Clear Sky Science · fr
Prédiction sélective conforme avec report conscient des coûts pour un triage clinique sûr sous changement de distribution
Pourquoi cela importe pour les patients et les cliniciens
Lorsqu’un patient en soins intensifs commence à glisser vers une septicémie, chaque heure peut faire la différence entre la vie et la mort. Les hôpitaux se tournent vers l’intelligence artificielle (IA) pour repérer rapidement ces patients à haut risque, mais la plupart des systèmes se comportent encore comme des oracles trop sûrs d’eux : ils donnent toujours une réponse, même lorsqu’ils sont incertains ou confrontés à de nouveaux types de cas. Cet article explore une autre approche : un assistant IA qui sait quand intervenir et quand renvoyer un cas aux cliniciens humains, avec l’objectif explicite de préserver la sécurité des patients même lorsque les conditions hospitalières évoluent dans le temps. 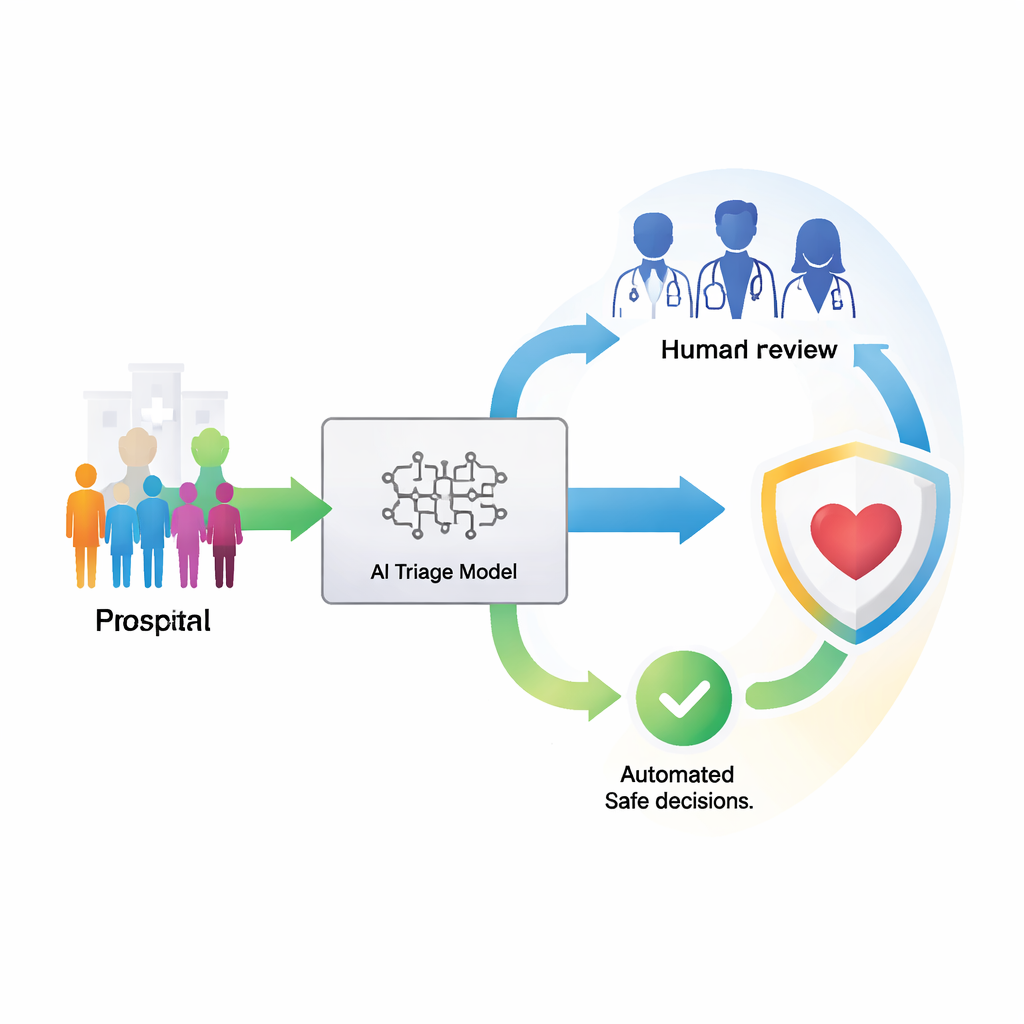
Une façon plus intelligente de dire « Je ne suis pas sûr »
Les auteurs construisent un cadre de triage pour la prédiction précoce de la septicémie qui n’oblige pas le modèle à décider pour chaque patient. Au lieu de cela, il permet au système soit de produire une prédiction soit de la déléguer à un clinicien. L’idée clé est de traiter cela comme un problème de coûts : manquer un vrai cas de septicémie est bien pire que de déclencher une alarme supplémentaire ou de demander une révision humaine. Le modèle est entraîné sur des données passées de soins intensifs puis calibré pour que ses scores de probabilité correspondent réellement à la réalité. Par-dessus cela, chaque prédiction est enveloppée dans une « coquille » d’incertitude, un petit ensemble qui contient presque toujours la véritable réponse. Le système utilise ensuite une règle unique, favorable à la transparence : si sa confiance dans le label principal tombe en dessous d’un seuil choisi, il délègue le cas à un clinicien ; sinon, il prédit.
Concevoir pour des conditions hospitalières changeantes
Une inquiétude majeure avec l’IA clinique est que les hôpitaux évoluent : les traitements, la composition des patients et les pratiques d’enregistrement changent sur des mois et des années — un modèle qui fonctionnait hier peut être moins fiable aujourd’hui. Pour étudier cela, l’étude utilise un jeu de données de soins intensifs où les patients sont séparés non seulement en ensembles de développement et de test, mais aussi en groupes « in‑distribution » (période antérieure) et « out‑of‑distribution » (période ultérieure). Le cadre construit trois variantes d’ensembles d’incertitude : une version standard, une version adaptée à des groupes démographiques séparés (ici, le genre), et une version qui ajuste explicitement les changements liés au temps dans les données. Les trois visent le même niveau nominal de fiabilité, mais les versions ajustée et aware‑du‑groupe sont conçues pour mieux résister lorsque l’environnement hospitalier dérive.
Que se passe‑t‑il quand le modèle peut déléguer
Les résultats montrent que permettre au modèle de s’abstenir sur des cas incertains améliore fortement la qualité des prédictions qu’il conserve. Dans un réglage où il fournit encore des réponses pour 80 % des patients, le taux d’erreur parmi ces cas « retenus » chute d’environ moitié par rapport à l’obligation de prédire pour tout le monde, tant dans la période initiale que sous un déplacement temporel ultérieur. Le seuil unique de confiance, ajusté sur un groupe de calibration tenu à l’écart, donne un coût clinique attendu faible sur les deux sous‑ensembles de test, et ce coût n’augmente que modérément lorsque la distribution des données change. Fait important, le modèle reste bien calibré : lorsqu’il affirme qu’un cas a une certaine probabilité de septicémie, ce chiffre correspond étroitement à ce qui est observé en réalité, ce qui est essentiel pour que les cliniciens fassent confiance à ses alertes et délégations. 
Garder l’équité et la fiabilité en vue
Parce que les outils cliniques doivent fonctionner pour tous les patients, les auteurs examinent aussi les performances selon des sous‑groupes démographiques. En construisant des ensembles d’incertitude séparés pour les patients masculins et féminins, le système égalise la fréquence à laquelle le résultat vrai se trouve dans son ensemble prédit, réduisant l’écart entre les sexes dans cette mesure de couverture à environ un point de pourcentage. Parallèlement, une version qui rééchantillonne les données passées pour imiter la composition des patients ultérieurs montre la plus faible baisse de fiabilité en passant de la cohorte antérieure à la cohorte ultérieure. Selon les méthodes, les ensembles d’incertitude restent compacts — pointant typiquement vers un seul label — de sorte que les cliniciens ne sont pas submergés par des sorties ambiguës. Au lieu de cela, les ensembles plus larges deviennent rares et servent de signaux naturels indiquant que certains cas méritent une attention humaine plus poussée.
Ce que cela signifie pour le triage en situation réelle
Pour les non‑spécialistes, la conclusion est que les auteurs ne recherchent pas seulement des scores d’exactitude plus élevés ; ils conçoivent un assistant IA qui est prudent par conception. En combinant des estimations d’incertitude honnêtes, une règle claire de délégation et un modèle de coût qui pénalise fortement les septicémies manquées, le cadre réduit les erreurs sur les patients traités automatiquement tout en maintenant un préjudice global faible, même lorsque les conditions hospitalières évoluent. L’approche intègre aussi l’équité et la surveillance dans la conception plutôt que comme une réflexion après coup. En pratique, un tel système ne remplacerait pas les cliniciens, mais ferait office de filtre centré sur la sécurité : traiter avec confiance les cas simples, signaler les cas limites pour révision humaine et fournir des commandes transparentes que les hôpitaux peuvent ajuster selon leur tolérance au risque et leurs limites de ressources.
Citation: Kwon, H., Kim, DJ. Conformal selective prediction with cost aware deferral for safe clinical triage under distribution shift. Sci Rep 16, 10016 (2026). https://doi.org/10.1038/s41598-026-40637-w
Mots-clés: triage clinique, prédiction de la septicémie, incertitude en IA, prédiction sélective, sécurité en santé