Clear Sky Science · es
Un marco de aprendizaje profundo embebido para la detección de violencia en tiempo real y la generación de alertas
Por qué las cámaras más inteligentes importan para la seguridad cotidiana
Las peleas y agresiones en calles, escuelas y transporte público a menudo se desarrollan en segundos, mucho antes de que los operadores humanos puedan revisar cada pantalla de vigilancia y pedir ayuda. Este estudio presenta una manera de que pequeños ordenadores de bajo coste —dispositivos tan modestos como una placa Raspberry Pi— procesen vídeo en tiempo real y señalen automáticamente comportamientos probablemente violentos. Al compactar técnicas potentes de análisis de vídeo en un sistema eficiente y local, el trabajo muestra cómo las cámaras existentes podrían convertirse en centinelas más rápidos y fiables sin depender de centros de datos remotos ni de atención humana constante.
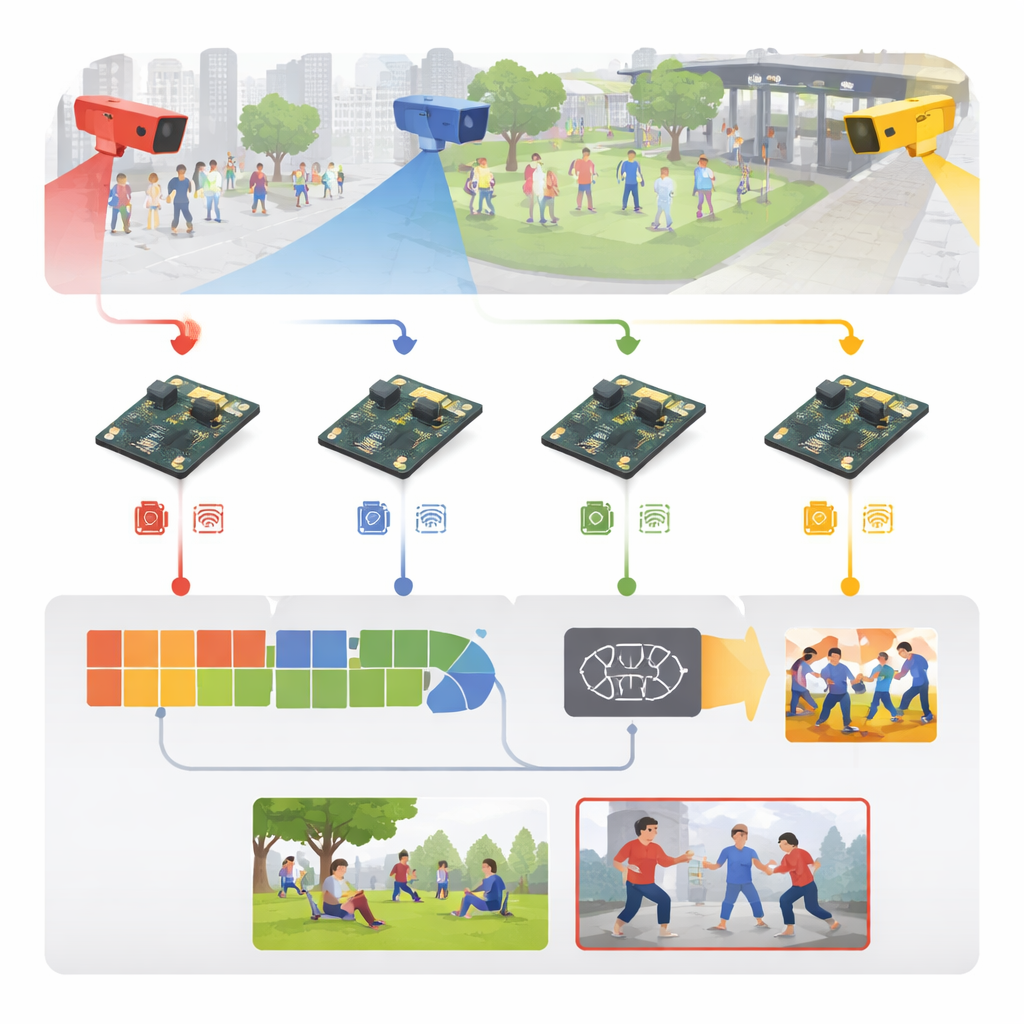
Convertir vídeo bruto en señales de aviso tempranas
El sistema parte de imágenes de vigilancia ordinarias tomadas en lugares como recintos deportivos, aceras, paseos universitarios y pasillos interiores. En lugar de transmitir todo ese vídeo a un servidor central, cada cámara envía sus fotogramas directamente a una placa embebida cercana. Allí, los fotogramas entrantes se estandarizan: se redimensionan, se limpian y se alteran levemente con volteos, rotaciones y cambios de brillo durante el entrenamiento, de modo que el modelo aprenda a lidiar con diferentes iluminaciones, puntos de vista y densidades de público. Los autores también construyen una mezcla amplia de material de entrenamiento: cinco conjuntos de datos públicos bien conocidos más una colección nueva de seis categorías que incluye puñetazos, patadas, ataques con armas, violencia en multitudes, carreras e interacción normal.
Cómo funciona el cerebro compacto dentro de la caja
En el núcleo del sistema hay un motor de aprendizaje simplificado de dos etapas. Primero, un módulo ligero de imágenes analiza cada fotograma en busca de pistas visuales reveladoras —contornos del cuerpo, posiciones de brazos y piernas y bordes de movimiento— utilizando operaciones de convolución eficientes tomadas de modelos de visión para móviles. Luego, un segundo módulo examina una breve secuencia de fotogramas para entender cómo cambian esas pistas en el tiempo, captando la diferencia entre, por ejemplo, una palmada amistosa y un puñetazo. Esto se consigue con una estructura recurrente eficiente que recuerda el movimiento reciente sin la pesada carga computacional de redes de vídeo más voluminosas. Una capa final sencilla convierte esta comprensión espacio‑temporal en una de seis etiquetas de actividad, separando el movimiento ordinario de la agresión probable.
Ajustar el aprendizaje profundo a una placa pequeña y de bajo consumo
Diseñar un modelo inteligente es solo la mitad de la historia; hacer que funcione rápido en un ordenador del tamaño de la palma de la mano es el verdadero desafío. Los autores tratan todo el sistema como una canalización de ingeniería: comienzan con una versión entrenada en una potente estación con GPU, luego la convierten a un formato portátil y la reducen agresivamente. Se disminuye la precisión numérica para que los pesos ocupen una cuarta parte de la memoria original, y se podan las partes de la red que no son necesarias. Utilizando herramientas especializadas de optimización fuera del dispositivo, generan un modelo afinado que puede ejecutarse de forma eficiente en la Raspberry Pi mediante un tiempo de ejecución optimizado. El resultado es un sistema que procesa alrededor de 26 fotogramas de vídeo por segundo con aproximadamente 38 milisegundos de retardo por fotograma, todo ello consumiendo solo unos pocos vatios: lo bastante rápido y austero para operación continua en el campo.

Pruebas, confianza y límites del juicio automático
Para evaluar si su vigilante compacto es a la vez preciso y fiable, los investigadores lo sometieron a una batería de pruebas. En colecciones de referencia que abarcan desde pistas de hockey hasta calles de ciudad, y en su propio conjunto de datos de seis clases, el sistema etiquetó correctamente los eventos en aproximadamente 97 de cada 100 casos y mostró un fuerte equilibrio entre detectar actos violentos y evitar falsas alarmas. Las comparaciones con modelos de vídeo más elaborados —como redes convolucionales 3‑D completas y diseños basados en transformadores— mostraron que este enfoque más esbelto puede igualar o superar su precisión mientras usa mucha menos computación. El equipo también visualizó dónde "mira" el modelo dentro de cada fotograma, comprobando que su atención se centra de forma natural en las extremidades en movimiento y los contactos cercanos entre personas, más que en detalles de fondo irrelevantes, lo que ayuda a generar confianza en sus decisiones.
Qué supone esto para espacios más seguros e inteligentes
El mensaje principal del estudio no es que haya inventado un tipo de red neuronal completamente nuevo, sino que ha mostrado cómo empaquetar técnicas probadas en una herramienta práctica y en tiempo real para hardware modesto. Al equilibrar con cuidado el diseño del modelo, la preparación de datos y la compresión en el momento del despliegue, los autores entregan un sistema embebido capaz de monitorizar vídeo en vivo, reconocer violencia probable y generar alertas con baja latencia y bajo consumo energético. También reconocen desafíos abiertos: el sistema aún puede fallar con mala iluminación, escenas muy concurridas o movimientos rápidos tipo deporte, y cualquier tecnología de este tipo debe desplegarse atendiendo a la privacidad, el sesgo y la supervisión humana. Aun así, el trabajo apunta a un futuro en el que muchas cámaras ordinarias vayan acompañadas de pequeños ordenadores silenciosos que ayuden a detectar el peligro antes y a facilitar respuestas más rápidas y mejor informadas.
Cita: Salman, M., Abbas, N., ur Rahman, S.I. et al. An embedded deep learning framework for real-time violence detection and alert generation. Sci Rep 16, 10805 (2026). https://doi.org/10.1038/s41598-026-44939-x
Palabras clave: detección de violencia, visión embebida, IA en el borde, vigilancia por vídeo, aprendizaje profundo