Clear Sky Science · en
A lightweight multi-scale detection framework for X-ray images with supervised contrastive learning
Why smarter X-ray checks matter
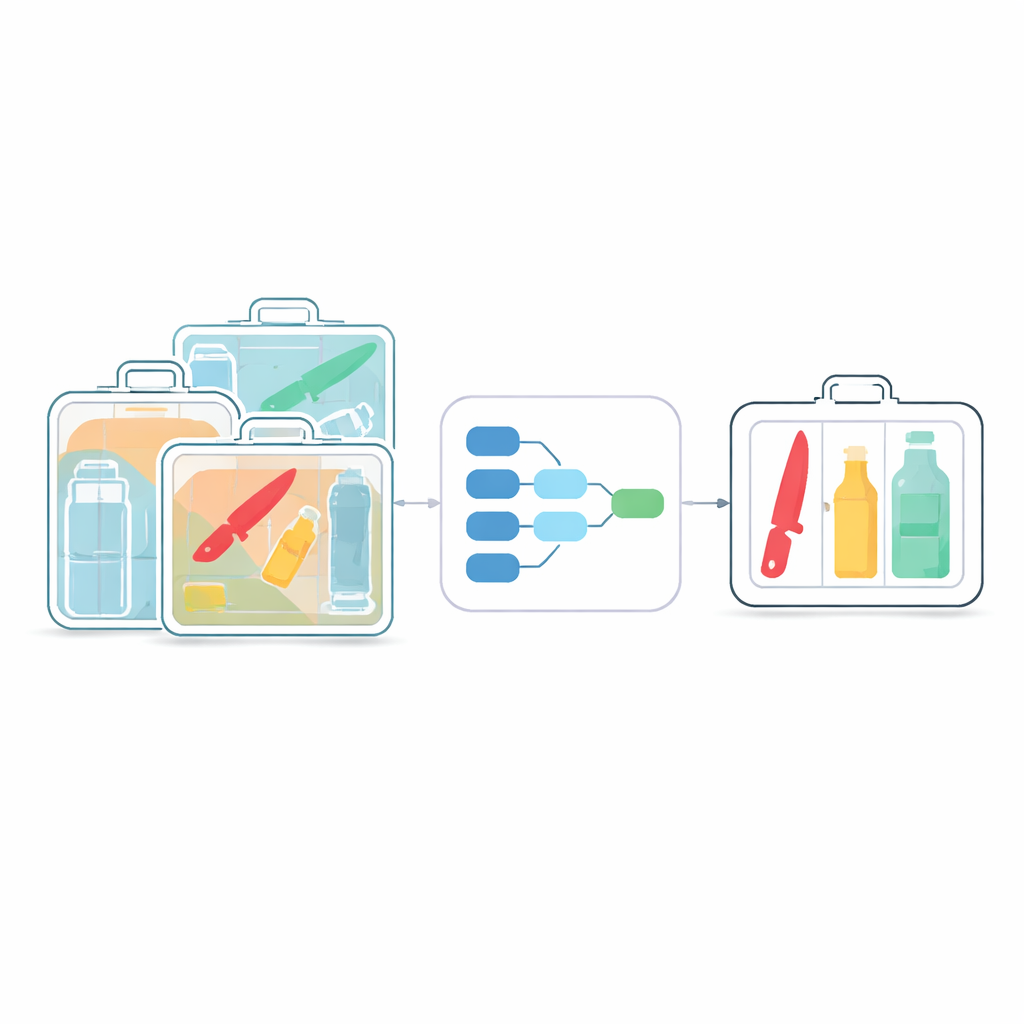
Anyone who has inched through airport security knows that every bag must be scanned quickly and accurately. Yet X-ray images are anything but simple: knives, bottles, laptops, and chargers pile on top of one another, and dangerous items can easily hide in the clutter. This paper presents a new artificial intelligence (AI) method that helps X-ray machines spot small or overlapping threats more reliably, while still running fast enough for busy checkpoints.
The challenge of seeing through clutter
X-ray security systems are the first line of defense in airports, subway stations, and other crowded public spaces. Traditional human inspection is slow and tiring, which increases the risk of missed items. Modern AI detectors like the YOLO family have improved automated screening, but they were originally designed for everyday photos, not ghostly, low-contrast X-ray views. In these scans, objects often overlap, appear semi-transparent, and vary widely in size. Small blades or bottles can be buried among harmless items, and many current algorithms either miss them or require heavy computing power that is hard to deploy on compact, low-cost machines.
A leaner brain for X-ray machines
The authors build on the popular YOLOv8 detector and redesign it specifically for X-ray imagery. Their first step is to slim down the network using “depthwise separable” convolutions—a technical way of saying the model looks at patterns in a more frugal manner. Instead of applying large, expensive filters to every channel of the image at once, it breaks the operation into cheaper steps. This change cuts the number of calculations by about a quarter to two-fifths, yet still preserves the fine details needed to spot small, partly hidden objects. The result is a lighter digital “brain” that can run in real time on modest hardware, such as embedded processors inside scanners.
Helping the model focus on what matters
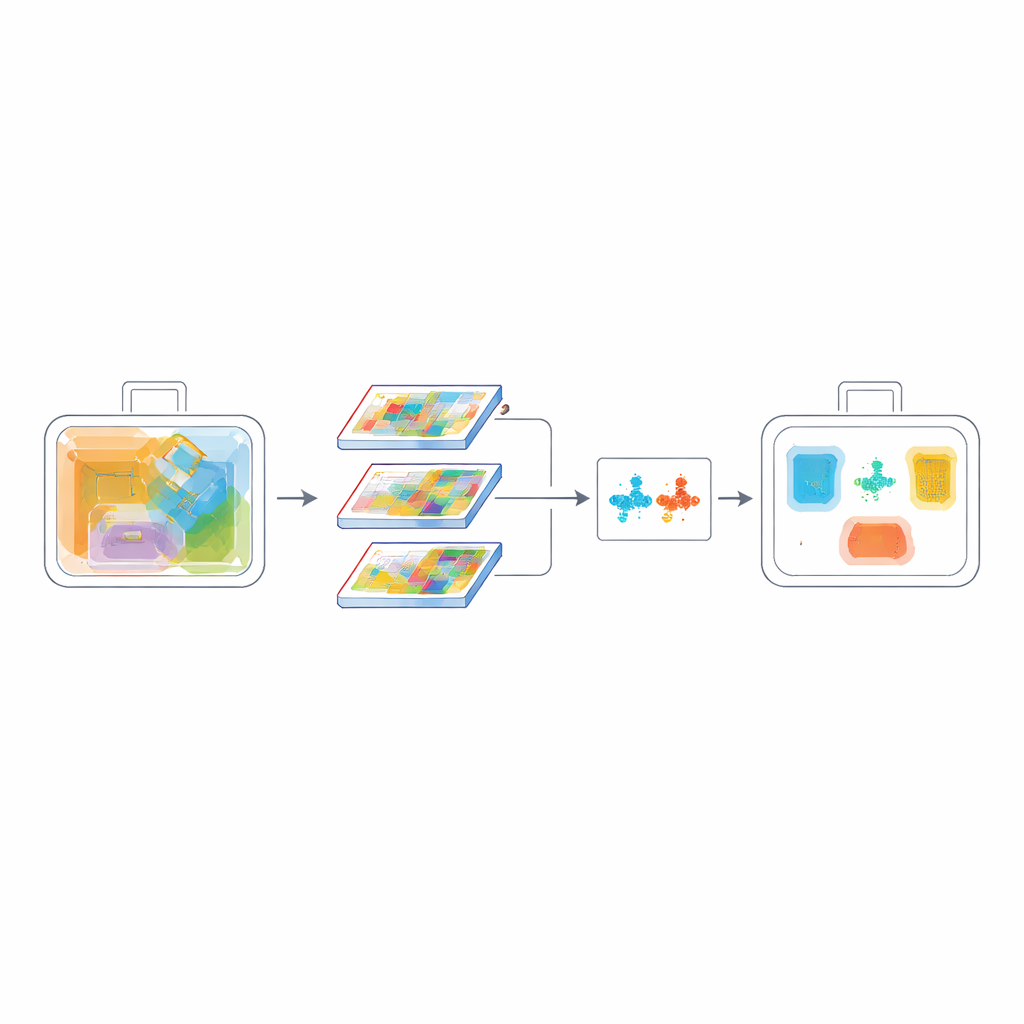
Making the network smaller is not enough; it must also be more selective. To this end, the researchers introduce a Channel-Spatial Attention Fusion (CSAF) module. One branch of this module learns which kinds of visual features—edges, shapes, or material hints—are most informative overall, while another branch learns where in the image the action is happening. Instead of applying these attentions one after the other, CSAF processes them in parallel and then fuses them, so the system can consider both the “what” and the “where” at the same time. These attention units are woven into a multi-scale design that combines coarse and fine views of the scene, which is especially helpful for detecting tiny, overlapping items in crowded bags.
Teaching the system to separate look-alikes
Another difficulty in X-ray scans is that many items look similar: a tin and a spray can, or different kinds of knives, can share nearly identical outlines. To make the model better at telling such categories apart, the authors add a contrastive learning objective. During training, the network is encouraged to pull examples of the same class closer together in its internal representation, while pushing different classes further apart. At the same time, a pixel-level overlap measure called PIoU helps fine-tune the placement and shape of the predicted bounding boxes, which is vital when objects are tilted, crowded, or partially visible. Together, these losses teach the model not only where an object is, but also what makes it distinct from confusing neighbors.
Proving performance in realistic tests
The team evaluates their approach on two challenging X-ray datasets that include real checkpoints and synthetic baggage scenes with multiple threat categories. Compared with the standard YOLOv8 baseline, their model reaches higher accuracy on strict overlap measures while using fewer parameters and less computation. It maintains very high detection rates for sharp objects and improves recognition of transparent or deformable items like bottles and drink cartons. Precision–confidence and recall–confidence curves show that its predictions remain stable even as the threshold for declaring a detection is raised, meaning fewer false alarms and fewer missed threats. Tests on a second dataset collected elsewhere confirm that the system generalizes well, an important requirement for real-world deployment where bag contents and imaging conditions vary.
What this means for everyday travelers
For a layperson, the bottom line is that this work offers a smarter, leaner way to scan luggage. By redesigning a modern AI detector to be both lightweight and more discriminating, the authors enable X-ray machines that can run quickly on affordable hardware while still catching small, overlapping, or look-alike threats. If such methods are adopted in practice, they could help shorten lines, reduce unnecessary bag checks, and—most importantly—improve the chances that truly dangerous items are caught before they ever reach the gate.
Citation: Diao, Q., Chan, W., Zain, A.M. et al. A lightweight multi-scale detection framework for X-ray images with supervised contrastive learning. Sci Rep 16, 8635 (2026). https://doi.org/10.1038/s41598-026-38000-0
Keywords: X-ray security, object detection, deep learning, airport screening, computer vision