Clear Sky Science · en
Retentive Network promotes efficient RNA language modeling of long sequences
Teaching Computers to Read Life’s RNA Messages
Every cell in your body is full of RNA, the molecule that helps turn genetic instructions into living matter. But today’s biologists face a flood of RNA data that no human can read line by line. This paper introduces RNAret, a compact artificial intelligence model that "reads" RNA sequences much like language and can handle extremely long stretches of genetic text. Its goal is to uncover hidden patterns that reveal how RNAs fold, interact, and distinguish working blueprints from background noise — all while using far less computing power than current tools.
A New Way to See Patterns in RNA
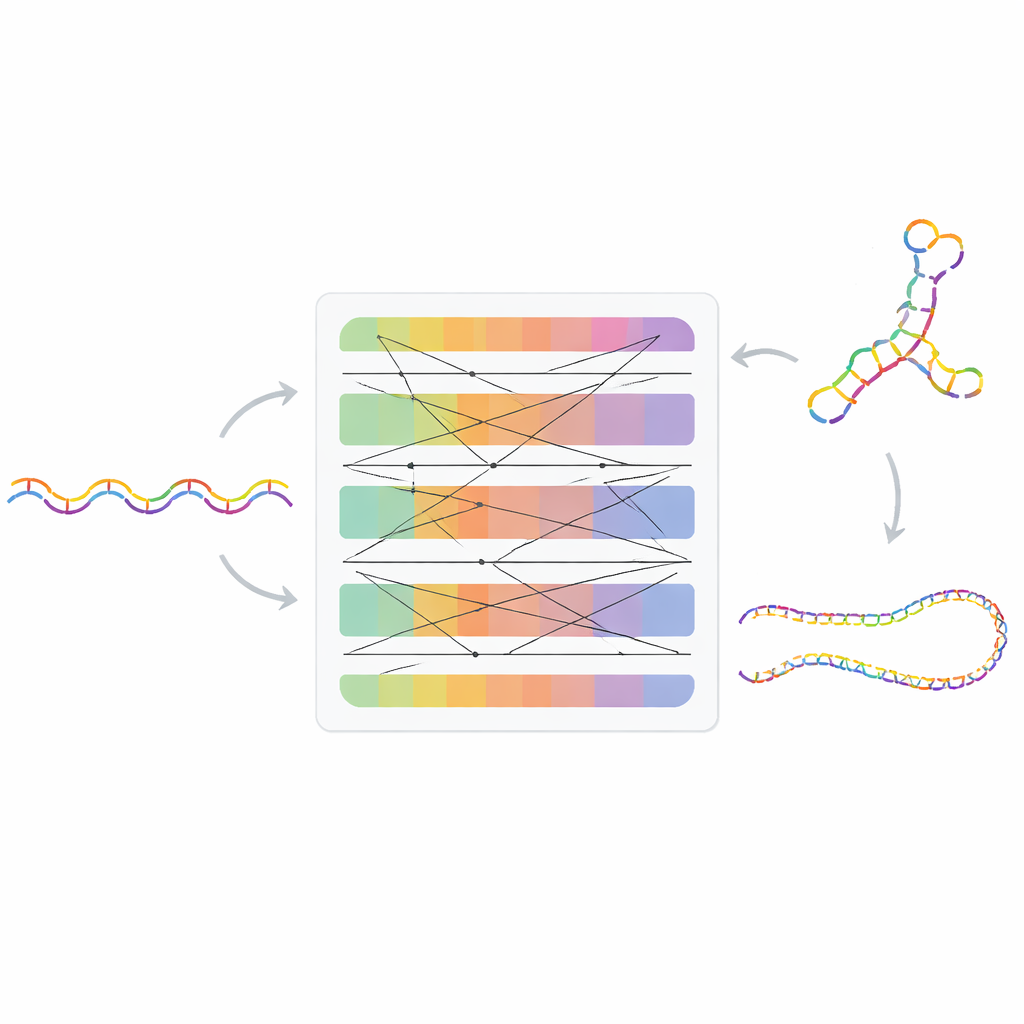
RNAret is built on an emerging AI design called a Retentive Network, originally proposed as a successor to Transformers, the engines behind large language models for human text. Instead of comparing every position in a sequence with every other one — a step that becomes very expensive for long strings — the Retentive approach lets the model “retain” important information as it moves along, with a cost that grows only in direct proportion to sequence length. The authors adapt this idea into an encoder that looks in both directions along the RNA, creating a lightweight model with about 12 million parameters that can still process thousands of RNA letters at once on a standard research GPU.
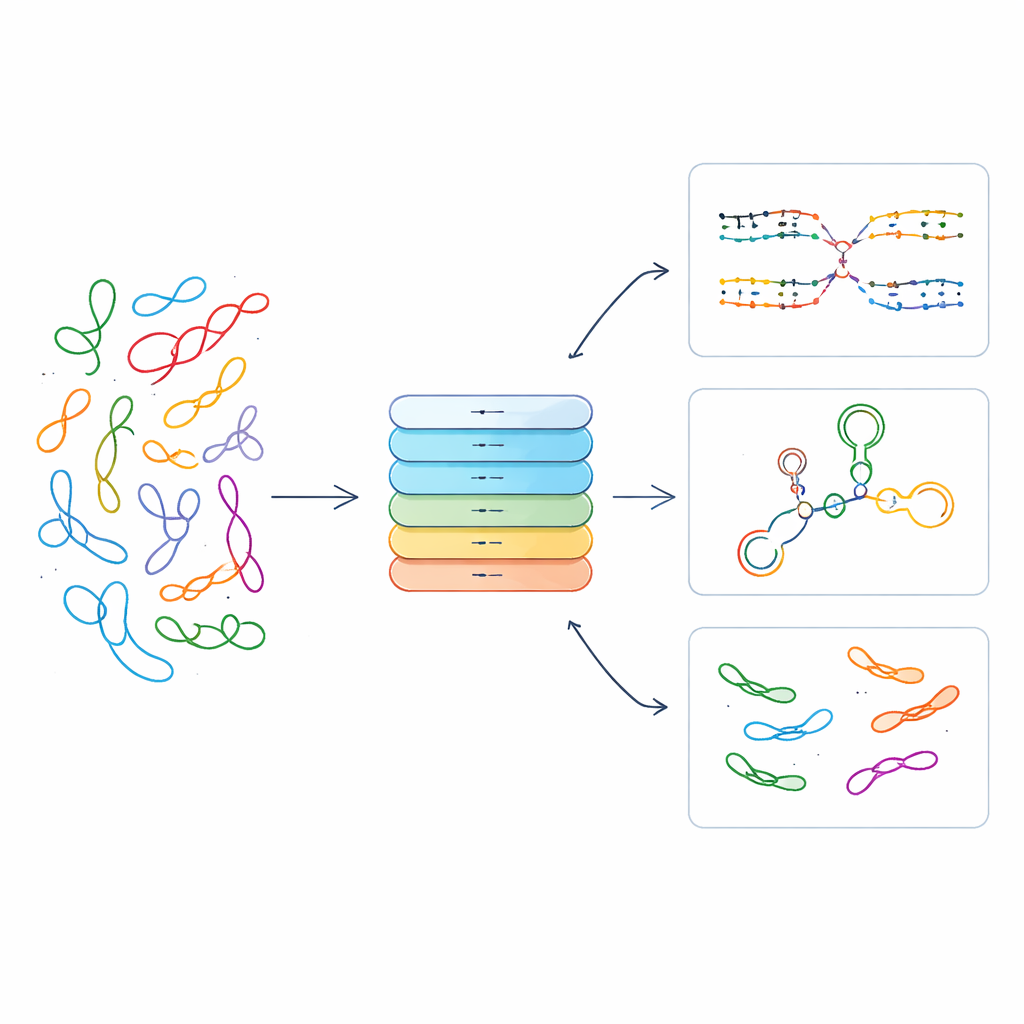
Learning from Millions of Unlabeled RNA Sequences
To teach RNAret the “grammar” of RNA, the team trained it on nearly 30 million non-coding RNA sequences from the RNAcentral database, without providing any labels about RNA type or function. They used a strategy borrowed from language modeling: hide small chunks of the sequence and ask the model to guess the missing pieces. Over 600,000 training steps, RNAret steadily learned to predict these masked segments, indicating it was capturing regularities in how bases are arranged. When the researchers later looked at the internal representations produced by the model, they found that RNAs with similar roles and lengths naturally clustered together in low-dimensional space, even though the model had never been told which sequences belonged to which category.
Putting the Model to Work on Real Biological Questions
The authors then tested whether these learned RNA patterns help solve practical problems. First, RNAret was fine-tuned to judge whether a short regulatory RNA called a microRNA can bind to a target region on a longer RNA molecule. On a standard benchmark of over 27,000 microRNA–mRNA pairs, the version of RNAret that reads five-letter chunks of sequence outperformed several larger RNA language models and a specialized deep-learning tool, reaching high accuracy and F1 scores. When the researchers inspected the model’s internal “retention scores,” they saw that it naturally focused on the microRNA “seed” region — the key stretch known from experiments to drive binding — and the matching section on the target RNA, indicating that the model’s decisions were grounded in real biology rather than spurious shortcuts.
Reconstructing Shapes and Sorting RNA Types
Next, the team challenged RNAret to predict how single RNA strands fold back on themselves into secondary structures. Using cleaned benchmark datasets, the simplest version of RNAret (reading one base at a time) produced contact maps of base pairs that were often closer to the experimentally known structures than popular deep-learning and thermodynamic tools, especially for moderate-length RNAs. The model’s outputs, combined with a post-processing step that enforces physical rules about which bases can pair, yielded cleaner, less noisy predictions. In a third test, RNAret learned to distinguish protein-coding RNAs from long non-coding RNAs in human and mouse genomes. Because it can process full-length transcripts without chopping them up, it handled partial and long sequences well, surpassing classical open-reading-frame methods and most competing RNA language models, particularly on the large human dataset.
Fast, Efficient, and Ready to Grow
Beyond accuracy, RNAret was designed to be fast. Thanks to its retention-based architecture, the model processes on the order of one hundred thousand RNA units per second during pretraining on a single high-end GPU, and it remains efficient even when fine-tuned for structure prediction or classification. Despite being much smaller than many recent biological language models, it achieves state-of-the-art or near–state-of-the-art performance on diverse tasks. The authors see this as a proof of concept that Retentive Networks can serve as practical, interpretable engines for biological sequence analysis. With further tuning and extensions to DNA and protein, RNAret and related models could become everyday tools for turning raw sequence data into insight about how molecules interact, fold, and carry out the instructions of life.
Citation: Shen, Y., Cao, G., Hu, Y. et al. Retentive Network promotes efficient RNA language modeling of long sequences. Commun Biol 9, 575 (2026). https://doi.org/10.1038/s42003-026-09757-x
Keywords: RNA language model, Retentive Network, RNA structure prediction, microRNA interactions, long noncoding RNA