Clear Sky Science · de
Ein eingebettetes Deep‑Learning‑Framework zur Echtzeit‑Erkennung von Gewalt und Generierung von Alarmen
Warum intelligentere Kameras für die alltägliche Sicherheit wichtig sind
Schlägereien und Übergriffe auf Straßen, in Schulen oder in öffentlichen Verkehrsmitteln spielen sich oft in Sekunden ab, lange bevor menschliche Bediener jeden Überwachungsbildschirm überblicken und Hilfe rufen können. Diese Studie stellt eine Methode vor, mit der kleine, kostengünstige Rechner – Geräte so schlicht wie ein Raspberry‑Pi‑Board – Video in Echtzeit beobachten und automatisch wahrscheinliches gewalttätiges Verhalten markieren können. Indem leistungsfähige Videoanalyse‑Techniken in ein effizientes, geräteinternes System gepackt werden, zeigt die Arbeit, wie bestehende Kameras schnellere, verlässlichere Wächter werden könnten, ohne auf entfernte Rechenzentren oder dauerhafte menschliche Aufsicht angewiesen zu sein.
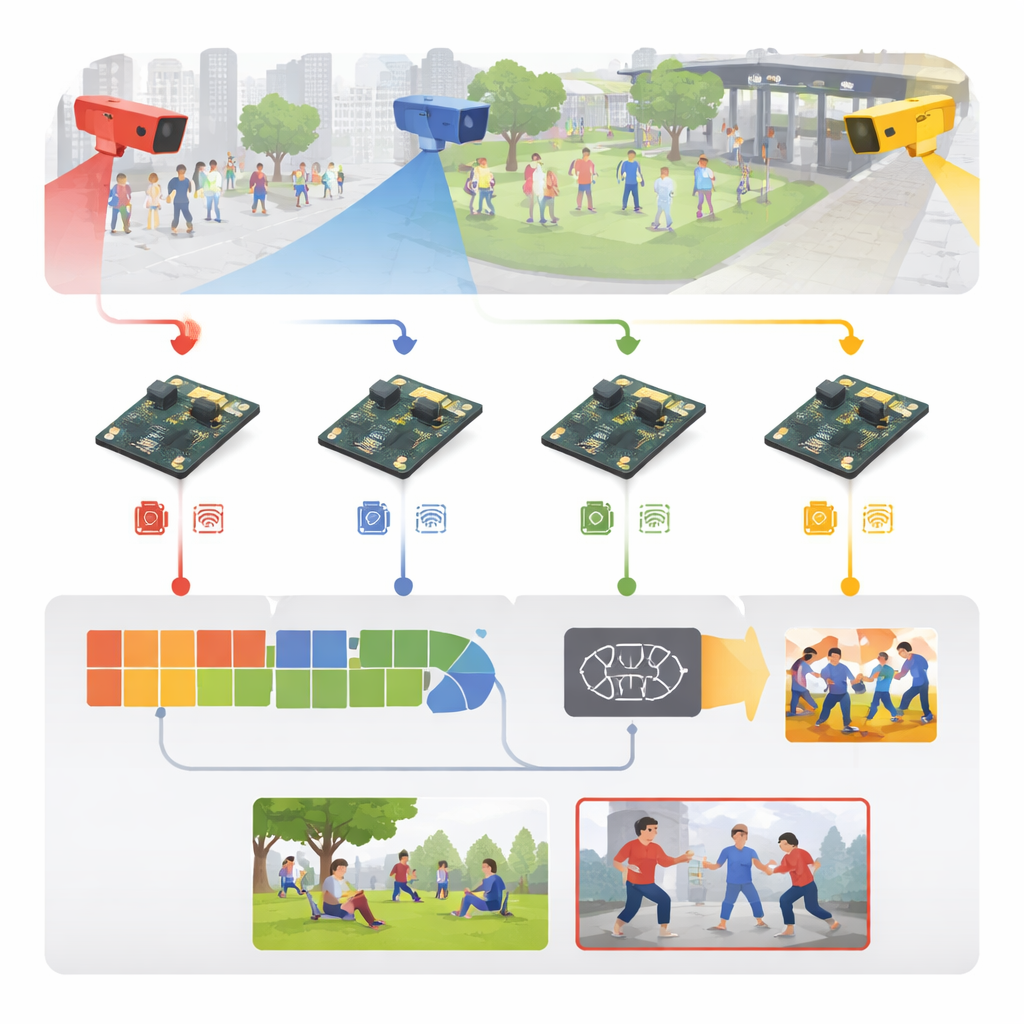
Wie Rohvideo zu Frühwarnsignalen wird
Das System beginnt mit gewöhnlichem Überwachungsmaterial aus Orten wie Sportarenen, Gehwegen, Campuswegen und Innenfluren. Anstatt dieses Video vollständig an einen zentralen Server zu streamen, sendet jede Kamera ihre Bilder direkt an ein nahegelegenes Embedded‑Board. Dort werden die eingehenden Frames vereinheitlicht – skaliert, bereinigt und während des Trainings leicht verändert durch Spiegelungen, Drehungen und Helligkeitsanpassungen – damit das Modell lernt, mit unterschiedlichen Lichtverhältnissen, Blickwinkeln und Personendichten zurechtzukommen. Die Autoren stellen außerdem ein vielfältiges Trainingsset zusammen: fünf bekannte öffentliche Datensätze plus eine neue Sammlung mit sechs Kategorien, die Schläge, Tritte, waffenbezogene Angriffe, Menschenmengen‑Gewalt, Fluchtverhalten und normale Interaktion umfasst.
Wie das kompakte Gehirn im Gehäuse funktioniert
Im Kern des Systems steht eine schlanke zweistufige Lern‑Engine. Zuerst durchsucht ein leichtgewichtiges Bildmodul jedes Einzelbild nach aussagekräftigen visuellen Hinweisen – Körperkonturen, Arm‑ und Beinstellungen sowie Bewegungskanten – unter Verwendung rechensparender Faltungsoperationen, wie sie aus Mobiltelefon‑Visionmodellen bekannt sind. Ein zweites Modul betrachtet dann eine kurze Bildsequenz, um zu verstehen, wie sich diese Hinweise über die Zeit ändern, und erfasst so den Unterschied zwischen etwa einem freundlichen Tipper und einem Schlag. Dies geschieht mit einer effizienten rekurrenten Struktur, die sich jüngere Bewegungen merkt, ohne die Rechenlast größerer Videonetze. Eine einfache Abschlussschicht wandelt dieses Raum‑Zeit‑Verständnis in eine von sechs Aktivitätsklassen um und trennt so gewöhnliche Bewegungen von wahrscheinlicher Aggression.
Deep Learning auf einem kleinen, stromsparenden Board unterbringen
Ein cleveres Modell zu entwerfen ist nur die halbe Miete; die eigentliche Herausforderung ist, es schnell auf einem handflächengroßen Computer laufen zu lassen. Die Autoren behandeln das gesamte System wie eine Ingenieur‑Pipeline: Sie beginnen mit einer auf einer leistungsfähigen Grafik‑Workstation trainierten Version, konvertieren sie dann in ein portables Format und schrumpfen sie aggressiv. Die numerische Genauigkeit wird reduziert, sodass Gewichte nur noch ein Viertel des ursprünglichen Speichers benötigen, und nicht benötigte Teile des Netzes werden beschnitten. Mit spezialisierten Optimierungstools außerhalb des Geräts erzeugen sie ein getuntes Modell, das auf dem Raspberry Pi mit einer optimierten Laufzeitumgebung effizient ausgeführt werden kann. Das Ergebnis ist ein System, das etwa 26 Videobilder pro Sekunde mit einer Verzögerung von rund 38 Millisekunden pro Frame verarbeitet und dabei nur wenige Watt verbraucht – schnell und sparsam genug für den Dauerbetrieb im Feld.

Tests, Vertrauen und Grenzen maschineller Urteile
Um zu prüfen, ob ihr kompakter Beobachter sowohl genau als auch verlässlich ist, unterziehen die Forschenden ihn einer Reihe von Tests. Über Benchmark‑Sammlungen von Hockeyhallen bis zu Stadtstraßen und auf ihrem eigenen Sechs‑Klassen‑Datensatz beschriftete das System Ereignisse in etwa 97 von 100 Fällen korrekt und zeigte ein gutes Gleichgewicht zwischen dem Erfassen gewalttätiger Handlungen und dem Vermeiden falscher Alarme. Vergleiche mit aufwendigeren Videomodellen – wie vollständigen 3‑D‑Faltungsnetzen und transformerbasierten Entwürfen – zeigten, dass dieser schlankere Ansatz deren Genauigkeit erreichen oder übertreffen kann, während er deutlich weniger Rechenressourcen benötigt. Das Team visualisierte zudem, wohin das Modell in jedem Frame „blickt“ und stellte fest, dass seine Aufmerksamkeit natürlicherweise auf bewegte Gliedmaßen und enge Kontakte zwischen Personen zentriert ist, statt auf irrelevante Hintergrunddetails, was Vertrauen in seine Entscheidungen stärkt.
Was das für sicherere, intelligentere Räume bedeutet
Die Hauptaussage der Studie ist nicht, dass eine völlig neue Art von neuronalen Netz erfunden wurde, sondern dass gezeigt wurde, wie bewährte Techniken zu einem praktischen, Echtzeit‑Werkzeug für bescheidene Hardware verpackt werden können. Durch das sorgfältige Austarieren von Modellarchitektur, Datenvorbereitung und Komprimierung zur Einsatzzeit liefern die Autoren ein eingebettetes System, das Live‑Video überwachen, wahrscheinliche Gewalt erkennen und mit geringer Verzögerung und niedrigem Energieverbrauch Alarm schlagen kann. Sie benennen auch offene Herausforderungen: Das System kann bei schlechter Beleuchtung, dichtem Gedränge oder schnellen, sportartigen Bewegungen noch fehlgehen, und jede solche Technologie muss mit Blick auf Privatsphäre, Verzerrungen und menschliche Aufsicht eingesetzt werden. Dennoch weist die Arbeit auf eine Zukunft, in der viele gewöhnliche Kameras mit kleinen, leisen Rechnern gekoppelt sind, die helfen, Gefahren früher zu erkennen und schneller sowie besser informierte Reaktionen zu ermöglichen.
Zitation: Salman, M., Abbas, N., ur Rahman, S.I. et al. An embedded deep learning framework for real-time violence detection and alert generation. Sci Rep 16, 10805 (2026). https://doi.org/10.1038/s41598-026-44939-x
Schlüsselwörter: Gewalterkennung, eingebettete Bildverarbeitung, Edge‑KI, Videoüberwachung, Deep Learning