Clear Sky Science · en
A dynamic element-activated non-semantic sparse attention method for remote sensing small object detection
Why spotting tiny details from space matters
From traffic monitoring and disaster response to crop health and coastal surveillance, modern life increasingly depends on images taken from planes, drones, and satellites. Yet many of the important things in these pictures—cars, boats, people, or small structures—occupy only a handful of pixels. Against busy city streets, rippled water, or patchy fields, today’s algorithms often miss these tiny objects or confuse them with background clutter. This study introduces a new way of teaching computers to pay closer attention to fine visual details, making it easier to reliably find very small objects in complex aerial scenes.
Seeing small things in a noisy world
In remote sensing images, small objects are hard to recognize for several reasons. They cover few pixels, they often overlap or crowd together, and they appear against backgrounds filled with repeating textures, shadows, and reflections. Traditional object detectors, even those powered by deep learning, tend to focus on broad, high-level patterns that work well for larger objects in everyday photos but are easily confused at the tiny scale. As a result, they miss many targets, especially when objects are partially hidden, densely packed, or surrounded by similar-looking structures.
A new three-part way of focusing attention
To tackle these problems, the authors propose a detection framework built around three cooperating ideas, each aimed at preserving and enhancing the faint signals that tiny objects leave in an image. First, they add a “non-semantic sparse attention” module that looks at small patches of the image one at a time and concentrates on basics like edges and textures rather than broad scene meaning. Second, they introduce a “dynamic element-activated” mechanism that helps different layers of the neural network share and strengthen important channels of information, especially those that hint at small targets hidden in clutter. Third, they use a diffusion wavelet-based structure that processes features in parallel at multiple scales, reducing the loss of detail that usually occurs as images are repeatedly downsampled.
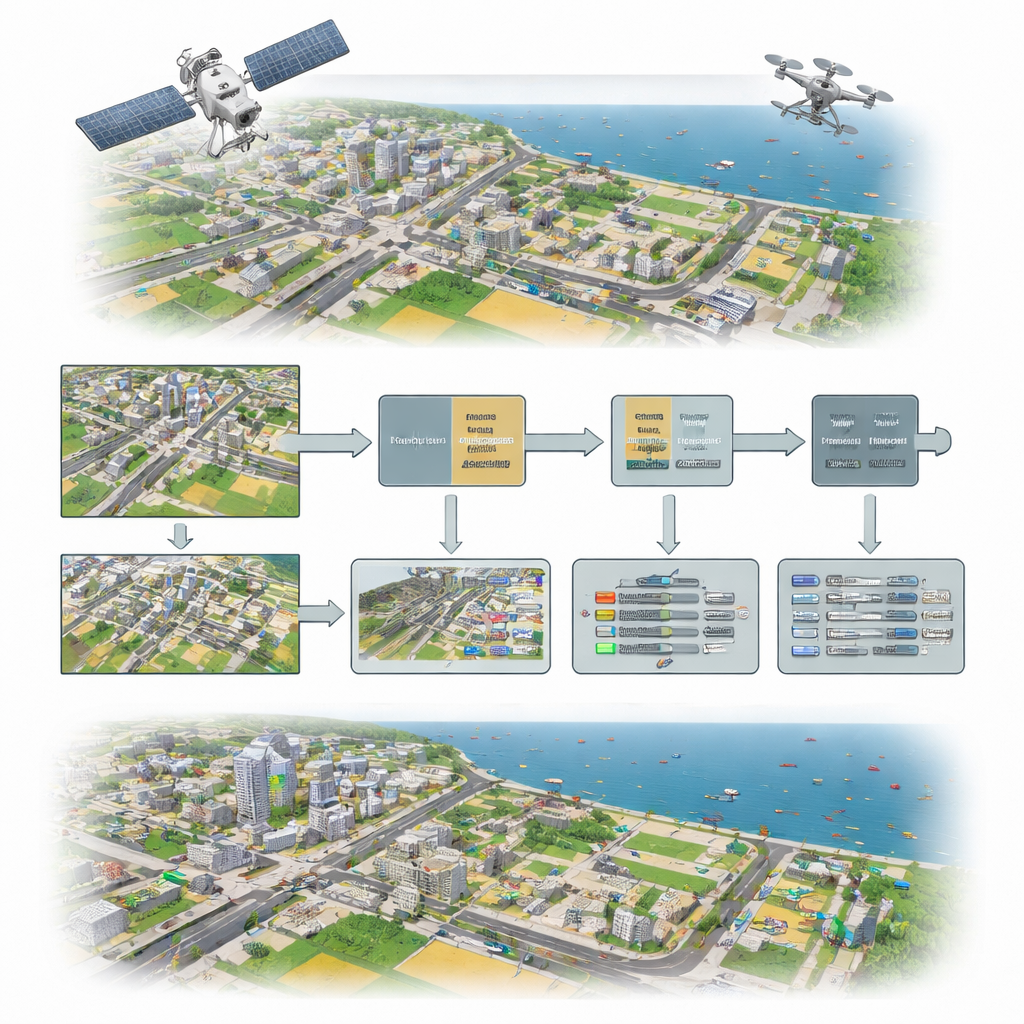
How the new method reshapes image understanding
Inside the network, the non-semantic sparse attention module chops the feature maps into many small blocks and computes attention only within each local block. This makes the model highly sensitive to subtle patterns like the outline of a car roof or the wake of a tiny boat while reducing distractions from distant, unrelated regions. The dynamic cross-layer channel attention then rearranges and overlaps channels from different depths of the network so that strong hints from one layer can reinforce weaker hints in another. A special, smoothly varying activation function adjusts these signals element by element, compressing extreme values but keeping useful variation intact, which helps stabilize learning without expensive normalization steps.
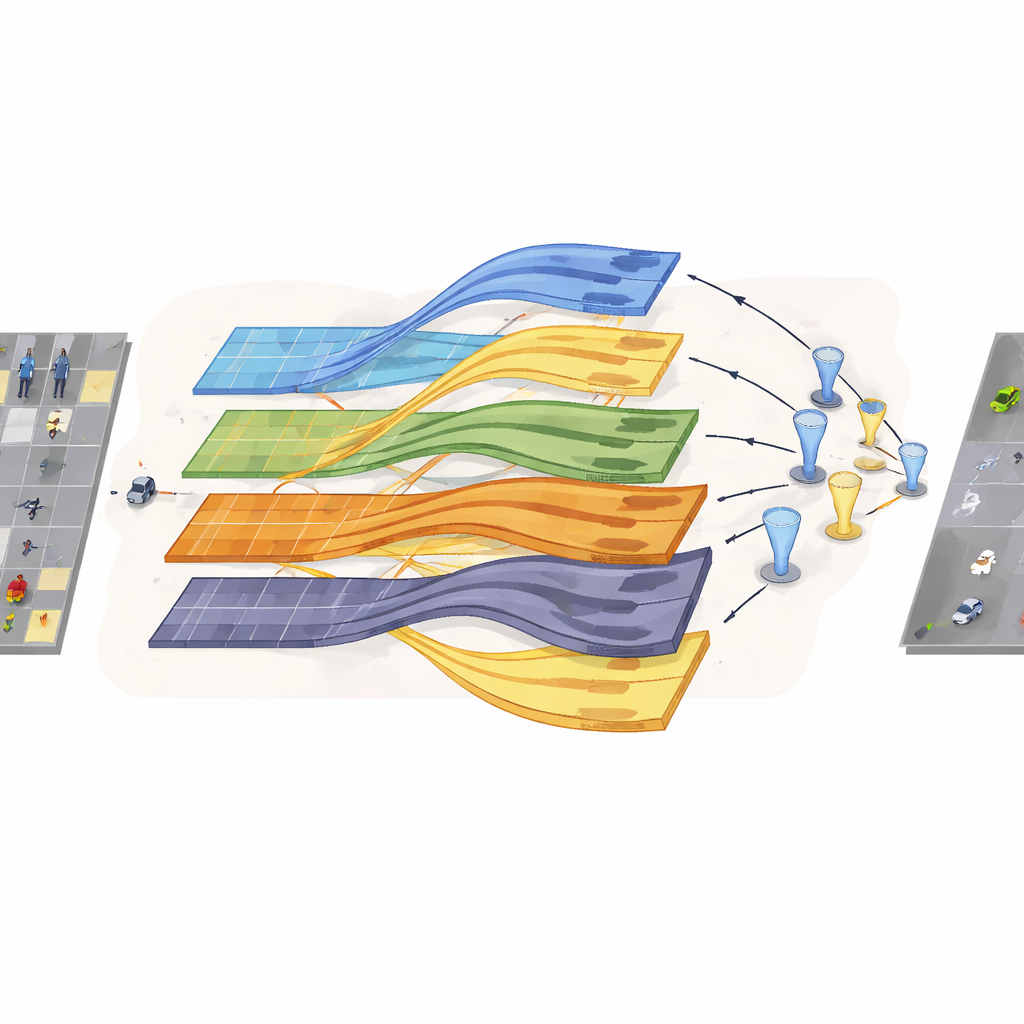
Keeping tiny signals alive through multiple scales
The diffusion wavelet convolution component addresses another key weakness of standard convolution: as features are gradually shrunk to summarize larger areas, the already fragile signatures of small objects can vanish. Here, the image features are passed through several parallel branches, each capturing different frequency bands—roughly corresponding to coarse shapes and fine details. By approximating wavelet filters with efficient polynomials, the network can expand its “field of view” while still preserving sharp transitions and edges that mark the presence of tiny targets. These multi-scale features are later recombined so that the detector sees both the broad context and the crisp local cues needed to separate objects from cluttered backgrounds.
Putting the approach to the test
The researchers evaluated their method on two challenging public datasets: VisDrone, which contains crowded urban scenes captured by drones, and AI-TODv2, which focuses on very small objects in aerial images. Compared with a widely used baseline detector and several advanced alternatives, the new framework detected more small and medium-sized objects, recovered more partially occluded targets, and reduced false alarms caused by confusing structures such as building edges or lamp posts. On VisDrone, overall detection accuracy increased noticeably while maintaining practical processing speed, and similar gains were observed on AI-TODv2, including for extremely tiny targets that many models struggle to see at all.
What this means for real-world sensing
For non-specialists, the key message is that this work offers a more careful, detail-preserving way for computers to study aerial images. By explicitly steering attention toward edges and textures, smartly combining information across network layers, and protecting fragile signals during downsampling, the method makes it easier to find very small objects in busy, real-world scenes. This opens the door to more reliable monitoring of traffic, infrastructure, agriculture, and maritime activity from above, and provides a technical foundation that future systems can build on—potentially extending to video tracking and three-dimensional mapping of tiny but important targets.
Citation: Liu, S., Bie, Y., Dong, Y. et al. A dynamic element-activated non-semantic sparse attention method for remote sensing small object detection. Sci Rep 16, 11577 (2026). https://doi.org/10.1038/s41598-026-39381-y
Keywords: remote sensing, small object detection, aerial imagery, attention mechanisms, computer vision