Clear Sky Science · en
Wheat historical phenotypic data from European genebanks as an important resource for research and breeding
Why Old Wheat Records Matter Today
Most of the bread, pasta, and cereal we eat comes from just a handful of modern wheat varieties. Yet hidden in seed vaults across Europe are tens of thousands of older and unusual wheat types that may hold traits we urgently need—such as better yield under heat, resistance to new diseases, or good harvests with less fertilizer. This article describes how researchers have rescued decades of scattered field notes about these plants and turned them into a single, high‑quality data resource that breeders and scientists can now use to develop more resilient crops for a changing world.

Seeds in Vaults, Stories in Notebooks
Genebanks are institutions that safeguard seeds from many varieties and wild relatives of crops. For wheat, nine major genebanks in Europe and one international center have quietly built up large collections over many decades. Every so often, they must regrow each seed sample in field plots to replenish stocks. During these grow‑outs, staff routinely record simple observations—when plants form heads, how tall they grow, how heavy the grain is, and other visible traits. These notes were originally collected just to check that each seed lot stayed true to type, but they also captured how thousands of different wheats behave in real fields over more than half a century.
Turning Scattered Notes into Usable Knowledge
Because the plants were only grown when seeds ran low, the resulting records were irregular in time and space—some wheat types were observed many years in a row, others only once. The teams first agreed on common standards for describing experiments and traits so that data from different countries could be compared. They then assembled information from nine genebanks, covering 43,293 wheat samples and 460,399 measurements for 52 traits, with a special focus on three basic ones: time to heading, plant height, and thousand kernel weight (a standard way to describe grain size and density). All data were stored following modern FAIR principles, meaning they are findable, accessible, interoperable, and reusable by others.
Cleaning the Data Without Losing the Wheat
Historical records can be messy: occasional typing mistakes, unusual weather, or mix‑ups in the field can produce misleading numbers. To deal with this, the researchers applied a careful, step‑by‑step cleaning process. They removed clearly impossible values, filtered out entire field campaigns that behaved very erratically, and used statistical models to flag single suspicious data points while keeping as much genuine variation as possible. For each trait and each genebank, they estimated how much of the observed differences between plants is likely due to genetics rather than noise from the environment. These “heritability” values were mostly high, showing that the curated data reliably capture real genetic differences among wheat types.
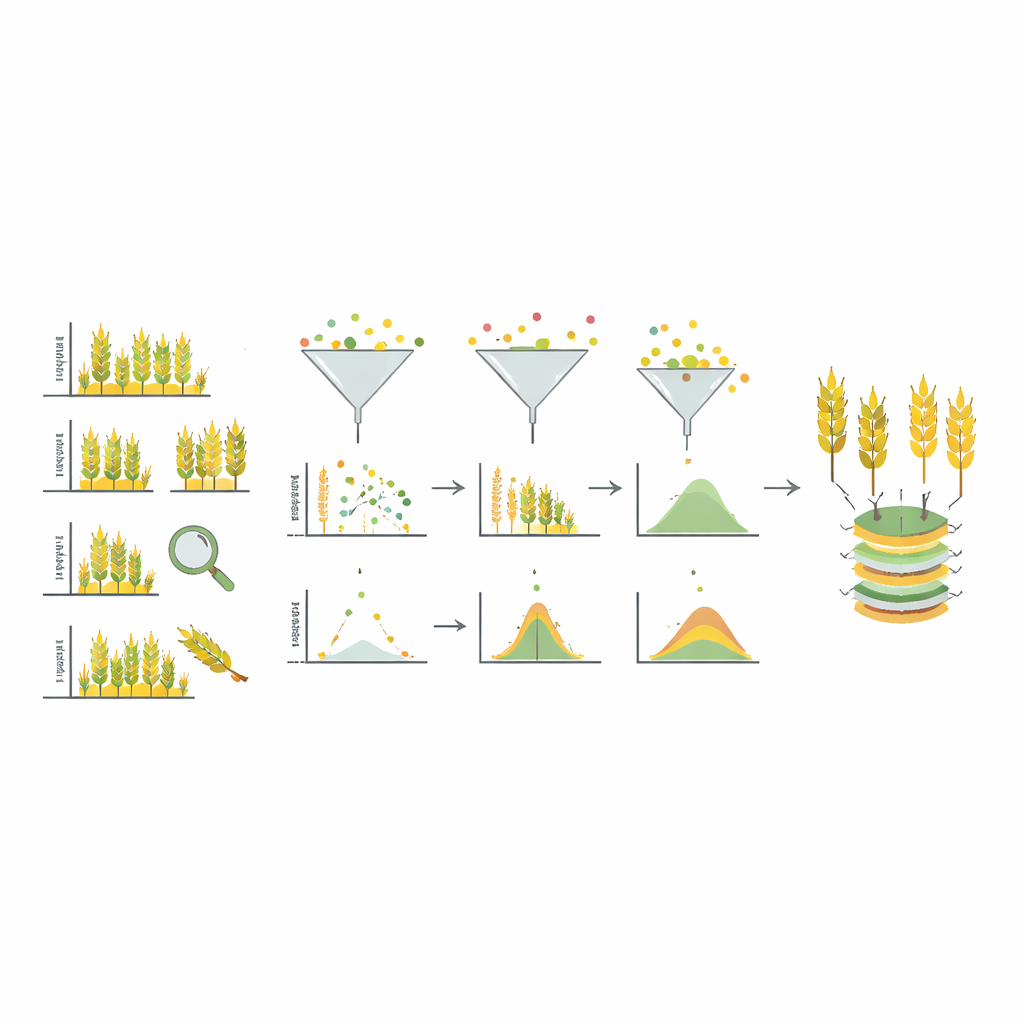
From Static Collections to Living Resources
The final dataset connects each wheat sample to both its background information (such as where it came from and how it is classified) and, for a subset, to DNA marker data. All of this is published in open repositories with stable identifiers, so that any future study can link back to exactly the same plant material. Researchers can now search across countries for wheats that, for example, head early, stay shorter in the field, or produce heavier grains, and then combine this with genetic data to uncover useful genes. The resource also helps genebanks detect duplicates, improve their catalogues, and better manage their collections.
What This Means for Future Harvests
In everyday terms, this work turns dusty paper records and scattered spreadsheets into a powerful map of how tens of thousands of wheat types actually perform in the field. By showing that the measurements are consistent and largely driven by genetics, the study gives plant breeders confidence to mine genebank collections for traits that can strengthen future wheat varieties. As climate change, new pests, and shifting consumer demands put pressure on our food supply, this harmonized historical dataset will help transform genebanks from passive seed stores into active, data‑rich partners in breeding the crops that will fill tomorrow’s bread baskets.
Citation: Le Floch, E., Adam-Blondon, AF., Alaux, M. et al. Wheat historical phenotypic data from European genebanks as an important resource for research and breeding. Sci Data 13, 566 (2026). https://doi.org/10.1038/s41597-026-06908-x
Keywords: wheat genebanks, crop diversity, historical field data, plant breeding, phenotypic databases