Clear Sky Science · en
Dataset of solubility values for organic compounds in binary mixtures of solvents at various temperatures
Why this matters for everyday chemistry
Many products we rely on, from medicines to plastics and paints, depend on how well a substance dissolves in a liquid. In real industrial settings, scientists rarely work with a single pure solvent; they often mix two liquids to fine tune how much of a solid will dissolve. Measuring this for every new compound and solvent pair is slow and laborious. This paper introduces MixtureSolDB, a large, carefully checked collection of experimental data that captures how more than eight hundred organic compounds dissolve in hundreds of different two solvent mixtures across a wide range of temperatures. Such a resource is designed to accelerate research in drug development, materials design and green manufacturing.
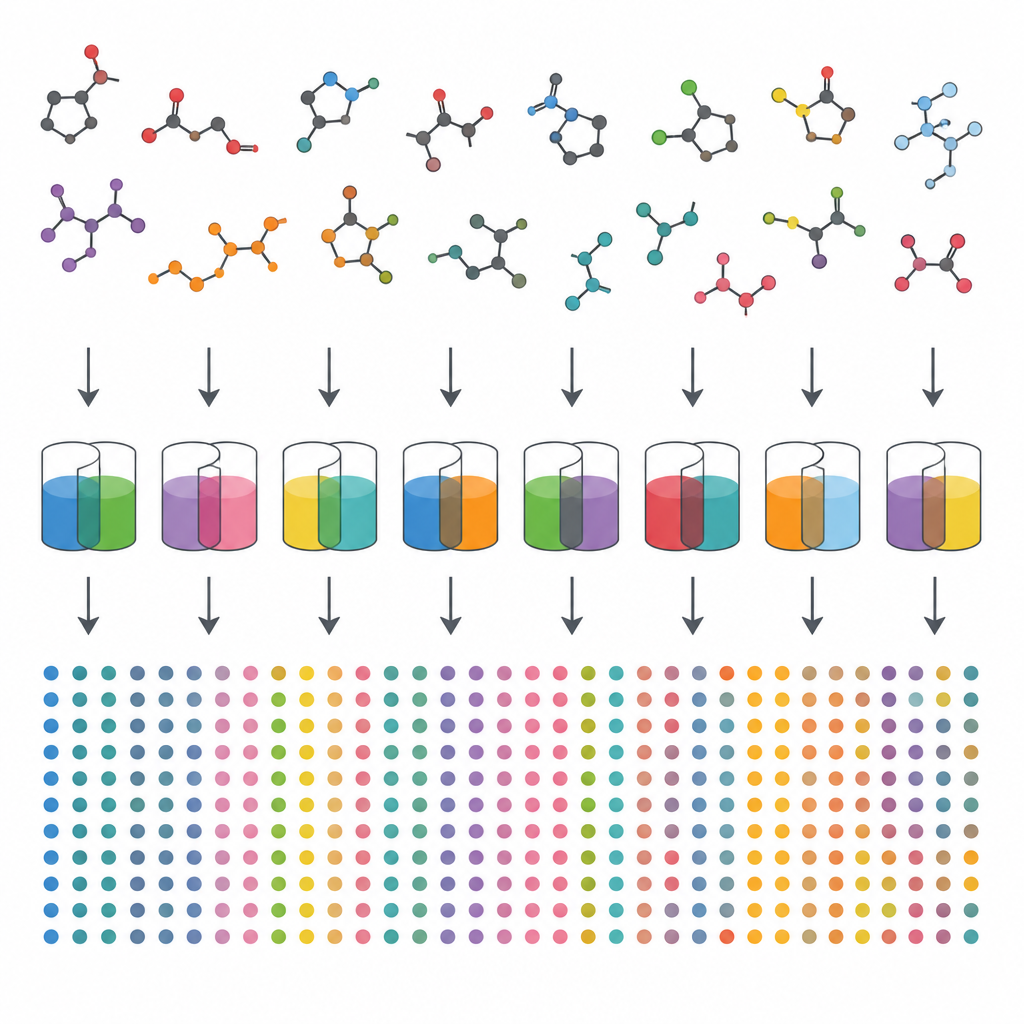
A big map of how things dissolve
The authors gathered 175,166 individual measurements of solubility for 810 organic compounds in 750 different binary solvent mixtures, spanning 3,001 distinct combinations of solute and mixed solvents between 252 and 383 kelvin. Each data point records how much of a compound can dissolve in a given pair of solvents at a particular mixing ratio and temperature. Many of these systems include water mixed with an organic liquid such as an alcohol, acetone or acetonitrile, reflecting how often such mixtures are used in laboratories and industry. By drawing from 1,115 peer reviewed articles, the authors greatly expand on previous public datasets, giving researchers a much broader and more varied picture of solubility behavior.
How the data were collected and cleaned
To assemble this dataset, the team first searched scientific journals for articles whose titles or abstracts contained phrases like “solubility + binary” or “solubility + mixture.” Starting from 5,775 records, they removed duplicates and papers without usable data, then manually extracted numerical values from 1,115 suitable articles. They focused on organic compounds, organic salts and defined solvates, under normal pressure and without extra additives, and ensured that solid forms were the most stable ones when polymorphs were involved. Molecular structures of solutes and solvents were translated into a standard text based format called SMILES, and naming conventions for solvents were unified to avoid confusion between synonyms.
Making numbers comparable across systems
Raw solubility data can be reported in many ways, such as mole fraction or grams per amount of solvent, and the fraction of each solvent in a mixture can be given by mass or by mole. To make the data consistent and ready for modelling, the authors converted all measurements into several standard forms, including a mass based value expressed as grams of solute per 100 grams of solvent and its decimal logarithm, a common choice in data driven solubility studies. They used molecular weights computed by open source chemistry software to carry out these conversions, including for special cases such as polyethylene glycol based solvents. The final table also records detailed metadata: the temperature, composition of the solvent pair, identifiers from public databases, and whether a compound is approved as a drug by the U.S. Food and Drug Administration.
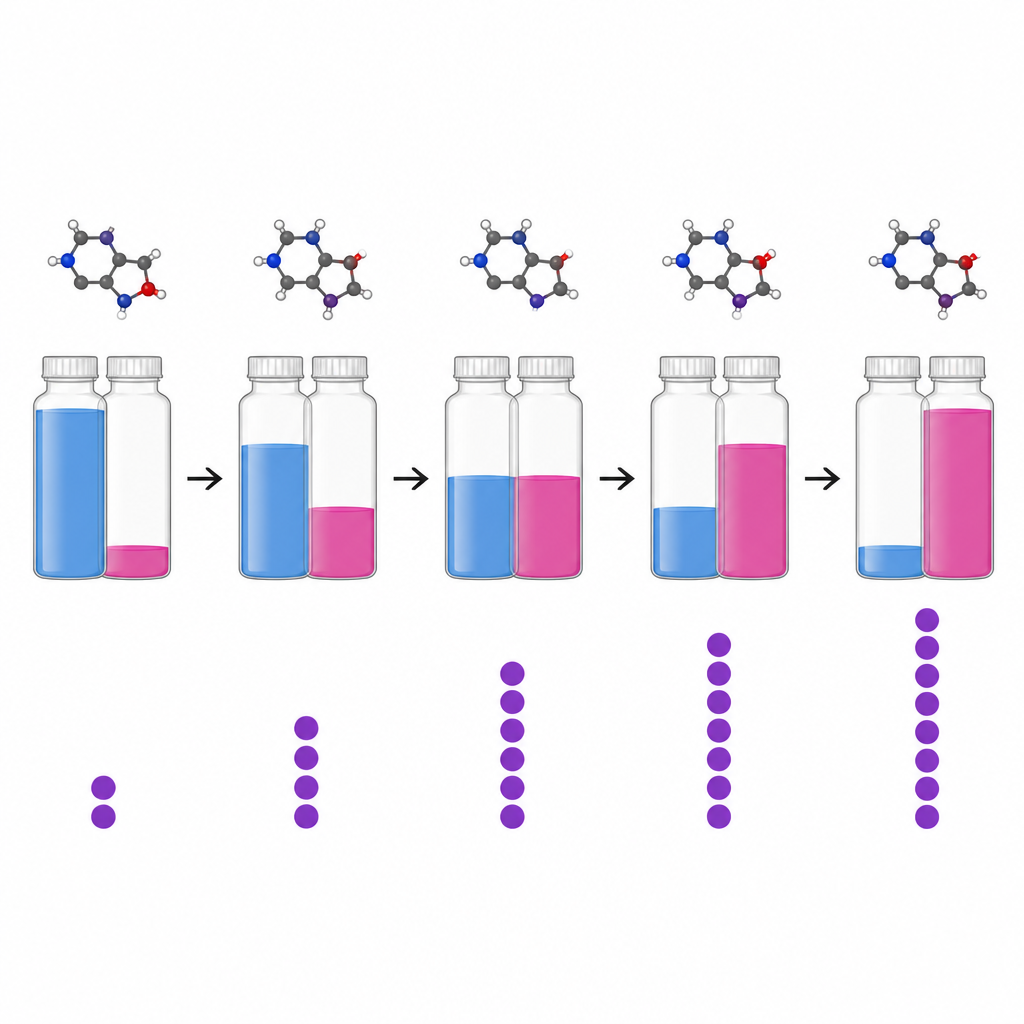
Checking reliability and exploring the dataset
Although the source papers were already peer reviewed, copying so many numbers by hand can introduce mistakes. To reduce this risk, two trained chemists independently extracted the data and a third person compared and merged their results. The team then ran a series of automated checks, looking for impossible values such as solubilities greater than a mole fraction of one or solvent fractions that did not add up correctly, and cross checked temperatures against known boiling points. They also verified literature references using digital object identifiers and resolved inconsistencies where the same name pointed to different structures or vice versa. The resulting dataset, along with a smaller table of solvent boiling points, is publicly available as simple comma separated files and can be browsed through an interactive online tool that allows users to search by compound name or structure and to focus on approved drugs.
What this means for future tools
For chemists and data scientists, MixtureSolDB offers a benchmark resource for building and testing models that predict how much of a compound will dissolve in mixed solvents without doing fresh experiments each time. The large number of data points and wide variety of compounds and solvent pairs help machine learning methods learn more general patterns instead of overfitting to a narrow set of cases. While the authors recommend one logarithmic measure as the most suitable target for comparing different systems, they also provide more practical mass based values for real world planning in the lab. Ultimately, this dataset should help researchers design better reactions, crystallization processes and formulations by giving them faster, more informed ways to choose solvent mixtures.
Citation: Malikov, D., Krasnov, L., Kiseleva, M. et al. Dataset of solubility values for organic compounds in binary mixtures of solvents at various temperatures. Sci Data 13, 727 (2026). https://doi.org/10.1038/s41597-026-07047-z
Keywords: solubility, binary solvent mixtures, machine learning dataset, organic compounds, cheminformatics