Clear Sky Science · de
Verwendung von Machine Learning und Stimme zur Mehrklassenklassifikation von Parkinson, chronisch obstruktiver Lungenerkrankung und gesunden Kontrollpersonen
Die Krankheit durch die menschliche Stimme hören
Die meisten von uns denken selten darüber nach, wie viel unsere Stimme über unseren Gesundheitszustand verrät. Dennoch können subtile Veränderungen in Tonhöhe, Stabilität oder Atemton Hinweise auf Erkrankungen geben, die Gehirn und Lunge betreffen. Diese Studie untersucht, ob eine kurze Aufnahme einer Person, die das Vokal „ah“ ins Smartphone hält, kombiniert mit modernem Machine Learning, dabei helfen kann, Menschen mit Parkinson, solche mit chronisch obstruktiver Lungenerkrankung (COPD) und gesunde ältere Erwachsene auseinanderzuhalten.
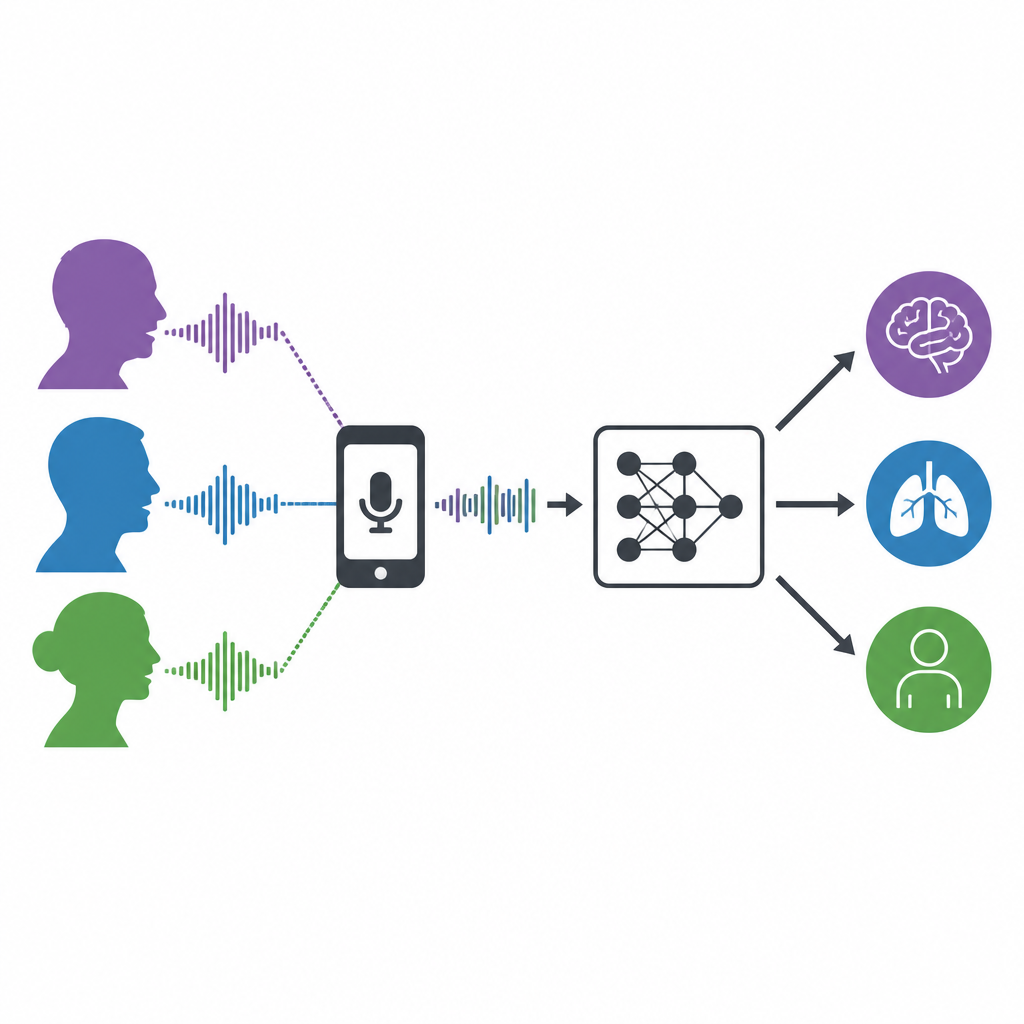
Warum Parkinson und COPD unseren Klang verändern
Parkinson ist am bekanntesten für Tremor und Steifheit, verursacht aber oft auch leisere, monotone und weniger deutliche Sprache. COPD, eine chronische Lungenerkrankung, verengt die Atemwege und erschwert das Atmen, was die Stimme schwach, heiser oder atemlos machen kann. Obwohl beide Erkrankungen die einfache Tonerzeugung stören, fehlen Ärzten noch schnelle und objektive Tests, die auf der Stimme basieren. Die meisten früheren Untersuchungen ließen Computer nur zwischen „krank“ und „gesund“ entscheiden, meist für eine Krankheit und in einer Sprache. Die Autorinnen und Autoren stellten sich stattdessen eine härtere und realistischere Frage: Kann ein einzelnes System sehr einfache Sprachlaute in verschiedenen Sprachen anhören und Menschen gleichzeitig in drei Gruppen sortieren?
Wie die Forschenden Stimmen sammelten und aufbereiteten
Das Team kombinierte zwei große Sprachdatensätze, die auf Mobilgeräten aufgezeichnet wurden. Einer, aus dem mPower-Projekt, enthielt Englisch sprechende Personen mit Parkinson und gesunde Freiwillige. Der andere, COPDVD genannt, enthielt schwedischsprachige COPD-Patienten und passende gesunde Kontrollpersonen. Um die Gruppen vergleichbar zu machen, wählten die Forschenden sorgfältig ähnliche Anzahlen von Männern und Frauen mit ähnlichem Alter und vergleichbarer Anzahl von Aufnahmen aus und kamen so auf 96 Personen und 1.723 nutzbare Aufnahmen des gehaltenen „ah“. Sie entfernten stille Abschnitte und wandelten jede Aufnahme in eine 102-dimensionale Beschreibung um, die grundlegende Stimmmaße wie Tonhöhe und Rauigkeit sowie detaillierte spektrale Fingerabdrücke, die sogenannten Mel-Frequency-Cepstral-Koeffizienten, erfasste.
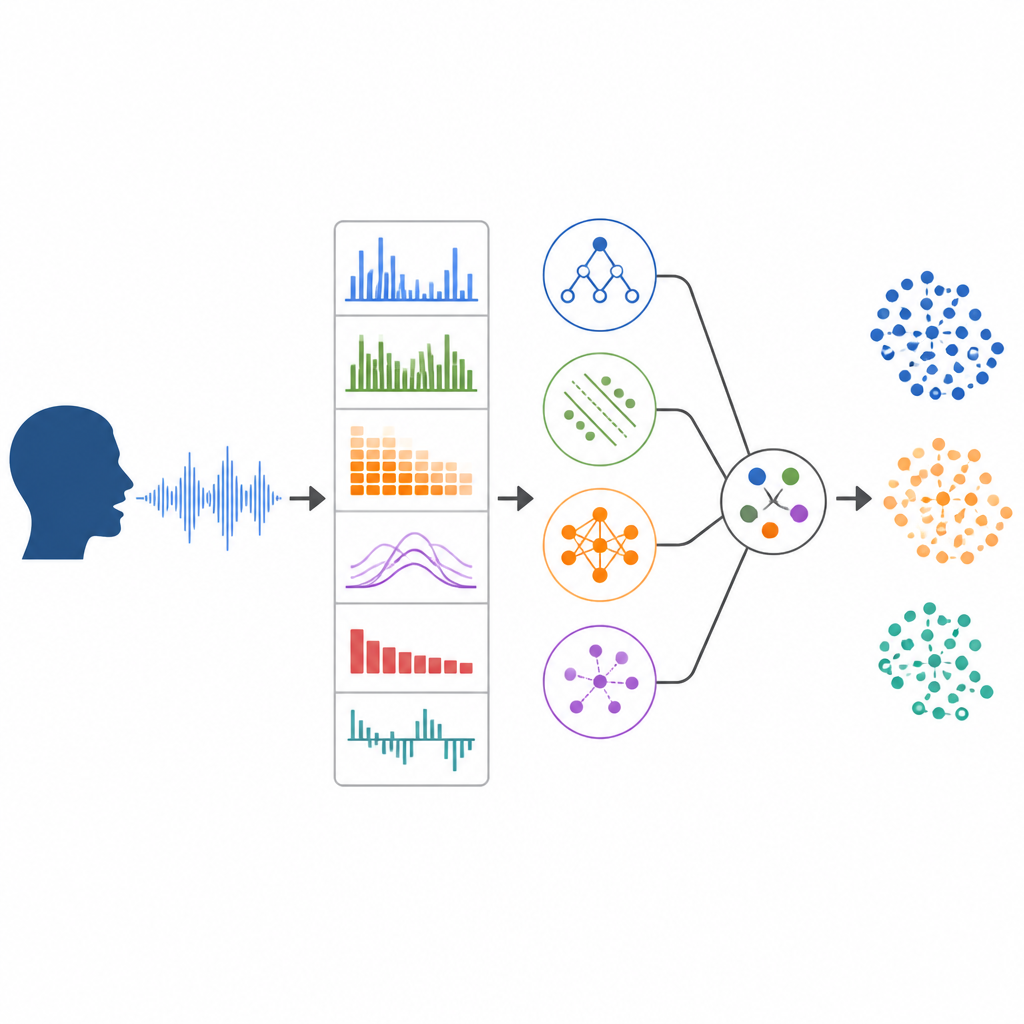
Ein Abstimmungsteam aus Algorithmen anlernen
Anstatt einem einzelnen Machine-Learning-Verfahren zu vertrauen, bauten die Forschenden ein „Abstimmungskomitee“ aus vier verschiedenen Klassifikatoren. Jeder Algorithmus wertete den Merkmalsvektor einer Aufnahme aus und gab seine eigene Vermutung ab, ob die Aufnahme von Parkinson, COPD oder einer gesunden Kontrollperson stammte, zusammen mit einer Wahrscheinlichkeit für jede Option. Diese Wahrscheinlichkeiten wurden dann gemittelt, sodass die finale Entscheidung dem Konsens der Gruppe entsprach. Um Überanpassung zu vermeiden, verwendete das Team eine strikte Trainingsstrategie: Modelle wurden mehrfach auf getrennten Faltungen der Daten abgestimmt und getestet, und die endgültige Leistung wurde an einem vollständig separaten Personensatz bewertet, dessen Aufnahmen die Algorithmen während des Trainings nie gesehen hatten.
Was das System in den Stimmen hörte
Auf diesem unabhängigen Testsatz erreichte das Ensemble eine Gesamtgenauigkeit von etwa 84 Prozent und eine ausgeglichene F1-Score knapp unter 0,84, was bedeutet, dass es über alle drei Gruppen hinweg gut abschnitt, trotz unterschiedlicher Stichprobengrößen. Das System war besonders gut darin, Parkinson zu erkennen, das die höchste Präzision und Sensitivität zeigte. Gesunde Stimmen wurden mit mittlerem Erfolg klassifiziert, während COPD-Stimmen am schwersten zu identifizieren waren und am häufigsten mit gesunden Aufnahmen verwechselt wurden. Auffällig war, dass Parkinson und COPD selten miteinander verwechselt wurden, was darauf hindeutet, dass ihre vokalen Signaturen sich, obwohl beide abweichend sind, in für die Algorithmen detektierbaren Weisen unterscheiden. Als die Forschenden untersuchten, wie Vokale den akustischen „Raum“ ausfüllten, der durch ihre Resonanzfrequenzen definiert ist, fanden sie subtile aber konsistente Verschiebungen und Ausdehnungen zwischen den drei Gruppen, selbst bei unterschiedlichen Sprachen.
Ein Blick in die Black Box
Um nachzuvollziehen, was die Entscheidungen des Systems leitete, nutzte das Team ein modernes Erklärwerkzeug, das jedem Stimmmerkmal einen Einflusswert zuordnet. Sie stellten fest, dass die wichtigsten akustischen Merkmale nicht für jede Gruppe gleich waren. Alter, detaillierte spektrale Formen und tonhöhenbezogene Maße spielten alle eine Rolle, jedoch in unterschiedlichen Kombinationen für Parkinson, COPD und gesunde Kontrollen. Beispielsweise waren bestimmte spektrale Beschreibungen und Formantmuster bei COPD einflussreicher, während bestimmte spektrale und tonhöhenbezogene Hinweise bei Parkinson stärker gewichtet wurden. Dieses Muster deutet darauf hin, dass das Modell wirklich krankheitsspezifische Aspekte der Produktion eines gehaltenen Vokals gelernt hat, statt nur zu erkennen, dass eine Stimme „ungewöhnlich“ klingt.
Was das für die Alltagspflege bedeuten könnte
Vereinfacht gesagt zeigt diese Arbeit, dass ein kurzes, gehaltenes „ah“, auf einem gewöhnlichen Mobilgerät aufgezeichnet, genügend Informationen enthalten kann, damit ein sorgfältig entwickeltes Machine-Learning-System zwischen gehirnbedingten und lungenspezifischen Stimmproblemen sowie normalen altersbedingten Veränderungen unterscheiden kann. Der Ansatz ersetzt keine medizinische Diagnose, und größere, vielfältigere Studien sind nötig, doch er weist in Richtung einer Zukunft, in der schnelle, nichtinvasive Stimmchecks klinische Fachkräfte bei Screening und Monitoring von Menschen mit Parkinson oder COPD unterstützen könnten, sogar über verschiedene Sprachen und Umgebungen hinweg.
Zitation: Idrisoglu, A., Behrens, A. Use of machine learning and voice for multiclass classification of Parkinson’s disease, chronic obstructive pulmonary disease, and healthy controls. Sci Rep 16, 15485 (2026). https://doi.org/10.1038/s41598-026-53409-3
Schlüsselwörter: Parkinson-Krankheit, COPD, Stimmen-Biomarker, Machine Learning, Mobile Health