Clear Sky Science · en
A comprehensive bedside chest radiography dataset with structured, itemized and graded radiologic reports
Why smarter chest X-rays matter
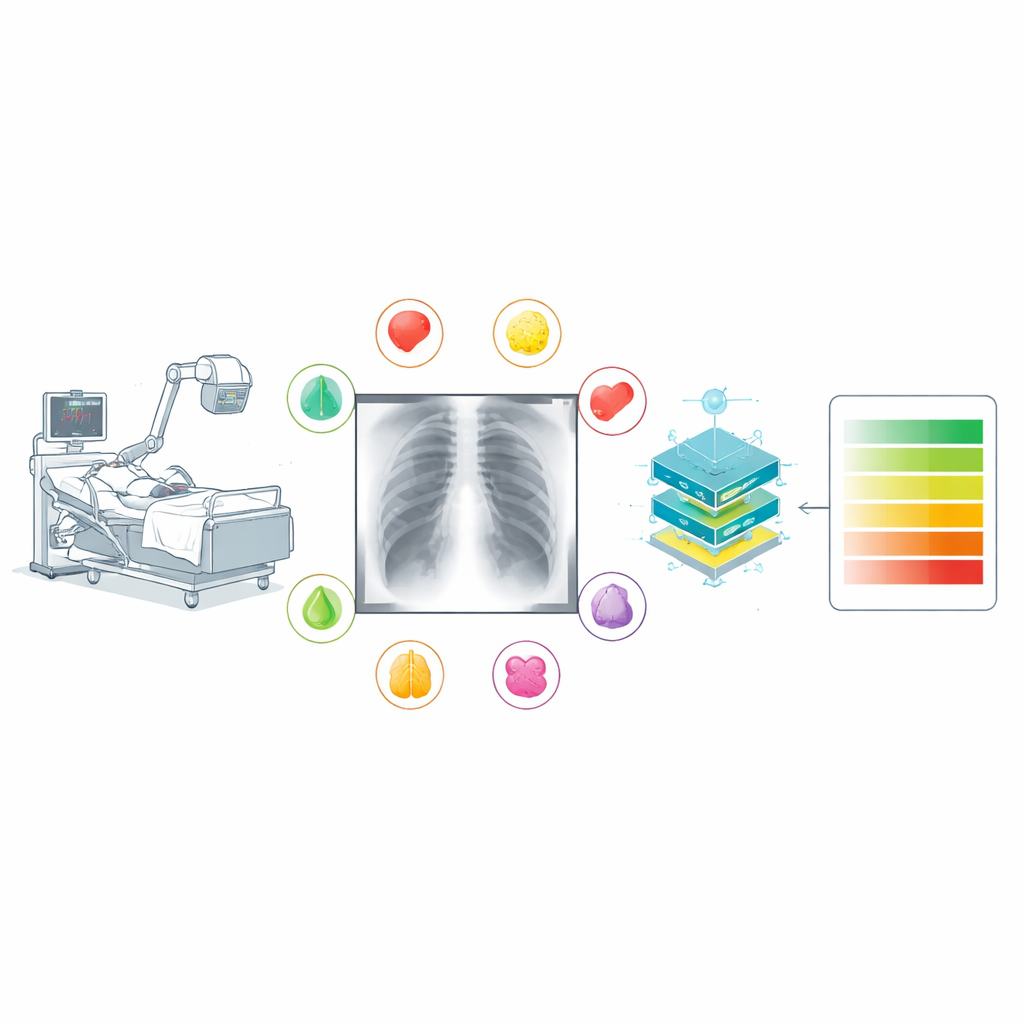
When someone is critically ill in an intensive care unit, a simple chest X-ray can reveal whether their lungs are filling with fluid, their heart is enlarged, or their airways have collapsed. Doctors often repeat these bedside X-rays day after day to track how patients are doing. Yet reading these images is difficult, especially when patients cannot sit or stand properly, and even experts do not always describe what they see in the same way. This article presents TAIX-Ray, a large, carefully labeled collection of bedside chest X-rays designed to teach computers to recognize and grade lung and heart problems more reliably—potentially speeding up diagnosis and supporting overworked medical staff.
What makes current data sets fall short
Over the past decade, big public chest X-ray collections have fueled rapid progress in artificial intelligence for medical imaging. However, most of these databases were built by feeding radiology reports through language-processing software to guess which diseases were present. That shortcut introduces two major problems. First, real clinical reports are full of vague or cautious language—phrases that can be interpreted differently depending on context. Second, radiologists vary widely in how they express uncertainty; more than half of chest imaging reports contain at least one such hedged statement. Converting this messy language into simple “disease present” or “disease absent” tags adds noise to the data and can mislead learning algorithms, limiting how well even the most sophisticated models can perform.
A new kind of X-ray collection
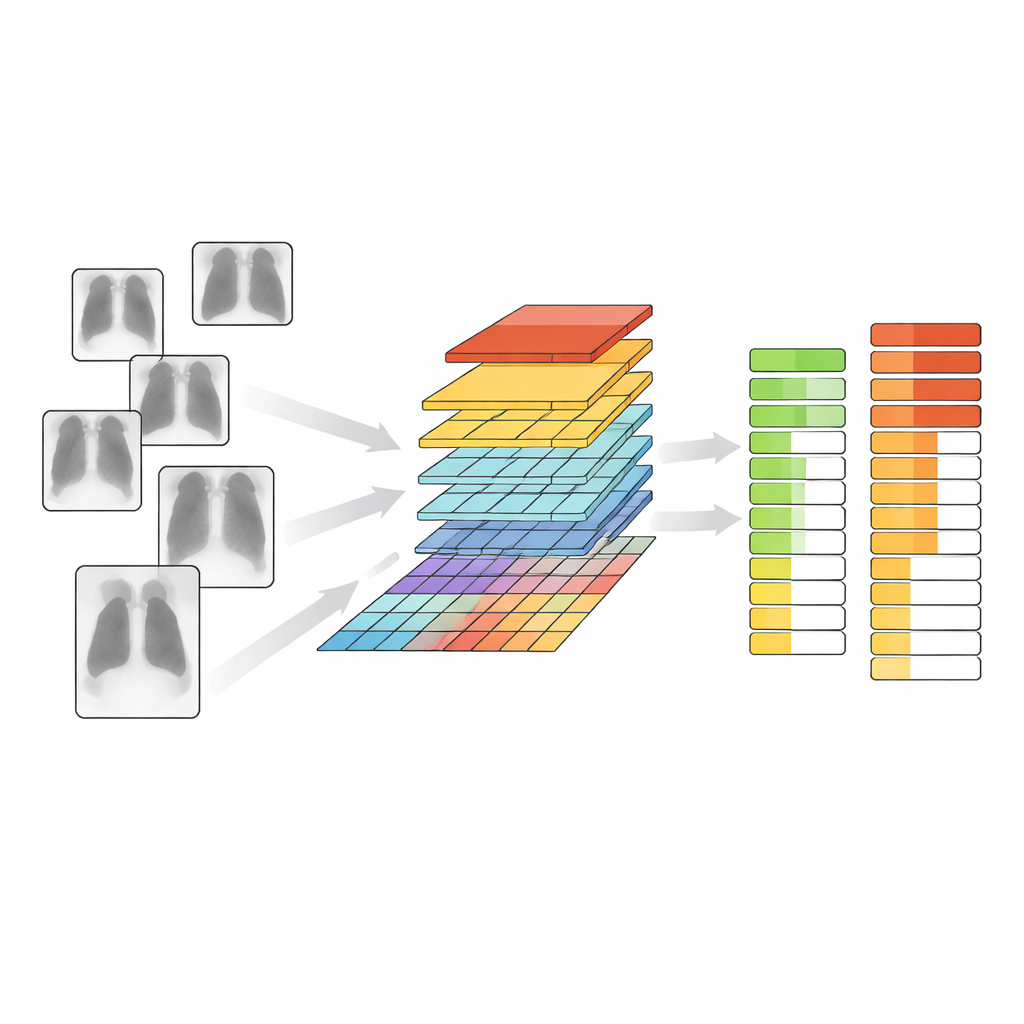
TAIX-Ray tackles these weaknesses by starting from structured reports rather than free-form text. The authors gathered 215,381 bedside chest X-rays from 47,724 intensive care patients over 14 years at a single large hospital. During routine care, 134 trained radiologists filled out a standardized electronic form for each X-ray. Instead of writing whatever wording came to mind, they selected item-by-item ratings for key findings: heart size, signs of fluid overload in the lungs, fluid around the lungs on each side, hazy patches within the lungs on each side, and collapse of lung tissue on each side. Each finding was graded on an ordered scale from “none” through “questionable,” “mild,” “moderate,” and “severe” (heart size used a similar four-step scale). This approach captures not just whether something is present but how bad it is and where it is located.
How the images and labels were prepared
To protect patient privacy, all identifying details were stripped from the images and reports, and each patient, physician, and X-ray was assigned a random code. The original report forms, which the hospital software had turned into plain text, were passed through a custom computer script that extracted only the predefined rating words and ignored any extra comments. The images themselves were converted from their original medical format into standard grayscale picture files while preserving the full range of brightness values that carry subtle diagnostic clues. Each picture was also resized to a consistent maximum dimension for easier handling, with the original full-resolution versions kept available. Studies that lacked essential data or had ambiguities—such as multiple images where it was unclear which one had been rated—were carefully excluded to maintain data quality.
Building and testing an example AI model
To show how TAIX-Ray can be used, the team trained a modern image-analysis system based on a “vision transformer,” a deep-learning architecture originally developed for general image tasks. Starting from a model that had already taught itself useful visual features from vast collections of non-medical pictures, they added layers that learned to predict the presence and severity of each chest finding. They ran two main experiments. In the first, the model simply decided whether an X-ray was normal or showed any abnormality. In the second, it predicted the full graded scale for each finding. Using patient-level splits into training, validation, and test sets to avoid overlap, the model achieved high accuracy and strong agreement with the original radiologist ratings across all tasks, with particularly good performance for fluid around the lungs and changes in heart size.
What this means for patients and doctors
By pairing a very large number of real-world bedside X-rays with consistent, finely graded expert labels, TAIX-Ray offers a foundation for building AI tools that do more than flag “something is wrong.” Models trained on this resource can learn to estimate how severe common lung and heart problems are and how they change over time, information that matters deeply for treatment decisions in the ICU. Because the data, code, and example models are publicly available, other researchers can reuse them, compare methods fairly, and extend them to new questions. While such systems will not replace radiologists, they could act as a second pair of eyes—highlighting subtle changes, prioritizing critical cases, and bringing more consistent assessments to some of the sickest patients in the hospital.
Citation: Truhn, D., Geiger, D., Siepmann, R. et al. A comprehensive bedside chest radiography dataset with structured, itemized and graded radiologic reports. Sci Data 13, 632 (2026). https://doi.org/10.1038/s41597-026-07271-7
Keywords: chest X-ray AI, intensive care imaging, radiology datasets, lung and heart findings, medical image grading