Clear Sky Science · en
An embedded deep learning framework for real-time violence detection and alert generation
Why smarter cameras matter for everyday safety
Fights and assaults in streets, schools, and public transport often unfold in seconds, long before human operators can scan every surveillance screen and call for help. This study introduces a way for small, low‑cost computers—devices as modest as a Raspberry Pi board—to watch video in real time and automatically flag likely violent behavior. By squeezing powerful video‑analysis techniques into an efficient, on‑device system, the work shows how existing cameras could become quicker, more reliable sentinels without relying on distant data centers or constant human attention.
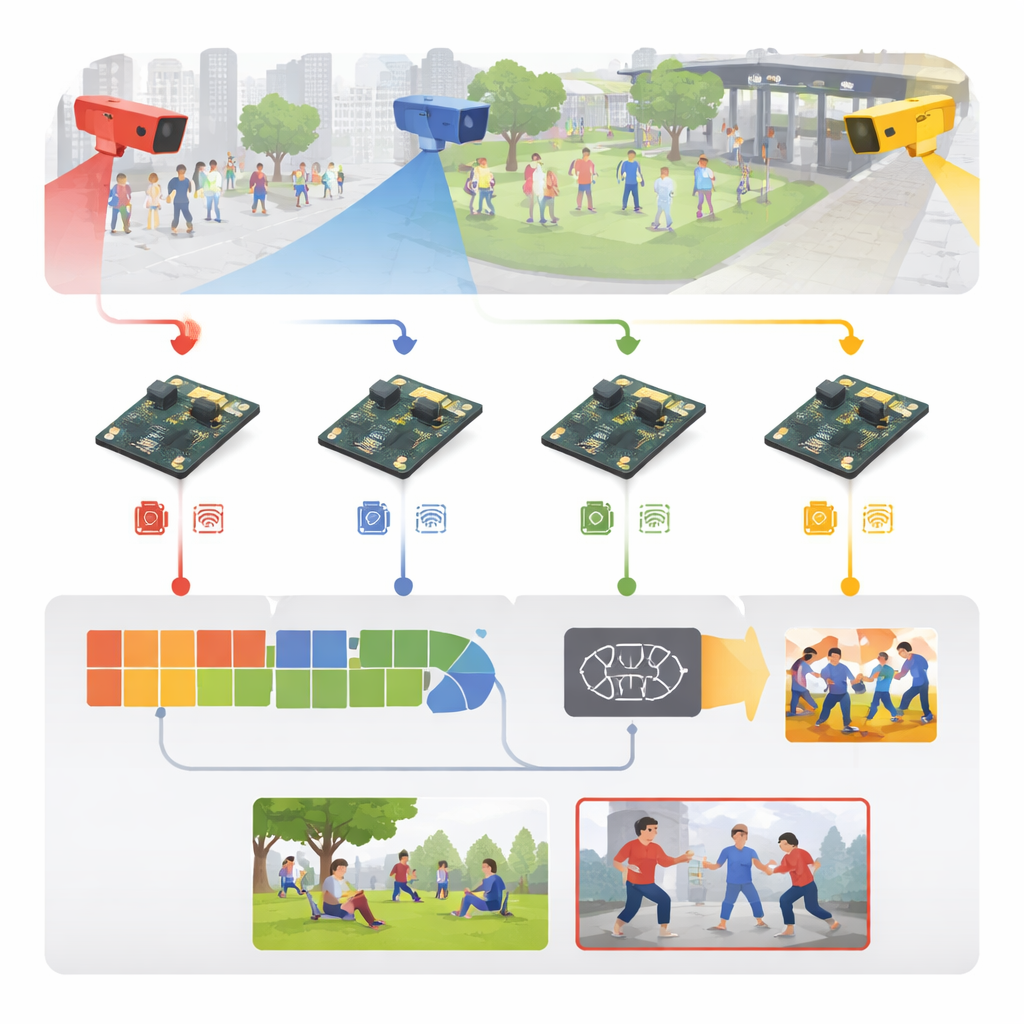
Turning raw video into early warning signals
The system starts with ordinary surveillance footage from places like sports arenas, sidewalks, campus walkways, and indoor corridors. Instead of streaming all this video to a central server, each camera sends its frames directly to a nearby embedded board. There, incoming frames are standardized—resized, cleaned, and lightly altered with flips, rotations, and brightness changes during training—so that the model learns to cope with different lighting, viewpoints, and crowd densities. The authors also build a rich mix of training material: five well‑known public datasets plus a new six‑category collection that includes punching, kicking, weapon‑related attacks, crowd violence, running, and normal interaction.
How the compact brain inside the box works
At the heart of the system is a streamlined two‑stage learning engine. First, a lightweight image module scans each frame for telling visual cues—body outlines, arm and leg positions, and motion edges—using cost‑saving convolution operations borrowed from mobile‑phone vision models. Then a second module looks across a short sequence of frames to understand how those cues change over time, capturing the difference between, say, a friendly tap and a punch. This is done with an efficient recurrent structure that remembers recent motion without the heavy computing load of bulkier video networks. A simple final layer turns this spatio‑temporal understanding into one of six activity labels, separating ordinary movement from likely aggression.
Fitting deep learning into a small, low‑power board
Designing a clever model is only half the story; making it run fast on a palm‑sized computer is the real challenge. The authors treat the entire system like an engineering pipeline: they start with a version trained on a powerful graphics workstation, then convert it into a portable format and shrink it aggressively. Numerical precision is reduced so that weights occupy a quarter of the original memory, and unneeded parts of the network are pruned away. Using specialized optimization tools off‑device, they generate a tuned model that can be executed efficiently on the Raspberry Pi using an optimized runtime. The result is a system that processes about 26 video frames per second with roughly 38 milliseconds of delay per frame, all while drawing only a few watts—fast and frugal enough for continuous operation in the field.

Testing, trust, and limits of machine judgment
To see whether their compact watcher is both accurate and dependable, the researchers put it through a battery of tests. Across benchmark collections from hockey rinks to city streets, and on their own six‑class dataset, the system correctly labeled events in roughly 97 out of 100 cases and showed strong balance between catching violent acts and avoiding false alarms. Comparisons with more elaborate video models—such as full 3‑D convolutional networks and transformer‑based designs—showed that this leaner approach can match or beat their accuracy while using far less computation. The team also visualized where the model “looks” inside each frame, finding that its attention naturally centers on moving limbs and close contacts between people, rather than irrelevant background details, which helps build confidence in its decisions.
What this means for safer, smarter spaces
The study’s main message is not that it has invented a brand‑new kind of neural network, but that it has shown how to package proven techniques into a practical, real‑time tool for modest hardware. By carefully balancing model design, data preparation, and deployment‑time compression, the authors deliver an embedded system that can monitor live video, recognize likely violence, and raise alerts with low delay and low energy use. They also acknowledge open challenges: the system can still be tripped up by poor lighting, crowded scenes, or fast sports‑like motion, and any such technology must be deployed with attention to privacy, bias, and human oversight. Even so, the work points toward a future in which many ordinary cameras are paired with small, quiet computers that help spot danger sooner and support quicker, better‑informed responses.
Citation: Salman, M., Abbas, N., ur Rahman, S.I. et al. An embedded deep learning framework for real-time violence detection and alert generation. Sci Rep 16, 10805 (2026). https://doi.org/10.1038/s41598-026-44939-x
Keywords: violence detection, embedded vision, edge AI, video surveillance, deep learning