Clear Sky Science · fr
Apprentissage profond par renforcement pour l’optimisation des ressources réseau dans les réseaux MIMO-NOMA afin de maximiser l’utilisation avec un minimum de surcharge
Pourquoi des réseaux mobiles plus intelligents comptent
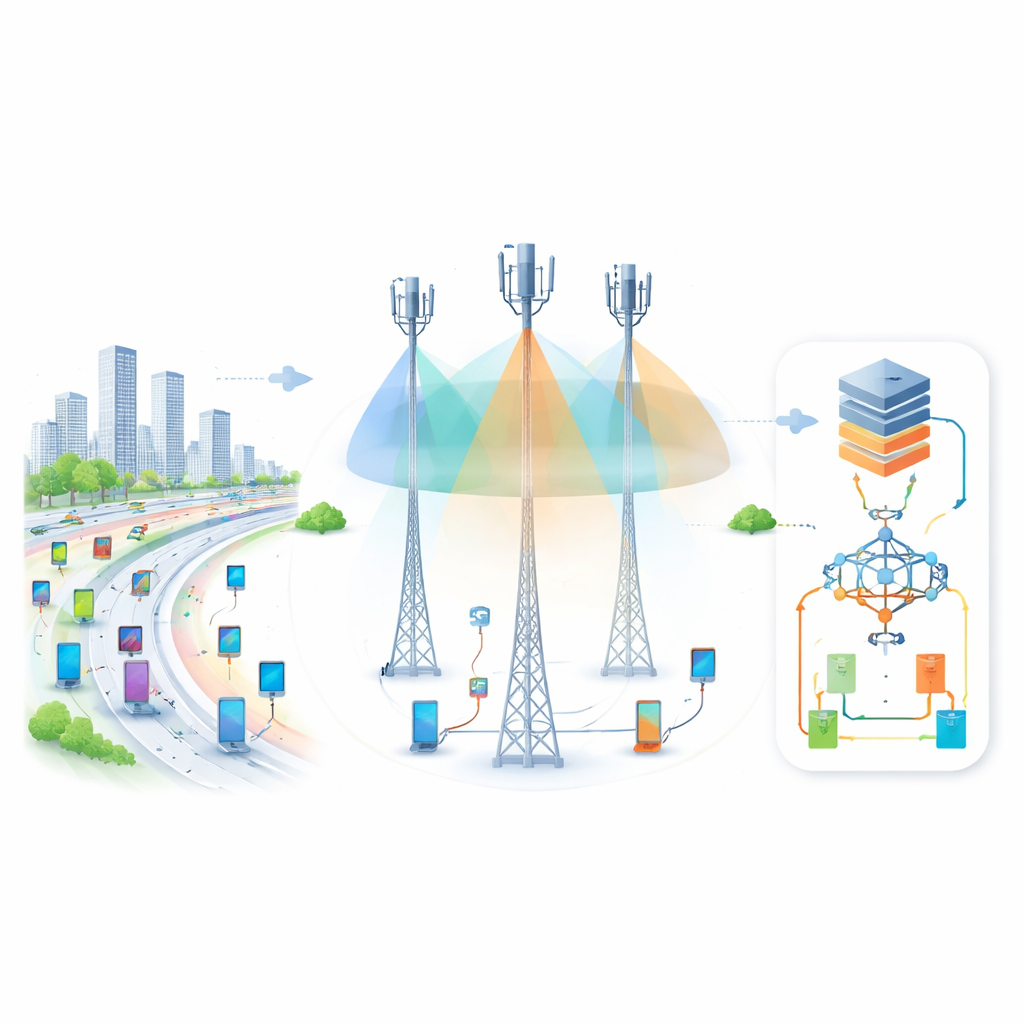
Alors que nos téléphones, voitures et une multitude de capteurs se disputent la bande passante sans fil, les réseaux actuels peinent à maintenir une connexion fluide pour tous, en particulier lorsque les utilisateurs se déplacent rapidement à travers les villes et le long des autoroutes. Cet article présente une nouvelle façon de rendre les réseaux 5G et 6G futurs beaucoup plus efficaces et fiables en apprenant au réseau, en temps réel, quelles connexions utiliser et comment partager des ressources radio limitées entre de nombreux utilisateurs avec un minimum de gaspillage.
Des ondes encombrées et le problème de saturation
Les systèmes sans fil modernes doivent desservir un grand nombre d’utilisateurs en mouvement permanent. De nouvelles technologies telles que le MIMO, qui utilise plusieurs antennes simultanément, et le NOMA, qui permet à plusieurs utilisateurs de partager la même portion de spectre, promettent d’importants gains de capacité. Mais dans la pratique, quand les gens se déplacent en voiture ou en train et que les signaux varient rapidement, il devient extrêmement difficile de décider à quelle station de base connecter chaque utilisateur, quelle puissance attribuer et comment empêcher les utilisateurs de s’interférer mutuellement. Beaucoup de méthodes d’optimisation existantes supposent des conditions relativement stables ou une connaissance parfaite du canal radio, des hypothèses qui s’effondrent dans des environnements réels rapides et encombrés.
Permettre au réseau de prédire la meilleure connexion
Les auteurs proposent une approche appelée OSIANRO qui commence par améliorer l’affectation des appareils aux réseaux et aux canaux. Plutôt que de s’en remettre à des règles fixes, elle utilise une version renforcée d’une méthode d’apprentissage automatique populaire connue sous le nom de gradient boosting. Ce modèle amélioré apprend à partir de nombreux exemples de comportements passés du réseau — tels que la puissance du signal, la latence et le type d’application utilisé — pour prédire si un choix de connexion donné est susceptible de réussir ou d’échouer. La méthode est repensée sur le plan mathématique pour pénaliser les décisions excessivement complexes et pour traiter les cas rares mais importants, comme les utilisateurs difficiles à servir. En évaluant et en classant soigneusement les informations les plus pertinentes, elle ne retient que les caractéristiques les plus utiles, réduisant ainsi le temps de décision et les erreurs.
Apprendre au réseau à partager équitablement et à éviter les conflits
Une fois qu’OSIANRO a choisi un réseau ou un canal prometteur, il doit décider comment partager le spectre et la puissance entre de nombreux utilisateurs. Les auteurs construisent un modèle mathématique détaillé qui décrit combien de données les utilisateurs peuvent envoyer, comment les signaux s’interfèrent, et à quelle fréquence des collisions se produisent lorsque les utilisateurs tentent d’utiliser les ondes en même temps. Plutôt que de résoudre ce casse‑tête complexe avec des formules fixes, le système utilise l’apprentissage profond par renforcement, dans lequel de nombreux « agents » logiciels apprennent par essai‑erreur. Chaque agent représente un utilisateur qui choisit quel bloc de ressources accéder et à quelle agressivité le revendiquer. Les agents reçoivent des récompenses lorsque les débits globaux augmentent et des pénalités lorsque l’interférence ou la surcharge du canal augmente, convergeant lentement vers des stratégies qui maintiennent les collisions faibles tout en poussant le débit total à la hausse.

Performances en milieu urbain et sur autoroute
Pour tester OSIANRO, les auteurs simulent des scénarios urbains et autoroutiers réalistes en utilisant des modèles de canal bien connus et des outils open source. Ils comparent leur système à une référence avancée qui utilise un dispositif spécialisé inspiré de la mécanique quantique pour optimiser l’allocation des ressources. Dans de nombreuses expériences, OSIANRO augmente systématiquement le débit total, extrait plus d’information par unité de spectre et réduit fortement le nombre de collisions, même lorsque le nombre d’utilisateurs et leurs vitesses augmentent. La sélection de réseau améliorée par gradient boosting se révèle plus précise et plus rapide que les versions standard, tandis que le composant d’apprentissage par renforcement s’adapte en douceur aux conditions radio changeantes sans dépendre d’une connaissance parfaite a priori.
Ce que cela signifie pour la connectivité quotidienne
En termes simples, ce travail montre que donner aux réseaux sans fil la capacité de prédire et d’apprendre par eux‑mêmes peut faire en sorte que des ondes encombrées se comportent davantage comme des autoroutes bien organisées que comme des parkings chaotiques. En choisissant intelligemment quelle tour et quel canal chaque appareil doit utiliser, et en ajustant continuellement la manière dont les utilisateurs partagent le spectre, OSIANRO fournit plus de données à plus d’utilisateurs avec moins de ralentissements et de dysfonctionnements. Bien que les résultats proviennent de simulations détaillées plutôt que de déploiements réels, ils suggèrent une voie pratique vers des réseaux mobiles qui restent rapides, équitables et stables même lorsqu’ils sont saturés de voitures en mouvement, de trains et de milliards d’appareils connectés.
Citation: Lahza, H., Sreenivasa, B.R., Lahza, H. et al. Deep reinforcement learning for network resource optimization in MIMO-NOMA networks to maximize utilization with minimal overhead. Sci Rep 16, 12635 (2026). https://doi.org/10.1038/s41598-026-42953-7
Mots-clés: allocation des ressources 5G, MIMO NOMA, apprentissage profond par renforcement, optimisation des réseaux, interférence sans fil