Clear Sky Science · en
DupyliCate: mining, classifying, and characterizing gene duplications
Why extra gene copies matter
Every living thing carries thousands of genes, but many of these genes are not unique. Over time, DNA segments can be copied, leaving organisms with spare versions that evolution can tinker with. These extra gene copies help plants adapt to stress, shape new traits like flower color or flavor, and even influence how microbes respond to their environments. This study introduces DupyliCate, a computer tool designed to track down and sort these gene copies across many species, helping researchers uncover how genomes change and how new biological features arise.
Finding gene copies in a sea of DNA
Modern genomes are vast and messy. Extra gene copies can sit side by side, be scattered across chromosomes, or be left over from ancient doubling of entire genomes. Older tools often focused on pairs of related genes or were tailored to very specific data formats, which limited what scientists could learn. DupyliCate tackles these problems by scanning whole genomes and clustering related genes into arrays, not just pairs. It is built to handle many flavors of genome annotation files and can work across plants, microbes, and animals. By grouping genes into tandem, nearby, and scattered duplicates, it gives a clearer picture of how copying has shaped each genome.
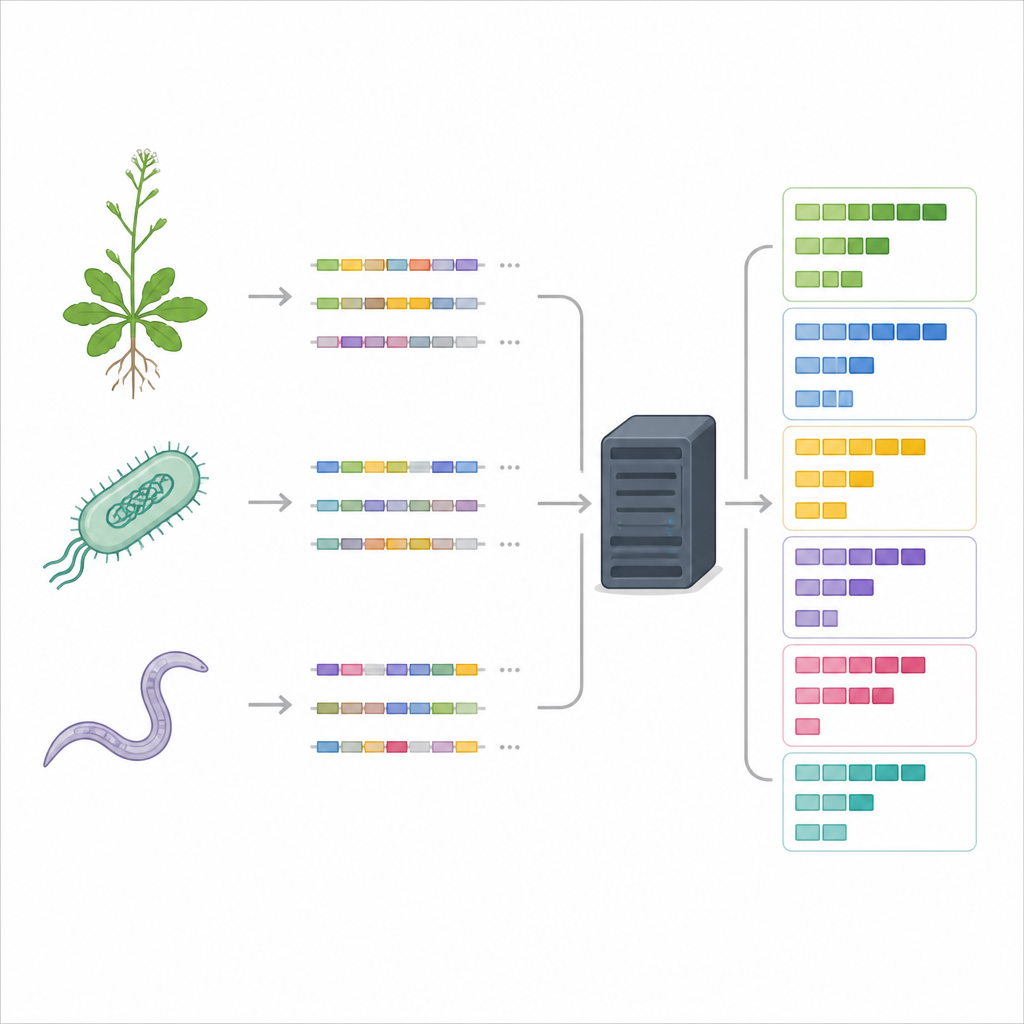
Letting each species set its own rules
One challenge in finding true gene copies is deciding where to draw the line between a lone gene and a duplicated one. DupyliCate uses a quality control step based on conserved core genes, known as BUSCO genes, to set species-specific cutoffs. It measures how strongly each gene matches its closest partners and uses these values to split genes into “singletons” and duplicates in a way that reflects each species’ own history of duplication. The tool also creates a “duplication landscape” plot that shows how common gene copies are across the genome, revealing patterns such as low-duplication bacteria, moderately duplicated model plants, or species that have recently multiplied their entire genome.
Checking accuracy with real biological stories
To show that DupyliCate works in practice, the authors applied it to well-studied examples from plant biology. The tool correctly detected known tandem repeats of key genes, such as a SEC10 gene in one Arabidopsis variety and a cluster controlling crocin pigment production in gardenia. It also identified gene expansions linked to nematode resistance in sugar beet and withanolide production in a medicinal plant, grouping related genes into biologically meaningful clusters. Beyond plants, it found relatively few duplicated genes in bacteria and yeast, but many more in the worm Caenorhabditis elegans, matching previous knowledge about their genomes.
Tracing the history of plant pigments
DupyliCate is not just about counting gene copies; it helps explore how gene families evolve. The authors used it in two case studies on plant pigments called flavonols, which protect plants from stresses like ultraviolet light. In one, they traced the history of flavonol synthase genes across members of the mustard family and their relatives. They found that one key functional copy is shared widely, while other copies have expanded, shrunk, or become pseudogenes in different lineages. In a second large survey of 153 plant genomes, they followed two transcription factors, MYB12 and MYB111, which regulate flavonol production. These regulators were absent from algae and most early land plants, but had diversified in many flowering plants, shedding light on how complex control systems for plant chemistry emerged.
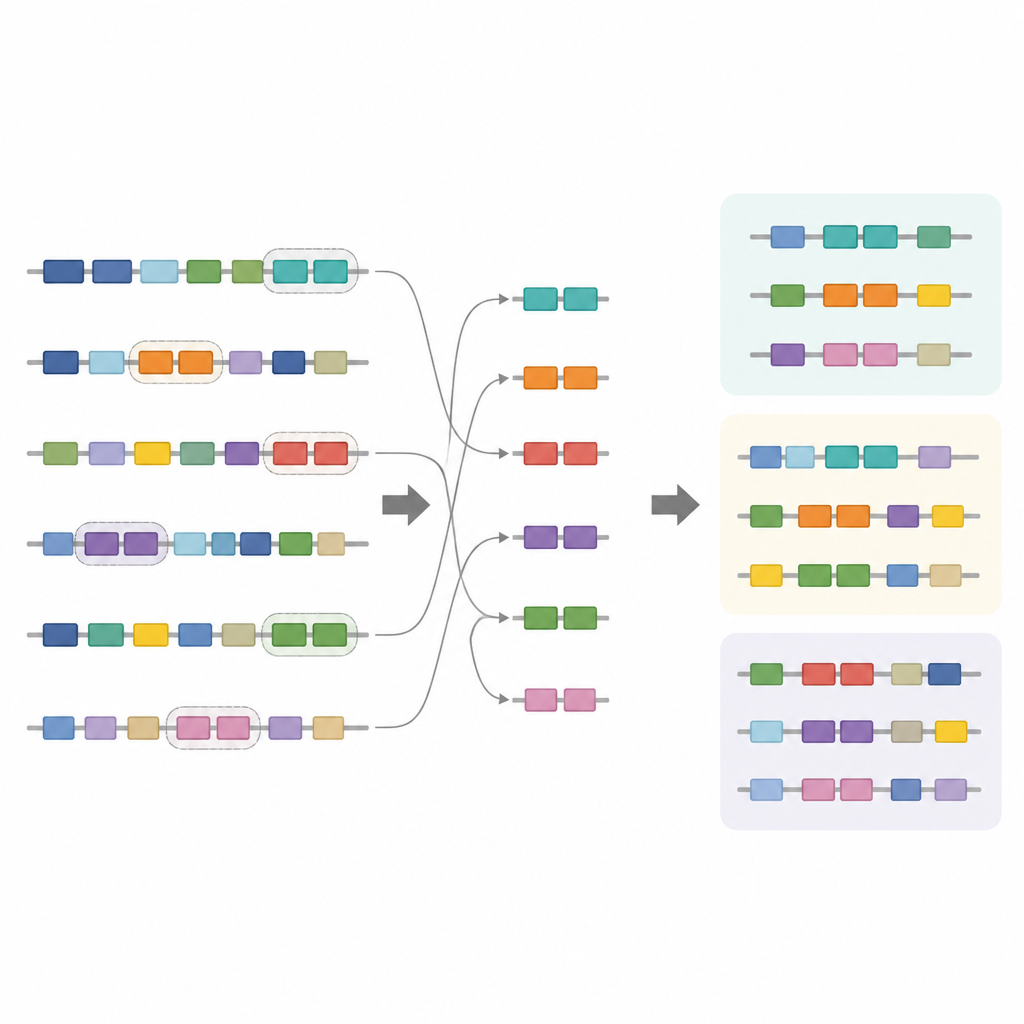
From raw sequences to functional insights
DupyliCate brings several kinds of evidence together in a single pipeline. It cleans and standardizes genome files, aligns protein sequences within and across species, clusters duplicates into meaningful groups, and can optionally add measures of evolutionary pressure as well as gene expression patterns. By comparing how strongly duplicate genes are expressed and where they appear in family trees, the tool helps distinguish likely new functions, shared functions, or loss of function. Its design emphasizes flexible parameters, clear confidence scores, and support for both single-species and multi-species studies.
What this means for future genome studies
In everyday language, this work shows how to turn raw DNA lists into stories about how organisms gained new abilities. By automatically finding and classifying extra gene copies across many genomes, DupyliCate offers researchers a way to connect specific traits, such as stress tolerance or pigment production, to past copying events in DNA. Because it handles many data types and can scale from small microbial genomes to large collections of plant species, it is likely to become a useful part of the toolkit for studying evolution, agriculture, and biodiversity.
Citation: Natarajan, S., Pucker, B. DupyliCate: mining, classifying, and characterizing gene duplications. Sci Rep 16, 16557 (2026). https://doi.org/10.1038/s41598-026-55350-x
Keywords: gene duplication, comparative genomics, plant evolution, bioinformatics tools, genome analysis