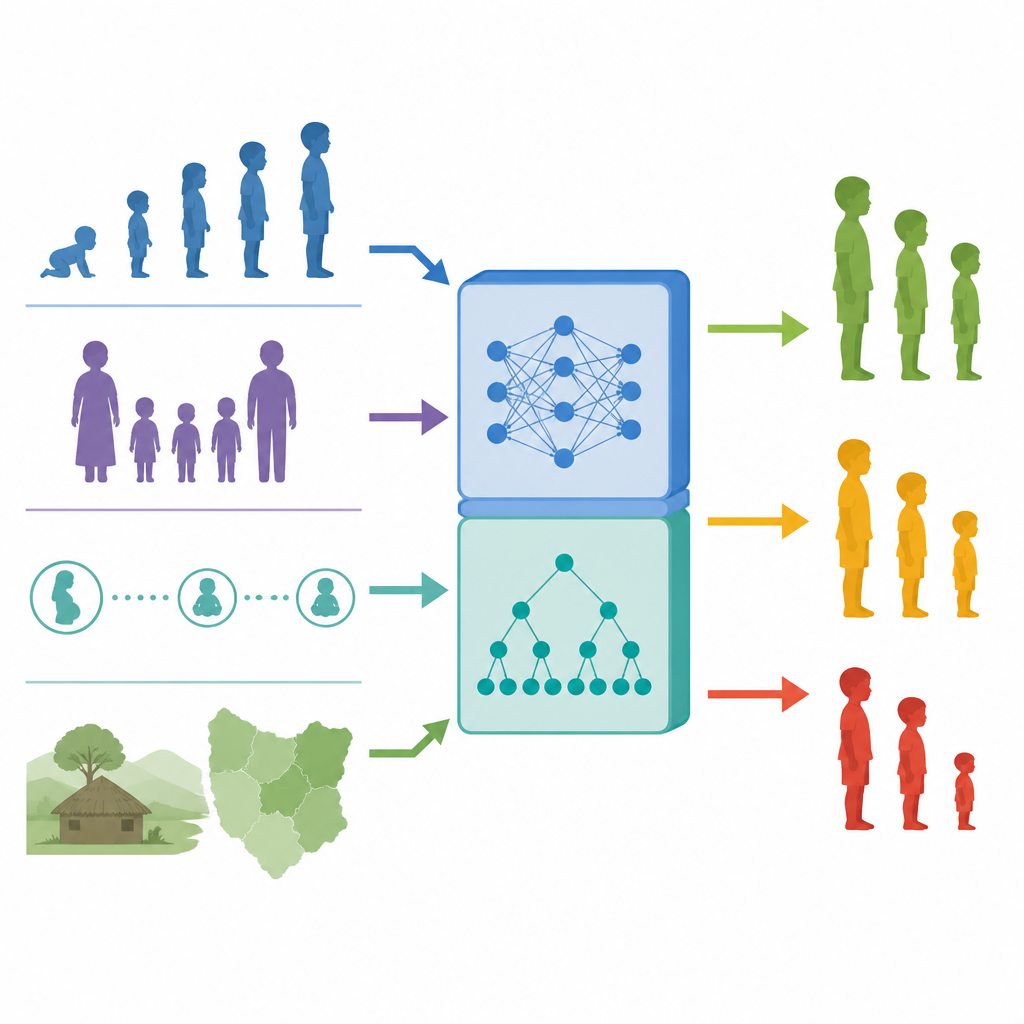
Plutôt que de s’appuyer sur un seul type de modèle d’apprentissage automatique, les auteurs ont créé un système hybride qui combine deux approches performantes. Une partie, appelée Extra Trees, construit de nombreux arbres de décision qui excellent à trouver des motifs dans des données mixtes, comme la région, la taille de la famille et l’histoire des naissances. L’autre partie, appelée perceptron multicouche, est un réseau de neurones profond simple qui peut saisir des relations plus subtiles une fois les données transformées. Dans leur conception, le modèle basé sur les arbres traite d’abord les données et transmet des signaux enrichis au réseau neuronal, qui produit ensuite la prédiction finale indiquant si un enfant est normal, modérément en retard de croissance ou sévèrement en retard de croissance.
Précision avec prudence
Le modèle hybride a été entraîné sur plus de onze mille dossiers d’enfants et testé sur un ensemble distinct. Il a atteint environ 94 % d’exactitude, de précision, de rappel et de score F1, et a montré de bonnes performances en validation croisée, ce qui suggère que ses prédictions sont stables plutôt qu’une anomalie d’un échantillon. Une matrice de confusion détaillée a révélé que le modèle est particulièrement performant pour distinguer clairement les enfants normaux des enfants sévèrement en retard de croissance, tandis que la plupart des erreurs se produisent aux frontières entre le retard modéré et le retard sévère. Les auteurs soulignent que l’enquête ne fournit qu’un instantané dans le temps, si bien que le modèle identifie des associations fortes plutôt que de prouver qu’un facteur donné cause directement le retard de croissance.
Ouvrir la boîte noire
Une haute précision seule ne suffit pas pour les décisions de santé publique, car les décideurs et les cliniciens ont besoin de comprendre pourquoi un système signale un enfant comme à risque. Pour répondre à cela, l’étude utilise des outils d’intelligence artificielle explicable, en particulier une méthode appelée LIME, qui décompose chaque prédiction en contributions provenant de facteurs individuels. En examinant l’importance des variables et les explications locales, les chercheurs ont constaté que l’âge de l’enfant, la région de résidence, l’intervalle entre les naissances et le nombre d’enfants de moins de cinq ans dans le foyer étaient les prédicteurs les plus influents. D’autres signaux utiles incluaient le niveau d’éducation maternelle, la richesse du ménage et l’accès à l’eau potable, faisant écho aux études antérieures sur la nutrition.
De la prédiction à l’action concrète
Pour un lecteur non spécialiste, le message principal est que l’utilisation prudente de l’intelligence artificielle peut aider les agents de santé à passer du simple comptage du nombre d’enfants en retard de croissance à l’identification des enfants et des communautés qui ont le plus besoin d’aide en urgence. Le modèle hybride ne nous dit pas les causes ultimes du retard de croissance, mais il offre un moyen fiable et transparent de repérer les enfants présentant un risque statistique plus élevé sur la base de questions d’enquête facilement disponibles. Utilisé aux côtés du jugement clinique, il pourrait orienter des programmes ciblés en matière de nutrition, d’accès à l’eau potable et de planning familial, aidant l’Éthiopie et des pays similaires à concentrer des ressources limitées là où elles peuvent le plus protéger la croissance et le potentiel des enfants.
Citation: Wudu, T.K., Endalew, A.A. & Dires, A.A. Explainable hybrid machine learning model for predicting stunting and identifying key risk factors among Ethiopian children under five. Sci Rep 16, 16204 (2026). https://doi.org/10.1038/s41598-026-46417-w
Mots-clés: retard de croissance infantile, Éthiopie, apprentissage automatique, IA explicable, nutrition infantile