Clear Sky Science · fr
Un cadre de détection multi-échelle léger pour images radiographiques avec apprentissage contrastif supervisé
Pourquoi des contrôles aux rayons X plus intelligents sont importants
Quiconque a déjà patienté aux contrôles d’un aéroport sait que chaque bagage doit être scanné rapidement et avec précision. Pourtant, les images aux rayons X sont loin d’être simples : couteaux, bouteilles, ordinateurs portables et chargeurs s’entassent les uns sur les autres, et les objets dangereux peuvent facilement se dissimuler dans le fouillis. Cet article présente une nouvelle méthode d’intelligence artificielle (IA) qui aide les machines à rayons X à repérer de manière plus fiable les menaces petites ou chevauchantes, tout en restant suffisamment rapide pour les points de contrôle fréquentés.
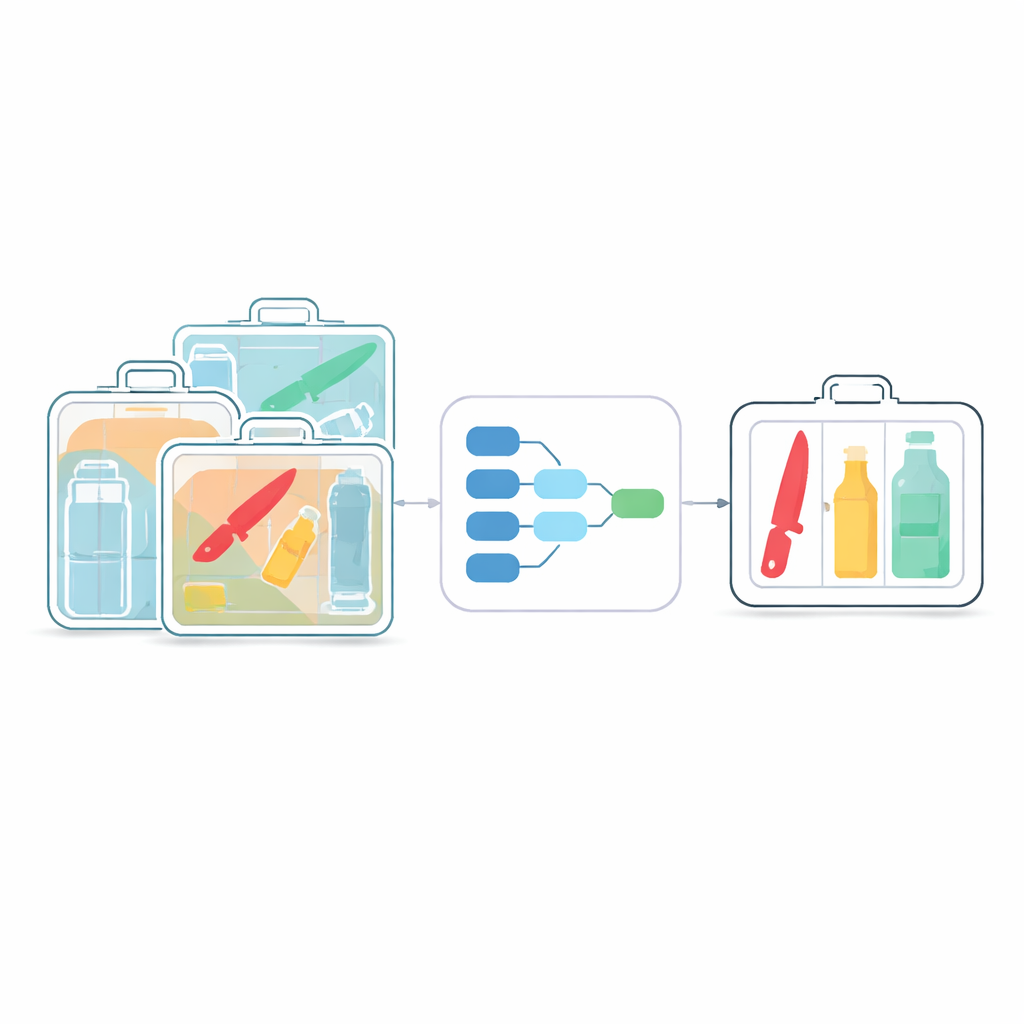
Le défi de voir à travers le désordre
Les systèmes de sécurité par rayons X constituent la première ligne de défense dans les aéroports, les stations de métro et autres espaces publics fréquentés. L’inspection humaine traditionnelle est lente et fatigante, ce qui augmente le risque d’objets manqués. Les détecteurs modernes basés sur l’IA, comme la famille YOLO, ont amélioré le contrôle automatisé, mais ils ont été conçus à l’origine pour des photos de la vie courante, pas pour les vues fantomatiques et à faible contraste des rayons X. Dans ces scans, les objets se chevauchent souvent, apparaissent semi-transparents et varient fortement en taille. De petites lames ou bouteilles peuvent être enfouies parmi des objets inoffensifs, et de nombreux algorithmes actuels les manquent ou exigent une puissance de calcul importante difficile à déployer sur des appareils compacts et peu coûteux.
Un cerveau plus léger pour les machines à rayons X
Les auteurs partent du détecteur populaire YOLOv8 et le repensent spécifiquement pour l’imagerie par rayons X. Leur première étape consiste à alléger le réseau en utilisant des convolutions « séparables en profondeur » — une manière technique de dire que le modèle analyse les motifs de façon plus économique. Plutôt que d’appliquer de larges filtres coûteux à tous les canaux de l’image simultanément, l’opération est découpée en étapes moins onéreuses. Ce changement réduit le nombre de calculs d’environ un quart à deux cinquièmes, tout en préservant les détails fins nécessaires pour repérer de petits objets partiellement cachés. Le résultat est un « cerveau » numérique plus léger qui peut fonctionner en temps réel sur du matériel modeste, comme des processeurs embarqués à l’intérieur des scanners.
Aider le modèle à se concentrer sur l’essentiel
Réduire la taille du réseau ne suffit pas ; il doit aussi être plus sélectif. À cette fin, les chercheurs introduisent un module Channel-Spatial Attention Fusion (CSAF). Une branche de ce module apprend quels types de caractéristiques visuelles — contours, formes ou indices de matériau — sont globalement les plus informatifs, tandis qu’une autre branche apprend où dans l’image se situe l’action. Plutôt que d’appliquer ces attentions l’une après l’autre, CSAF les traite en parallèle puis les fusionne, de sorte que le système peut considérer à la fois le « quoi » et le « où » simultanément. Ces unités d’attention sont intégrées dans une architecture multi-échelle qui combine des vues grossières et détaillées de la scène, ce qui est particulièrement utile pour détecter de petits objets chevauchants dans des sacs encombrés.
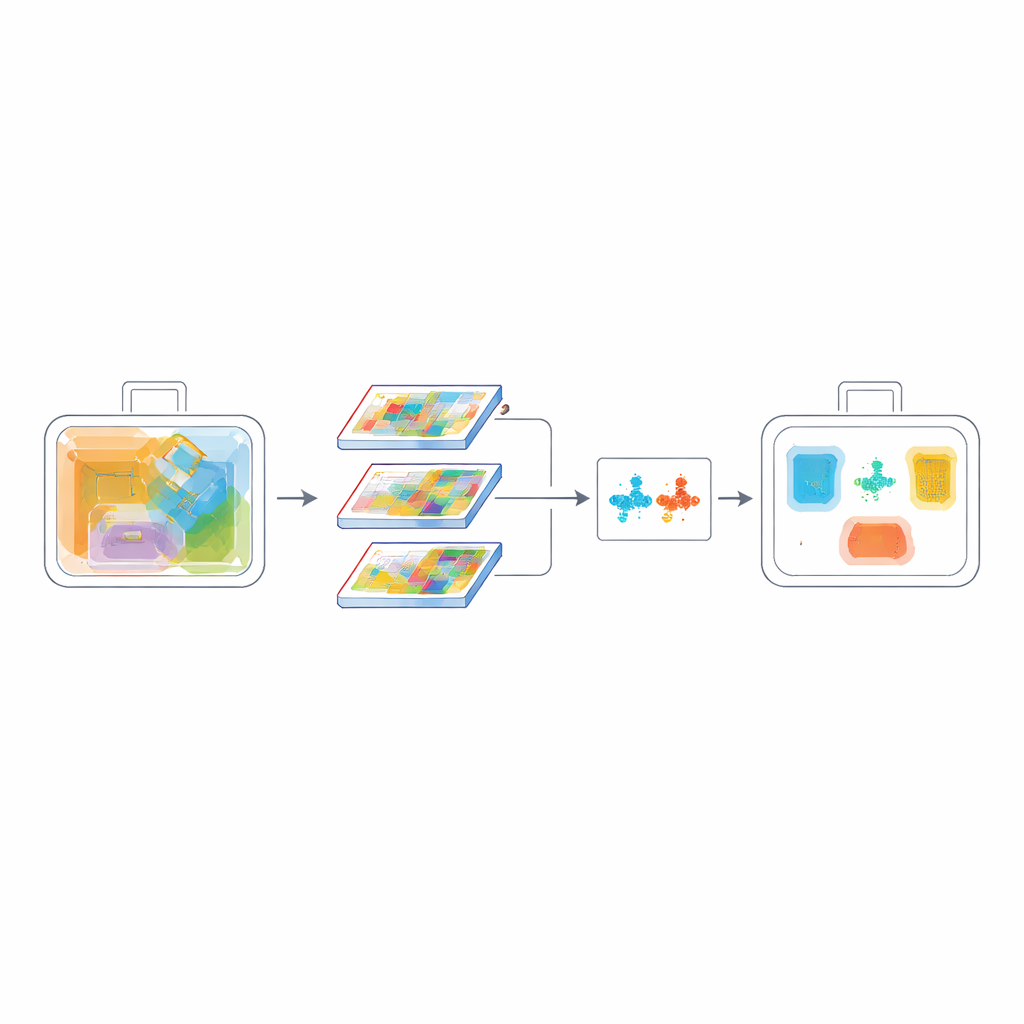
Apprendre au système à distinguer des sosies
Une autre difficulté des scans aux rayons X est que de nombreux objets se ressemblent : une boîte de conserve et un aérosol, ou différentes sortes de couteaux, peuvent partager des contours presque identiques. Pour améliorer la capacité du modèle à distinguer ces catégories, les auteurs ajoutent un objectif d’apprentissage contrastif. Pendant l’entraînement, le réseau est encouragé à rapprocher dans son espace de représentation interne les exemples de la même classe, tout en éloignant les classes différentes. Parallèlement, une mesure de recouvrement au niveau des pixels appelée PIoU aide à affiner la position et la forme des boîtes englobantes prédites, ce qui est crucial lorsque les objets sont inclinés, serrés ou partiellement visibles. Ensemble, ces fonctions de perte apprennent au modèle non seulement où se trouve un objet, mais aussi ce qui le distingue de voisins trompeurs.
Prouver les performances dans des tests réalistes
L’équipe évalue son approche sur deux jeux de données radiographiques exigeants qui incluent de vrais points de contrôle et des scènes de bagages synthétiques avec plusieurs catégories de menaces. Comparé à la référence YOLOv8 standard, leur modèle atteint une précision supérieure sur des mesures strictes de recouvrement tout en utilisant moins de paramètres et de calcul. Il maintient des taux de détection très élevés pour les objets nets et améliore la reconnaissance d’objets transparents ou déformables comme les bouteilles et les briques de boisson. Les courbes précision–confiance et rappel–confiance montrent que ses prédictions restent stables même lorsque le seuil de déclaration d’une détection est relevé, ce qui se traduit par moins de fausses alertes et moins de menaces manquées. Des tests sur un second jeu de données collecté ailleurs confirment que le système se généralise bien, une exigence importante pour le déploiement réel où le contenu des sacs et les conditions d’imagerie varient.
Ce que cela signifie pour les voyageurs quotidiens
Pour le grand public, l’essentiel est que ce travail propose une manière plus intelligente et plus légère de scanner les bagages. En repensant un détecteur IA moderne pour le rendre à la fois léger et plus discriminant, les auteurs permettent des machines à rayons X capables de fonctionner rapidement sur du matériel abordable tout en détectant les menaces petites, chevauchantes ou ressemblantes. Si de telles méthodes sont adoptées en pratique, elles pourraient aider à réduire les files d’attente, diminuer les fouilles de bagages inutiles et — surtout — accroître les chances que les objets véritablement dangereux soient interceptés avant d’atteindre la porte d’embarquement.
Citation: Diao, Q., Chan, W., Zain, A.M. et al. A lightweight multi-scale detection framework for X-ray images with supervised contrastive learning. Sci Rep 16, 8635 (2026). https://doi.org/10.1038/s41598-026-38000-0
Mots-clés: Sécurité par rayons X, détection d'objets, apprentissage profond, contrôle aéroportuaire, vision par ordinateur