Clear Sky Science · fr
Un cadre de deep learning embarqué pour la détection de violences en temps réel et la génération d’alertes
Pourquoi des caméras plus intelligentes comptent pour la sécurité quotidienne
Les bagarres et agressions dans la rue, les écoles ou les transports publics se déroulent souvent en quelques secondes, bien avant que des opérateurs humains n’aient pu scruter tous les écrans de surveillance et appeler à l’aide. Cette étude présente une méthode permettant à de petits ordinateurs peu coûteux — des dispositifs aussi modestes qu’une carte Raspberry Pi — d’analyser la vidéo en temps réel et de signaler automatiquement les comportements probablement violents. En comprimant des techniques puissantes d’analyse vidéo dans un système efficace embarqué, ce travail montre comment des caméras existantes pourraient devenir des sentinelles plus rapides et plus fiables sans dépendre de centres de données distants ni d’une attention humaine constante.
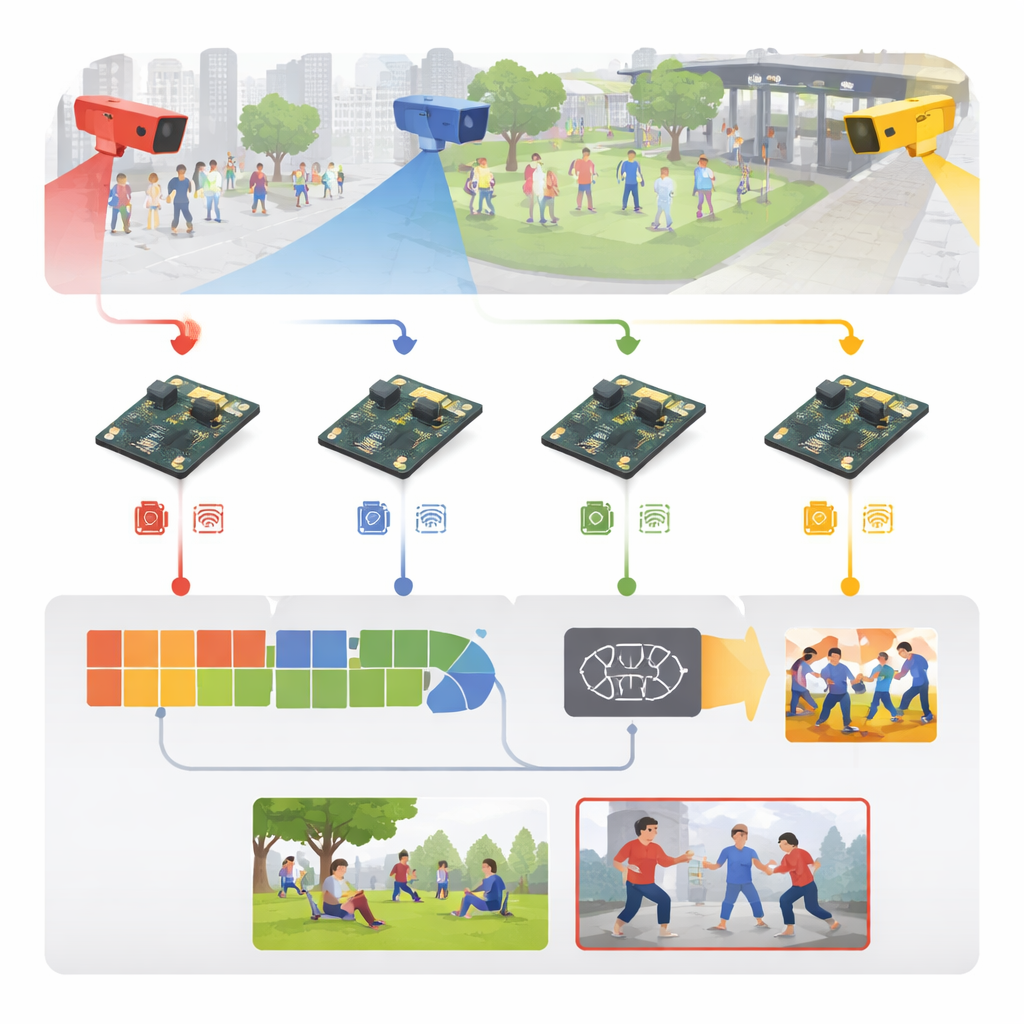
Transformer la vidéo brute en signaux d’alerte précoces
Le système part de séquences de surveillance ordinaires provenant d’endroits comme des arènes sportives, des trottoirs, des allées de campus ou des couloirs intérieurs. Plutôt que de diffuser toute cette vidéo vers un serveur central, chaque caméra envoie ses images à une carte embarquée voisine. Là, les images reçues sont standardisées — redimensionnées, nettoyées et légèrement altérées par retournements, rotations et variations de luminosité pendant l’entraînement — afin que le modèle apprenne à faire face à des conditions d’éclairage, des points de vue et des densités de foule variés. Les auteurs constituent également un corpus d’entraînement riche : cinq jeux de données publics bien connus plus une nouvelle collection à six catégories incluant coups de poing, coups de pied, attaques impliquant une arme, violence de foule, course, et interactions normales.
Comment fonctionne le cerveau compact à l’intérieur de la boîte
Au cœur du système se trouve un moteur d’apprentissage à deux étapes allégé. D’abord, un module image léger analyse chaque image à la recherche d’indices visuels pertinents — silhouettes du corps, positions des bras et des jambes, et contours de mouvement — en utilisant des opérations convolutionnelles économes empruntées aux modèles de vision pour mobiles. Ensuite, un second module examine une courte séquence d’images pour comprendre comment ces indices évoluent dans le temps, saisissant la différence entre, par exemple, une tape amicale et un coup de poing. Cela se fait au moyen d’une structure récurrente efficace qui retient le mouvement récent sans la lourde charge de calcul des réseaux vidéo plus volumineux. Une couche finale simple transforme cette compréhension spatio‑temporelle en l’une des six étiquettes d’activité, séparant les mouvements ordinaires des agressions probables.
Adapter l’apprentissage profond à une petite carte basse consommation
Concevoir un modèle astucieux n’est que la moitié de l’histoire ; le faire fonctionner rapidement sur un ordinateur de la taille d’une paume est le véritable défi. Les auteurs considèrent l’ensemble du système comme une chaîne d’ingénierie : ils commencent par une version entraînée sur une station de travail graphique puissante, puis la convertissent en un format portable et la compressent agressivement. La précision numérique est réduite de sorte que les poids occupent un quart de la mémoire initiale, et les parties inutiles du réseau sont élaguées. En utilisant des outils d’optimisation spécialisés hors dispositif, ils génèrent un modèle réglé pouvant s’exécuter efficacement sur le Raspberry Pi via un runtime optimisé. Le résultat est un système qui traite environ 26 images vidéo par seconde avec un retard d’environ 38 millisecondes par image, tout en ne consommant que quelques watts — suffisamment rapide et sobre pour une exploitation continue sur le terrain.

Tests, confiance et limites du jugement machine
Pour vérifier si leur observateur compact est à la fois précis et fiable, les chercheurs l’ont soumis à une batterie de tests. Sur des jeux de référence allant des patinoires de hockey aux rues urbaines, et sur leur propre jeu de données à six classes, le système a correctement étiqueté les événements dans environ 97 cas sur 100 et a montré un bon équilibre entre la détection des actes violents et la limitation des fausses alertes. Des comparaisons avec des modèles vidéo plus élaborés — tels que des réseaux convolutionnels 3‑D complets et des architectures basées sur des transformers — ont montré que cette approche plus légère peut égaler ou dépasser leur précision tout en utilisant beaucoup moins de ressources de calcul. L’équipe a aussi visualisé les zones sur lesquelles le modèle « regarde » dans chaque image, constatant que son attention se concentre naturellement sur les membres en mouvement et les contacts rapprochés entre personnes plutôt que sur des détails d’arrière‑plan non pertinents, ce qui contribue à renforcer la confiance dans ses décisions.
Ce que cela signifie pour des espaces plus sûrs et plus intelligents
Le message principal de l’étude n’est pas d’avoir inventé un type complètement nouveau de réseau neuronal, mais d’avoir montré comment emballer des techniques éprouvées dans un outil pratique et temps réel pour du matériel modeste. En équilibrant soigneusement conception du modèle, préparation des données et compression au moment du déploiement, les auteurs livrent un système embarqué capable de surveiller la vidéo en direct, de reconnaître les violences probables et de déclencher des alertes avec faible latence et faible consommation d’énergie. Ils reconnaissent aussi des défis ouverts : le système peut encore être trompé par un mauvais éclairage, des scènes très encombrées ou des mouvements rapides de type sportif, et toute technologie de ce type doit être déployée en tenant compte de la vie privée, des biais et de la supervision humaine. Malgré tout, ce travail ouvre la voie vers un avenir où de nombreuses caméras ordinaires seraient associées à de petits ordinateurs discrets qui aident à détecter plus tôt les dangers et favorisent des réponses plus rapides et mieux informées.
Citation: Salman, M., Abbas, N., ur Rahman, S.I. et al. An embedded deep learning framework for real-time violence detection and alert generation. Sci Rep 16, 10805 (2026). https://doi.org/10.1038/s41598-026-44939-x
Mots-clés: détection de violences, vision embarquée, IA en périphérie, surveillance vidéo, apprentissage profond