Clear Sky Science · en
A study for potential rapid discrimination of smokeless powders by near-infrared spectroscopy and chemometric modeling methods for forensic application
Why this study matters to public safety
Smokeless powder is the fuel inside most bullets, and it also turns up in homemade guns and improvised bombs. When investigators find loose powder at a crime scene, being able to tell which factory it came from can help link cases, trace supply routes, and rule suspects in or out. This study explores a quicker, cleaner way to tell similar-looking powders apart, using invisible light and computer pattern recognition instead of slow chemical lab work.
Looking closely at look-alike powders
To a casual observer, many smokeless powders appear nearly identical: small grains or flakes that differ only slightly in color, size, or shape. Yet their recipes vary from maker to maker and from one cartridge type to another. The researchers collected powders from 79 cartridges produced by 20 manufacturers in China, covering a wide mix of pistol, rifle, and nail-gun ammunition. Rather than dissolving or burning the samples, they gently removed the powder from each cartridge and allowed it to settle at room temperature before testing, keeping the material intact for possible later use.

Reading hidden fingerprints in near infrared light
The team analyzed the powders with near-infrared spectroscopy, a method that shines light just beyond the red end of the visible spectrum and records how much is absorbed at different wavelengths. This kind of light interacts with rapid vibrations in chemical bonds, producing broad, overlapping features rather than sharp lines. In these smokeless powders, the main signals came from ingredients based on nitrocellulose and related compounds, which showed up as wide peaks linked to oxygen–hydrogen and carbon–hydrogen vibrations. At first glance, the spectra from different manufacturers looked very similar and carried only subtle differences, suggesting that simple visual comparison would not be enough to sort them reliably.
Why traditional statistics were not enough
To understand how challenging the task was, the researchers examined the overall spread of their data. Most powders absorbed light within a narrow range, and similarity scores between manufacturers were often very high. Only a few makers showed clearly distinct patterns. They also faced a strong imbalance in sample numbers: some manufacturers supplied many cartridges, while others were represented by only a few. When the team used common tools such as basic descriptive statistics and a method called UMAP, which compresses complex data into a two-dimensional map, clusters for many manufacturers overlapped. Standard machine learning models that rely on simple boundaries in this compressed space struggled to separate the powders and achieved less than 60 percent accuracy.
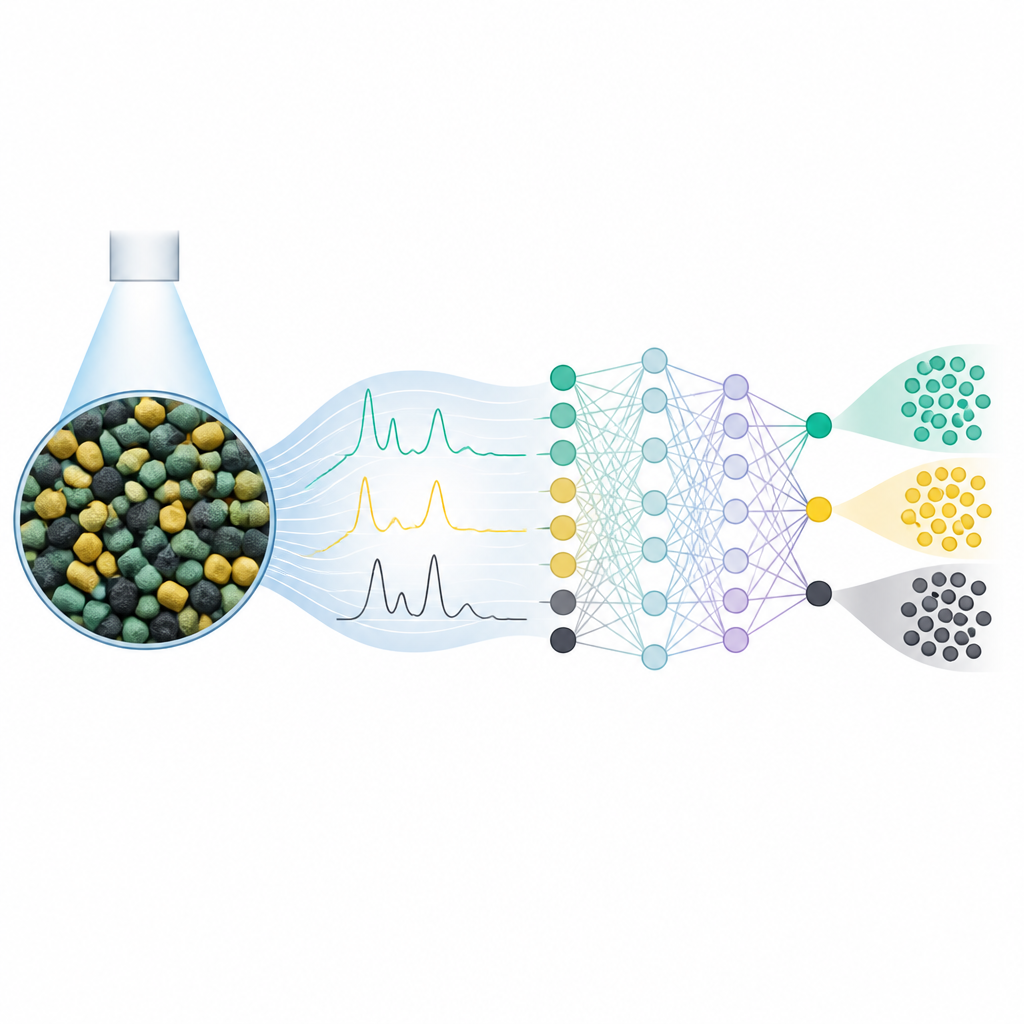
Letting a neural network find subtle patterns
To tackle these hidden differences, the authors turned to a deep learning neural network, a type of computer model that can learn layered patterns in large sets of numbers. They fed the raw near-infrared spectra into this network and trained it to predict which manufacturer had made each powder. The model architecture and its settings were tuned by systematic searches, and the data were split into training and validation sets with cross-checking to limit overfitting. In direct comparisons, the neural network outperformed four common algorithms, as well as more classical chemometric methods, lifting the average prediction accuracy to above 80 percent across the 20 manufacturers.
Understanding what the model is really using
Because black-box models can be hard to trust in forensic settings, the team examined which parts of the spectra most influenced the neural network’s decisions. Using a tool called SHAP, they found that specific near-infrared bands, especially in the ranges around 6700 to 7100 and 5700 to 6000 inverse centimeters, carried the most weight. These regions match known vibrational features of key chemical groups in the powders. This match suggests that the model was not latching onto random noise, but was instead drawing on chemically meaningful differences between formulations that are too subtle to see by eye.
What this means for future crime labs
The study shows that near-infrared spectroscopy, paired with modern deep learning, can rapidly sort smokeless powders by source with much higher accuracy than several traditional approaches, and without destroying the evidence or using extra chemicals. The authors caution that their tests focused on intact powder from cartridges and on a dataset with some imbalances, so further work on fired residues, larger collections, and improved data handling is still needed. Even so, their results point toward a practical screening tool that could help forensic scientists quickly narrow down where a suspicious powder came from, while more detailed and slower laboratory methods handle the final confirmation.
Citation: Guo, H., Shi, H., Feng, Y. et al. A study for potential rapid discrimination of smokeless powders by near-infrared spectroscopy and chemometric modeling methods for forensic application. Sci Rep 16, 15981 (2026). https://doi.org/10.1038/s41598-026-45433-0
Keywords: smokeless powder, forensic analysis, near infrared spectroscopy, neural network, ammunition