Clear Sky Science · en
Implicit voice learning through discrimination outperforms explicit listen-and-memorize tasks
Why remembering voices matters
We recognize friends and family on the phone almost instantly, yet many people struggle to remember unfamiliar voices, especially when they hear many at once or in poor audio quality. This ability is not just a social convenience: in law enforcement, courts, and security work, people are increasingly asked to pick out specific speakers from large piles of recordings. This study asks a deceptively simple question with big real‑world consequences: do we learn new voices better when we try very hard to memorize them, or when we focus on carefully telling voices apart without realizing we are learning them?
Two ways of getting to know a voice
The researchers contrasted two everyday‑like paths to voice familiarity. In one, people were told exactly what to do: listen closely and memorize several voices so they could recognize them later. This mirrors classic lab tests in which volunteers study a small set of recordings and are later asked, “Have you heard this person before?” In the other path, learning was never mentioned. Instead, participants took part in a same–different task: on each trial they heard two very short speech clips and simply had to judge whether they came from the same person or from two different people. Unknown to them, this repeated comparing of voices was also a learning opportunity. After each type of exposure, everyone completed a surprise test in which they heard single clips and had to decide whether each voice was “old” (heard before) or “new.” 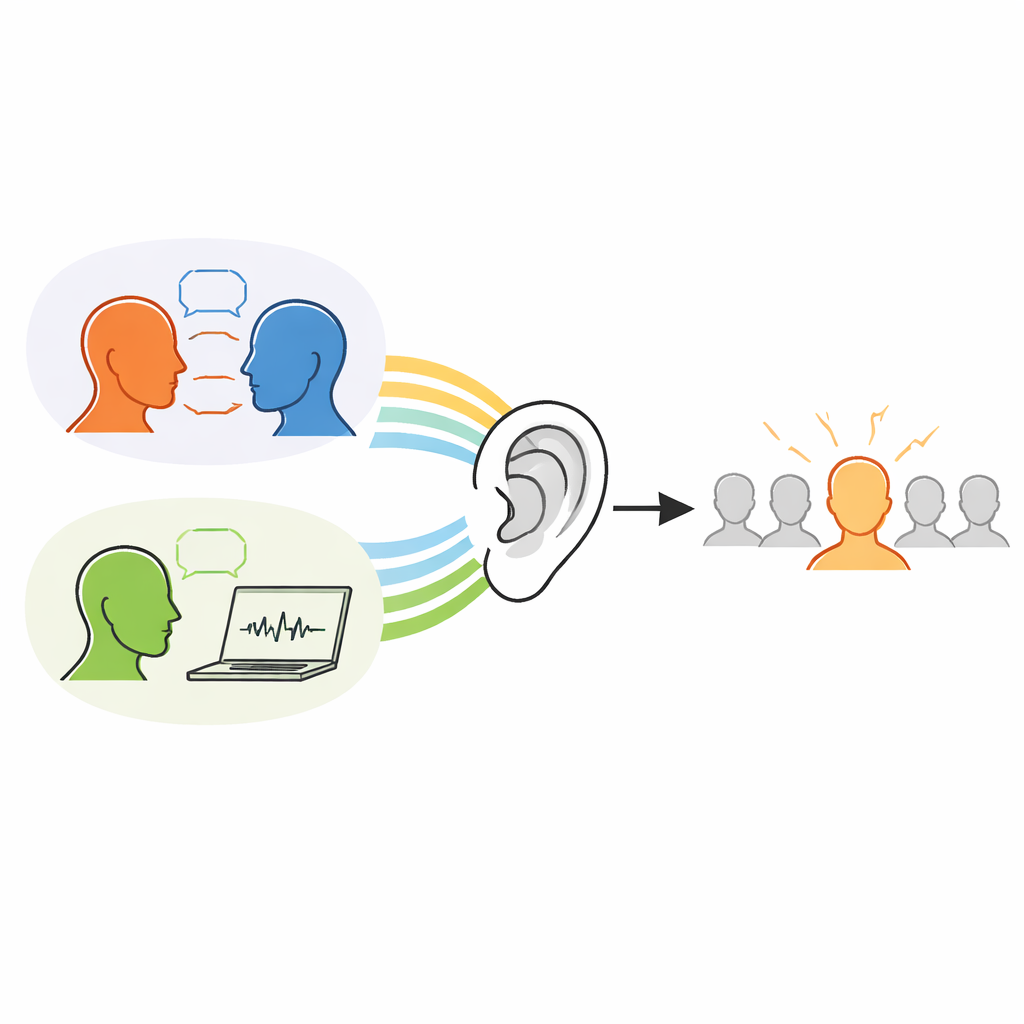
Making the challenge simple or hard
To see how memory load changes things, the team created two versions of the experiment. In the simple version, participants learned four voices at a time; in the challenging version, they learned ten. All speech came from a carefully built Zurich German voice corpus, using short fragments of natural‑sounding sentences rather than artificial sounds or isolated vowels. The researchers also used modern automatic speaker‑recognition tools to pick sets of voices that were similarly difficult to tell apart, so that neither learning method had an unfair advantage. Crucially, the total time spent listening to each voice was matched across the two conditions: people heard the same amount of speech whether they were memorizing or discriminating, only the task focus differed.
What the tests revealed
Across more than 130 police cadets, the pattern was clear. When later tested on whether a voice was old or new, participants performed better after the implicit discrimination task than after the explicit listen‑and‑memorize task. This advantage held both when only four voices were involved and when ten voices had to be learned, and it did not depend on whether discrimination or memorization came first. At the same time, overall recognition dropped when the number of voices increased, confirming that high “voice load” makes the task substantially harder. Interestingly, how well someone did on the initial discrimination task did not strongly predict how well they did on the later recognition test, suggesting that being able to tell two voices apart in the moment is not the same as forming a strong memory of who is who. 
Why effortless learning can work better
Why might a task that never mentions learning produce better memory than one that openly demands it? The authors point to the idea of cognitive load: our working memory has limited capacity, and explicitly trying to memorize several unfamiliar voices may overload it. In the discrimination task, listeners concentrated on a simple, perceptual decision—same or different—without also trying to rehearse who each person was. This may have freed up mental resources to encode the subtle patterns that distinguish one speaker from another. The discrimination setting also more closely resembles real conversations, in which we hear multiple talkers in quick succession rather than one isolated voice at a time.
What this means outside the lab
The study’s take‑home message is straightforward for non‑specialists: people can learn new voices more effectively when they are busy carefully comparing them, even if they do not realize they are memorizing them, than when they are told to sit and deliberately learn each voice. This has direct implications for forensic work, where staff often need to become familiar with many speakers in difficult recordings. Training regimes that rely on realistic discrimination exercises—asking whether two clips come from the same speaker—may build stronger, more reliable voice memories than classic “listen and remember” drills. More broadly, the findings highlight that our brains may learn complex social signals like voices best when learning is woven into engaging tasks, rather than treated as a separate act of willpower.
Citation: Fröhlich, A., Ramon, M., French, P. et al. Implicit voice learning through discrimination outperforms explicit listen-and-memorize tasks. Sci Rep 16, 13498 (2026). https://doi.org/10.1038/s41598-026-41541-z
Keywords: voice recognition, implicit learning, forensic audio, speaker identity, auditory memory