Clear Sky Science · en
A novel distributed gradient algorithm for composite constrained optimization over directed network
Smarter Decision-Making Without a Central Boss
Modern technologies—from power grids and sensor networks to fleets of drones—often rely on many devices working together without a single central controller. Each device sees only part of the picture, yet the whole group must agree on a good, safe operating point. This paper introduces a new way for such distributed systems to make joint decisions efficiently and reliably, even when the underlying communication links are one‑way and the problem includes difficult constraints and sharp “cost corners.”
Why Many Small Brains Beat One Big Brain
Centralized optimization—where one powerful computer gathers all data, solves a big problem, and sends back commands—is fragile and hard to scale. It can fail if the central unit goes down, or choke on communication delays in large systems. Distributed optimization flips this picture: each node (or agent) keeps its own data, updates its own local decision, and exchanges only limited information with nearby neighbors. The challenge is to design update rules so that, despite partial and one‑way communication, all nodes still agree on a solution that is globally best for the network.
Hard Problems With Sharp Corners and Real-World Limits
The authors focus on a demanding class of problems where the total cost combines smooth terms (which change gently) with non-smooth ones (which can create sharp kinks), such as the popular l1 norm. These non-smooth parts are key to promoting sparsity and robustness in applications like compressed sensing, signal denoising, and model fitting. On top of that, each node must respect local equality and inequality constraints and stay within allowed bounds. All of this must be handled over a directed communication network, where information may flow from node A to node B but not necessarily back. Existing methods typically assume undirected links, simpler constraints, or fixed step sizes that are hard to tune and less flexible.
A New Way for Nodes to Talk and Agree
To tackle these difficulties, the paper proposes a new distributed gradient-based algorithm tailored to composite, constrained problems over directed networks. Each node repeatedly adjusts its local decision by following a projected gradient step: it moves in a direction that lowers the overall cost, then projects the result back into its allowed region so that constraints remain satisfied. Extra variables act like internal bookkeeping, helping the network enforce equality and inequality conditions and handle the non-smooth l1 term. A key innovation is a correction mechanism that compensates for the imbalance caused by one‑way links, using only row‑stochastic weights—meaning each node needs to know only how it receives information, not who receives information from it.
Flexible Step Sizes With Guaranteed Convergence
Another hallmark of the method is its use of time-varying yet constant step sizes: each node may choose its own step within a provably safe range, instead of sharing a single fixed value. This flexibility makes tuning easier in practice and allows the algorithm to adapt better to different local conditions. Using tools from stability theory, the authors build a Lyapunov function—a kind of mathematical energy measure—and prove that it decreases at every iteration, as long as the step sizes respect a clear upper bound. This guarantees that, from any starting point, all nodes’ decisions converge to the same globally optimal solution, even in the presence of non-smooth terms and mixed constraints.
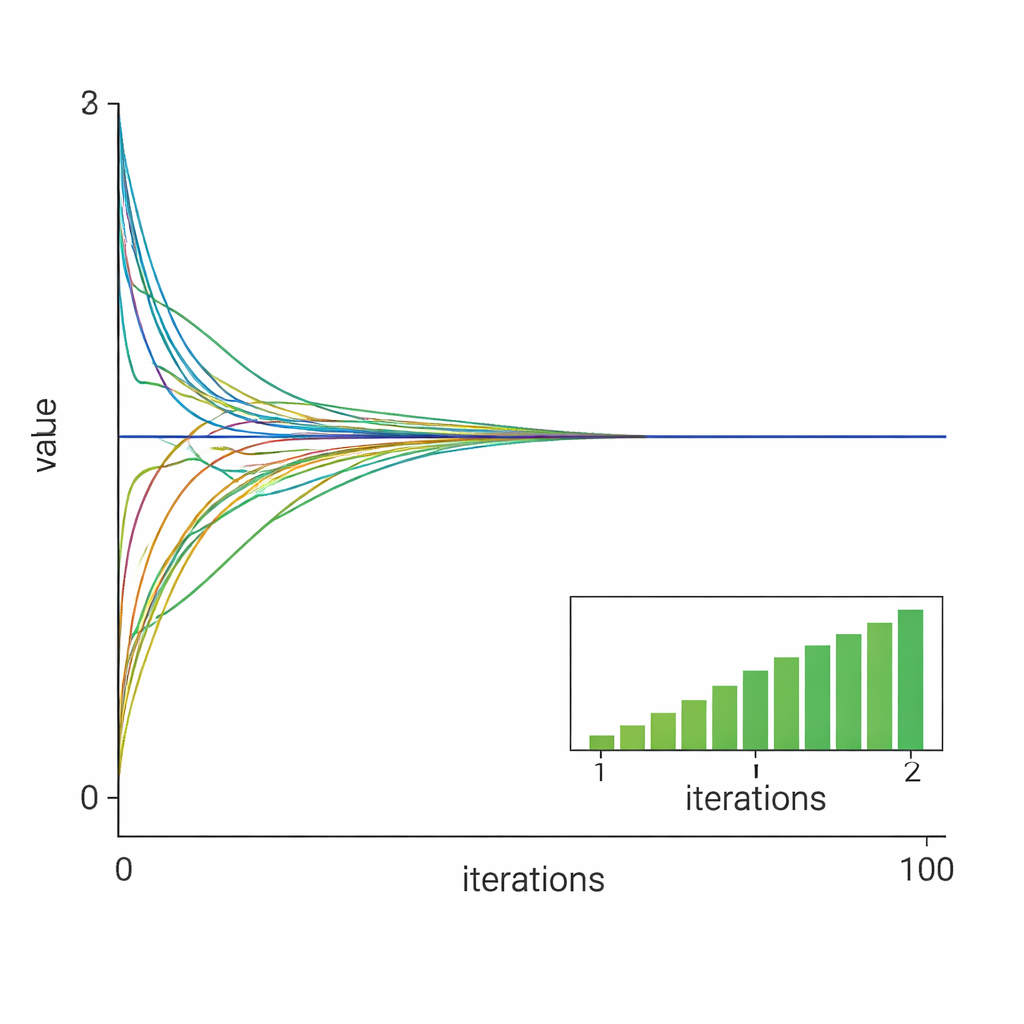
Putting the Method to the Test
The researchers validate their theory with two numerical case studies. In the first, ten nodes cooperatively solve a constrained quadratic problem with l1 regularization, similar to tasks in resource allocation or sensor fusion. The results show that all local variables quickly align with the centralized optimal solution and that using a properly chosen constant step size leads to faster, almost linear convergence compared with a diminishing step size. In the second case, the method tackles an ill-conditioned least absolute deviation problem, known to be hard for standard solvers. Even here, with only five nodes and highly unbalanced data, the algorithm reliably steers all agents toward the true solution.
What This Means for Real Systems
In plain terms, the paper delivers a robust recipe for groups of networked devices to jointly solve tough optimization problems without a master controller, while honoring practical limits and working over one‑way communication links. The method can be applied to power systems, sensor networks, and distributed machine learning tasks where constraints and sparsity matter. Because it needs only local neighbor information and offers clear rules for picking step sizes, it is well suited for real deployments. The authors suggest extending the approach to time‑varying networks next, pushing closer to realistic, ever-changing communication environments.
Citation: Ou, M., Zhang, H., Yan, Z. et al. A novel distributed gradient algorithm for composite constrained optimization over directed network. Sci Rep 16, 5185 (2026). https://doi.org/10.1038/s41598-026-36058-4
Keywords: distributed optimization, directed networks, multi-agent systems, sparse regularization, constrained convex problems