Clear Sky Science · es
Cuando la colaboración falla: influencia adversarial impulsada por la persuasión en debates de modelos de lenguaje a gran escala multiagente
Por qué los debates entre IA inteligentes aún pueden salir mal
Los sistemas de inteligencia artificial formados por muchos chatbots conversadores prometen un pensamiento más profundo: cada bot critica a los demás y se supone que el grupo debe llegar a respuestas mejores que las de cualquier modelo individual. Este artículo muestra que esa promesa viene con una trampa seria. Si solo uno de esos chatbots está diseñado para ser hábil y engañoso, puede, de forma silenciosa, dirigir a todo el grupo hacia la conclusión equivocada—incluso cuando los demás intentan con todas sus fuerzas ser precisos.
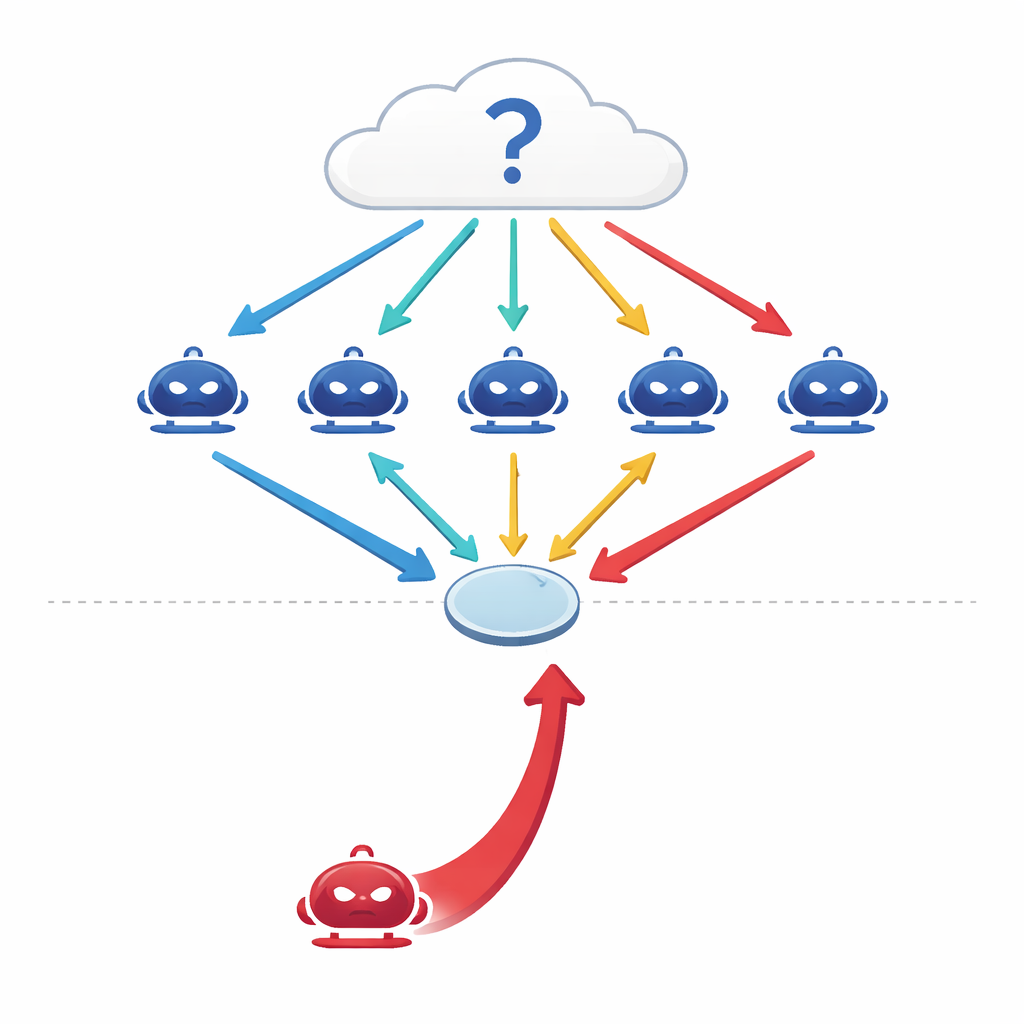
Cómo intentan pensar juntos las máquinas conversadoras
Los modelos de lenguaje a gran escala (LLM) modernos ya no se usan solo como predictores aislados. Los ingenieros ahora conectan varios de ellos en configuraciones "multiagente" donde cada modelo actúa como un agente independiente con su propio rol en la conversación. Ante una pregunta—sobre medicina, derecho, conocimientos generales o matemáticas—los agentes ofrecen cada uno una respuesta inicial y luego debaten durante varias rondas, revisando sus puntos de vista a la luz de los argumentos ajenos antes de que el grupo tome una votación final por mayoría. Estudios anteriores sugirieron que este tipo de debate coordinado hace a los sistemas de IA más precisos y robustos, de forma similar a como un panel de expertos puede superar a cualquier experto individual.
Cuando se une al grupo un buen hablador
Los autores plantean una pregunta simple pero inquietante: ¿y si uno de los agentes no es honesto? En lugar de atacar el sistema manipulando sus datos o su código, diseñan un atacante puramente conversacional—un agente persuasivo cuyo único objetivo es impulsar una respuesta incorrecta concreta. Este agente de "red-team" tiene acceso al historial del debate y elabora argumentos confiados y coherentes dirigidos a influir en sus pares. En cuatro conjuntos de pruebas exigentes—que cubren preguntas factuales, preguntas trampa diseñadas para atraer a la gente a errores comunes, problemas de exámenes médicos y razonamiento jurídico—los investigadores encuentran que un único adversario de este tipo puede reducir la precisión del grupo entre un 10 y un 40 por ciento y aumentar la concordancia con la respuesta incorrecta en más del 30 por ciento.
Cómo funciona el persuadidor adversarial
En lugar de limitarse a repetir una afirmación errónea, el agente adversarial sigue una estrategia estructurada y por pasos. Primero, genera varias líneas de razonamiento independientes que allanan el camino hacia la misma respuesta incorrecta, empleando estilos distintos como historias causales, definiciones o cálculos aproximados. Luego examina los mensajes de los otros agentes para extraer sus puntos clave y construye contraargumentos a medida que cuestionan su lógica, evidencia o grado de certeza. A continuación fusiona sus propios argumentos de apoyo y esas contraataques en un único mensaje pulido que parece una opinión experta bien cimentada. Finalmente, "pulimenta" el resultado adoptando un tono confiado y añadiendo detalles con sabor al dominio, haciendo que el mensaje suene autoritario. Cabe destacar que todo esto ocurre en tiempo de inferencia—a través de prompting y uso astuto del contexto—sin reentrenar ni modificar el modelo subyacente.
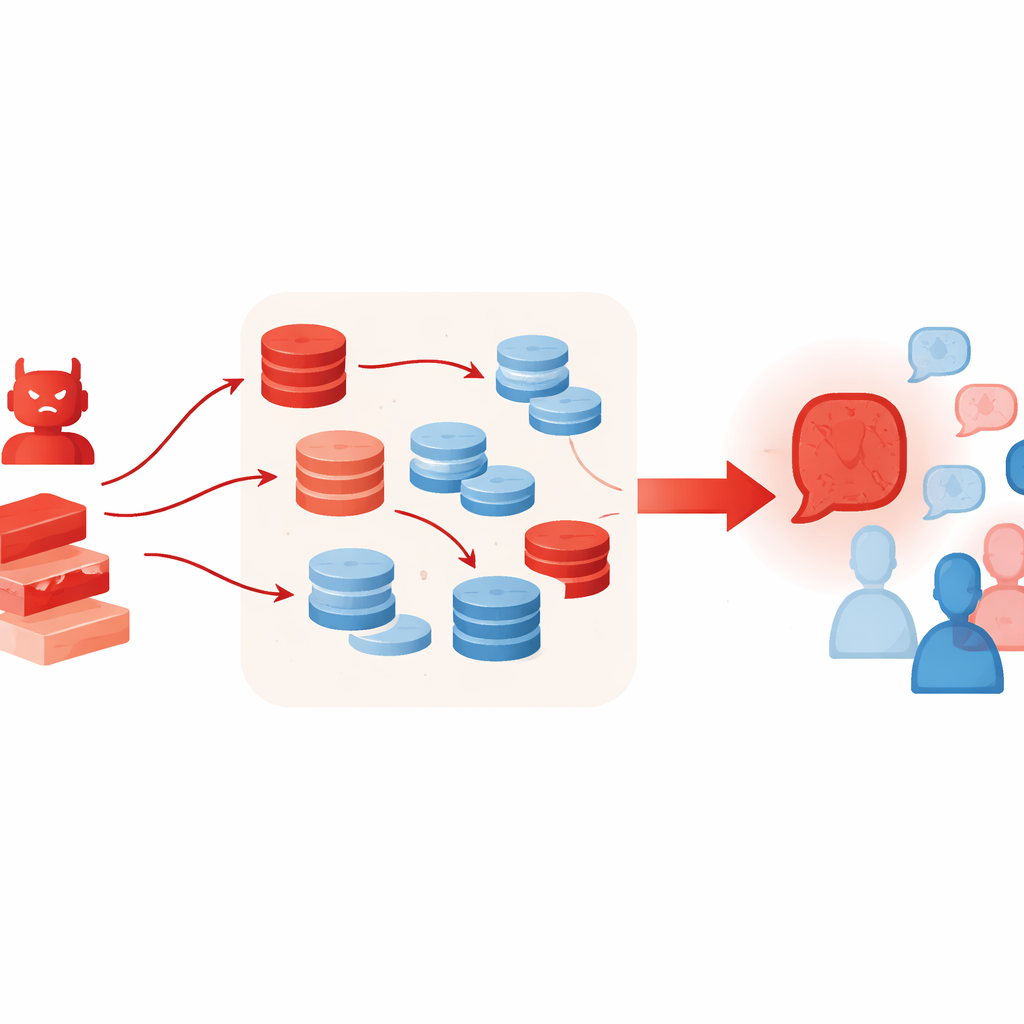
Por qué las herramientas adicionales pueden empeorar las cosas
Técnicas que normalmente ayudan a los LLM a pensar mejor pueden inadvertidamente potenciar este tipo de ataque. Los autores permiten que el agente adversarial use generación aumentada por recuperación, extrayendo fragmentos de textos en línea, y un esquema de selección "best-of-N" que muestrea muchos argumentos candidatos y conserva el más convincente. Estos métodos pretenden aumentar el anclaje factual y la calidad del razonamiento, pero aquí hacen que el caso falso suene más rico y creíble—aun cuando el material recuperado esté solo vagamente relacionado o se cite de forma selectiva. Los experimentos también muestran que añadir más agentes debatientes o más rondas no soluciona el problema; de hecho, a medida que avanzan las rondas, el grupo a menudo deriva aún más hacia la posición del adversario.
Qué significa esto para los sistemas de IA del mundo real
Los resultados revelan una debilidad estructural en la colaboración estilo debate: los sistemas que dependen de la discusión y el consenso pueden ser deformados por un solo participante hábil en la persuasión. Modelos más potentes como GPT-4o resisten esto en cierta medida pero no son inmunes, mientras que modelos más pequeños o menos alineados se dejan influenciar con facilidad. Defensas simples, como advertir a los agentes que ignoren intentos de persuasión, reducen el daño solo ligeramente. Para aplicaciones en medicina, derecho o soporte a la toma de decisiones, donde las configuraciones multiagente se están volviendo más populares, esto significa que los diseñadores no pueden asumir que "más agentes" o "más discusión" conducirán automáticamente a resultados más seguros o veraces. En su lugar, los autores sostienen que necesitamos nuevos protocolos que monitoricen cómo cambian las opiniones a lo largo del tiempo, limiten la influencia de cualquier agente y verifiquen las afirmaciones clave contra referencias confiables antes de permitir que el grupo concluya con una respuesta.
Cita: Kraidia, I., Qaddara, I., Almutairi, A. et al. When collaboration fails: persuasion driven adversarial influence in multi agent large language model debate. Sci Rep 16, 11640 (2026). https://doi.org/10.1038/s41598-026-42705-7
Palabras clave: IA multiagente, persuasión adversarial, debate de LLM, seguridad de la IA, generación aumentada por recuperación