Clear Sky Science · en
A hybrid transformer–zero-shot learning framework with Muon optimization for intelligent channel estimation in MIMO wireless systems
Why smarter wireless matters to you
Streaming video on the go, self-driving cars, and dense networks of sensors all rely on wireless links that stay fast and reliable even when conditions change. This paper explores a new way to help future Wi-Fi, 5G, and 6G networks "sense" the airwaves more intelligently so they can keep connections strong without constant manual tuning by engineers.
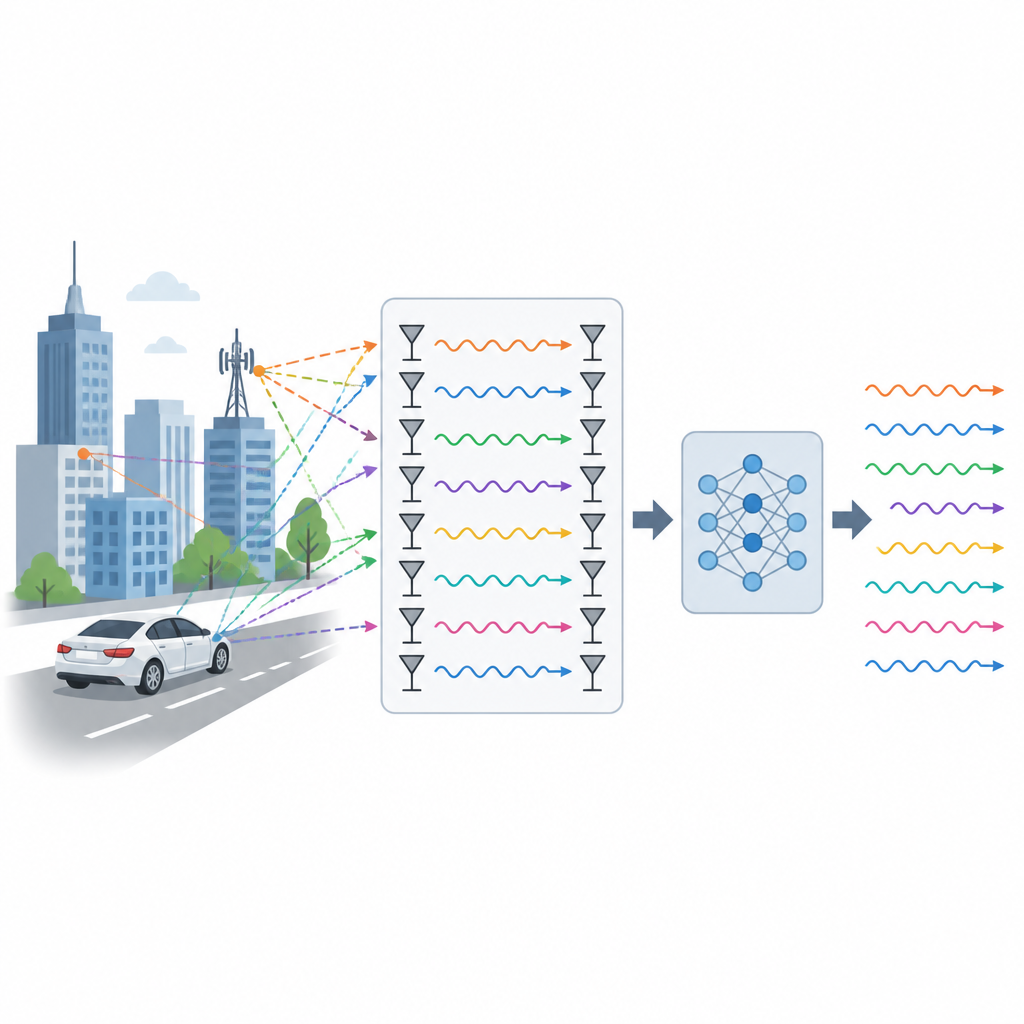
How modern antennas boost speed
Today’s high-speed networks often use many antennas at once, a setup called multi-antenna or MIMO. Instead of one radio path between a phone and a base station, there can be dozens. Each path behaves differently as signals bounce off buildings, cars, and people. To make the most of this, the network must estimate the state of each path, a task known as channel estimation. If this estimate is wrong, data rates drop, errors increase, and power is wasted. Classic tools do this with neat equations and pilot signals but start to stumble when people move quickly, the air is noisy, or the environment does not match the one assumed on paper.
Why old and new tools fall short
Engineers have tried both traditional formulas and newer deep learning models to track the wireless channel. Simple methods such as least squares and minimum mean square error are fast and easy to implement, but they depend on clean statistics that often do not hold in busy cities or on fast trains. Deep learning models like convolutional and recurrent networks can learn richer patterns from data, yet they usually need huge training sets and must be retrained whenever the surroundings change. This makes them hard to use in a world where networks face new signal strengths, motion patterns, and building layouts every day.
A hybrid model that can handle the unknown
The authors propose a hybrid framework that mixes three modern ideas to tackle these limits. A Transformer network, best known from language models, learns global patterns across antennas and across time using attention, which lets it focus on the most useful signal pieces. Zero-shot learning adds a semantic layer: it represents each wireless situation using a compact "attribute" vector that encodes ideas such as signal strength range, type of fading, or motion level. By projecting real signal examples into this shared space, the model can recognize and handle channel conditions it has never been trained on. Finally, a new optimization method called Muon guides training so that the model converges faster, avoids overfitting to noisy data, and generalizes better than when using a standard optimizer.
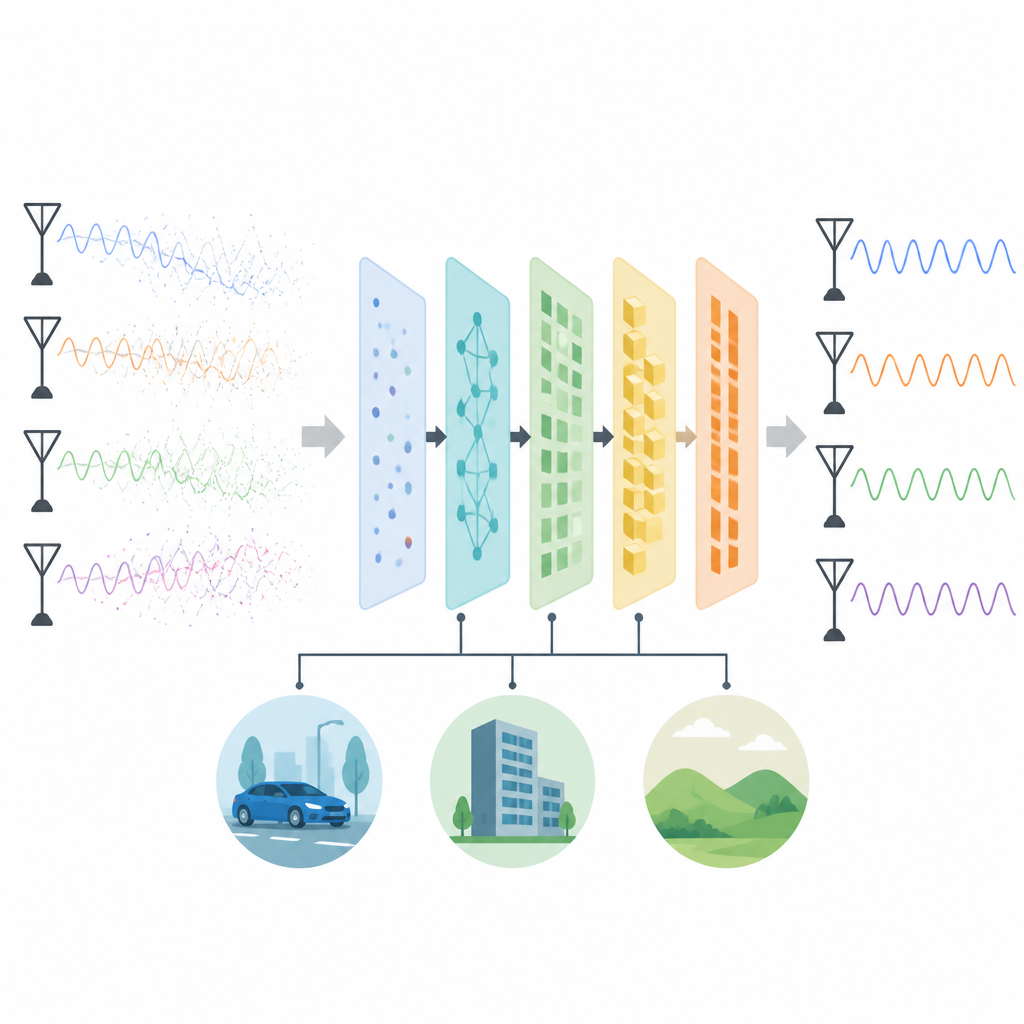
What the simulations reveal
To test the approach, the researchers create a rich set of virtual wireless scenes, including both slowly changing links and highly time-varying ones, with many levels of signal-to-noise ratio, motion speeds, and delay patterns. They compare three versions of their design (zero-shot with Muon, Transformer with zero-shot, and the full combination) against classic estimators and several deep learning baselines. Across a wide range of conditions the full Transformer–zero-shot–Muon model consistently produces lower mean squared error, meaning it predicts the channel more accurately. It retains strong performance even when tested on signal conditions it never saw during training, such as very low or very high signal levels or new motion profiles. The model also stays effective when the number of pilot symbols is sharply reduced, showing robustness when overhead must be kept low.
Implications for future wireless networks
For a general reader, the key message is that smarter software can help future wireless systems learn about their environment in a more human-like way, using abstract descriptions rather than rigid formulas. By combining attention-based processing, semantic descriptions of channel behavior, and adaptive training, the proposed framework offers a path to radio links that can adapt on the fly to moving users, crowded airwaves, and new deployment scenarios, without constant retraining. In massive multi-antenna setups the gains are especially large, pointing toward networks that can deliver higher data rates and more reliable service while using spectrum and energy more efficiently.
Citation: Salama, W.M., Aly, M.H., Alshathri, S. et al. A hybrid transformer–zero-shot learning framework with Muon optimization for intelligent channel estimation in MIMO wireless systems. Sci Rep 16, 16421 (2026). https://doi.org/10.1038/s41598-025-33791-0
Keywords: MIMO wireless, channel estimation, deep learning, transformer model, zero shot learning