Clear Sky Science · de
Ein neuartiger verteilter Gradientenalgorithmus für zusammengesetzte, beschränkte Optimierung über gerichtete Netzwerke
Intelligentere Entscheidungsfindung ohne zentralen Chef
Moderne Technologien — von Stromnetzen und Sensornetzwerken bis zu Drohnenflotten — beruhen häufig auf vielen Geräten, die zusammenarbeiten, ohne einen einzelnen zentralen Kontrolleur. Jedes Gerät sieht nur einen Teil des Gesamtbildes, trotzdem muss die gesamte Gruppe sich auf einen guten, sicheren Betriebszustand einigen. Dieses Papier stellt eine neue Methode vor, mit der solche verteilten Systeme effizient und zuverlässig gemeinsame Entscheidungen treffen können, selbst wenn die zugrundeliegenden Kommunikationsverbindungen einseitig sind und das Problem schwierige Nebenbedingungen und scharfe „Kostenkanten" enthält.
Warum viele kleine Gehirne ein großes übertreffen
Zentralisierte Optimierung — bei der ein leistungsfähiger Rechner alle Daten sammelt, ein großes Problem löst und Befehle zurücksendet — ist anfällig und schwer skalierbar. Fällt die zentrale Einheit aus, oder treten Kommunikationsverzögerungen in großen Systemen auf, kann sie versagen. Verteilte Optimierung kehrt dieses Bild um: Jeder Knoten (oder Agent) behält seine eigenen Daten, aktualisiert seine lokale Entscheidung und tauscht nur begrenzte Informationen mit benachbarten Knoten aus. Die Herausforderung besteht darin, Update‑Regeln so zu entwerfen, dass trotz teilweiser und einseitiger Kommunikation alle Knoten dennoch eine Lösung finden, die global optimal für das Netzwerk ist.
Schwierige Probleme mit scharfen Kanten und realen Beschränkungen
Die Autoren konzentrieren sich auf eine anspruchsvolle Klasse von Problemen, bei denen die Gesamtkosten glatte Terme (die sich langsam ändern) mit nichtglatten Termen (die scharfe Knicke erzeugen können), etwa der verbreiteten l1‑Norm, kombinieren. Diese nichtglatten Anteile sind wichtig, um Sparsität und Robustheit in Anwendungen wie komprimierter Abtastung, Signalrauschunterdrückung und Modellanpassung zu fördern. Darüber hinaus muss jeder Knoten lokale Gleichungs‑ und Ungleichungsnebenbedingungen sowie zulässige Schranken einhalten. All dies muss über ein gerichtetes Kommunikationsnetzwerk gehandhabt werden, in dem Information von Knoten A zu Knoten B fließen kann, aber nicht notwendigerweise zurück. Bestehende Methoden gehen typischerweise von ungerichteten Verbindungen, einfacheren Nebenbedingungen oder festen Schrittweiten aus, die schwer einzustellen und weniger flexibel sind.
Eine neue Art, wie Knoten kommunizieren und sich einigen
Um diese Schwierigkeiten zu meistern, schlägt das Papier einen neuen verteilten, gradientenbasierten Algorithmus vor, der auf zusammengesetzte, beschränkte Probleme über gerichtete Netzwerke zugeschnitten ist. Jeder Knoten passt wiederholt seine lokale Entscheidung mittels eines projizierten Gradientenschritts an: Er bewegt sich in eine Richtung, die die Gesamtkosten senkt, und projiziert das Ergebnis dann zurück in seinen zulässigen Bereich, sodass die Nebenbedingungen erfüllt bleiben. Zusätzliche Variablen fungieren als interne Buchführung und helfen dem Netzwerk, Gleichungen und Ungleichungen durchzusetzen und den nichtglatten l1‑Term zu behandeln. Eine wichtige Innovation ist ein Korrekturmechanismus, der das durch einseitige Verbindungen verursachte Ungleichgewicht ausgleicht und dabei nur zeilenstochastische Gewichte verwendet — das heißt, jeder Knoten muss nur wissen, wie er Informationen empfängt, nicht, an wen er Informationen sendet.
Flexible Schrittweiten mit garantierter Konvergenz
Ein weiteres Kennzeichen der Methode ist die Verwendung zeitveränderlicher, aber konstanter Schrittweiten: Jeder Knoten kann seine eigene Schrittweite innerhalb eines nachweislich sicheren Bereichs wählen, anstatt einen einzigen festen Wert zu teilen. Diese Flexibilität erleichtert das Abstimmen in der Praxis und erlaubt dem Algorithmus, sich besser an unterschiedliche lokale Bedingungen anzupassen. Mithilfe von Stabilitätstheorie konstruieren die Autoren eine Lyapunov‑Funktion — eine Art mathematisches Energimaß — und beweisen, dass diese bei jeder Iteration abnimmt, solange die Schrittweiten eine klare obere Schranke respektieren. Dadurch ist garantiert, dass alle lokalen Entscheidungen von jedem Startpunkt aus zu derselben global optimalen Lösung konvergieren, selbst bei nichtglatten Termen und gemischten Nebenbedingungen.
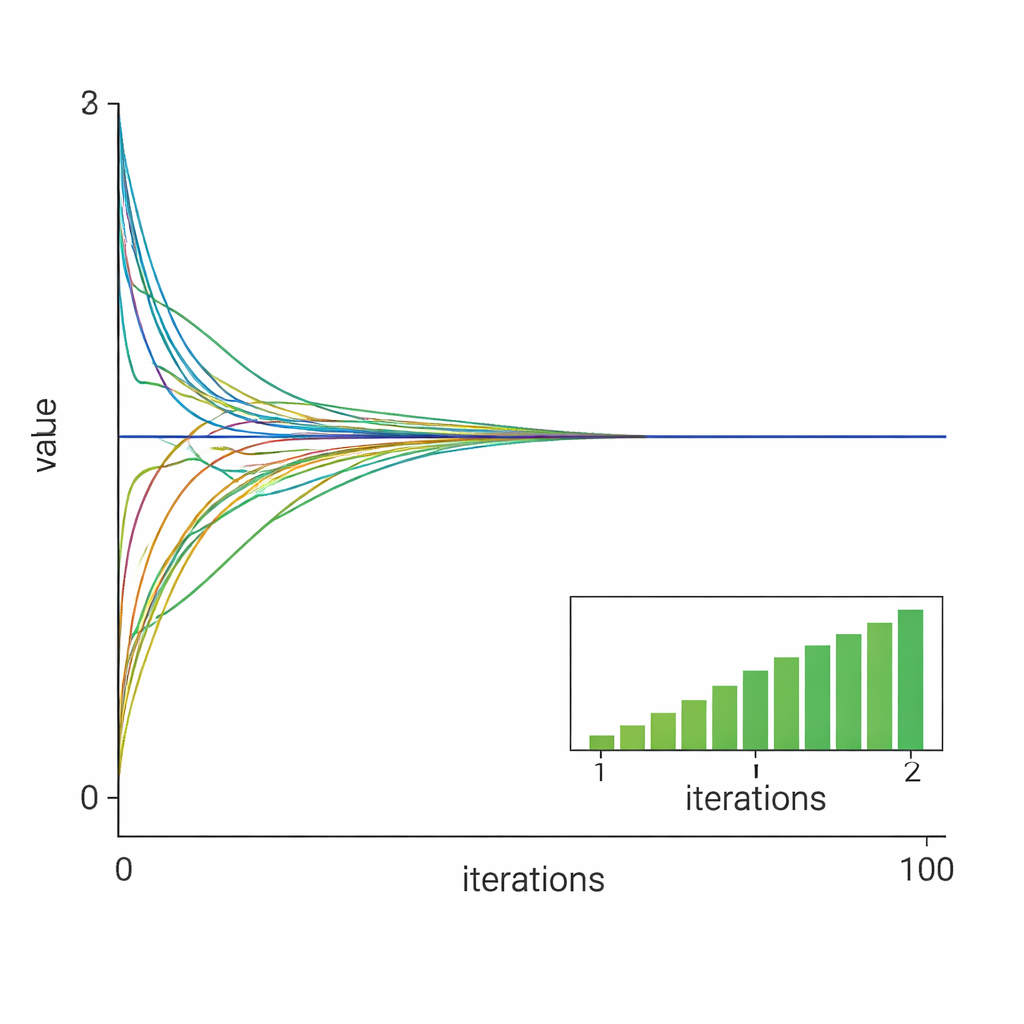
Prüfung der Methode in der Praxis
Die Forschenden validieren ihre Theorie mit zwei numerischen Fallstudien. Im ersten Fall lösen zehn Knoten gemeinsam ein beschränktes quadratisches Problem mit l1‑Regularisierung, ähnlich Aufgaben in Ressourcenverteilung oder Sensorfusion. Die Ergebnisse zeigen, dass sich alle lokalen Variablen schnell an die zentralisierte optimale Lösung anpassen und dass die Verwendung einer passend gewählten konstanten Schrittweite zu schnellerer, nahezu linearer Konvergenz führt im Vergleich zu einer abnehmenden Schrittweite. Im zweiten Fall geht die Methode ein schlecht konditioniertes Problem der kleinsten absoluten Abweichungen an, das für Standardlöser als schwierig bekannt ist. Selbst hier lenkt der Algorithmus mit nur fünf Knoten und stark unausgewogenen Daten alle Agenten zuverlässig zur wahren Lösung.
Was das für reale Systeme bedeutet
Kurz gesagt liefert das Papier ein robustes Rezept dafür, wie Gruppen vernetzter Geräte schwierige Optimierungsprobleme gemeinsam lösen können, ohne einen Master‑Controller, während sie praktische Schranken einhalten und über einseitige Kommunikationsverbindungen arbeiten. Die Methode lässt sich auf Energiesysteme, Sensornetzwerke und verteilte maschinelle Lernaufgaben anwenden, bei denen Nebenbedingungen und Sparsität eine Rolle spielen. Da sie nur Informationen von Nachbarn benötigt und klare Regeln zur Wahl der Schrittweiten bietet, ist sie gut für reale Einsätze geeignet. Die Autoren empfehlen, den Ansatz als Nächstes auf zeitvariierende Netzwerke zu erweitern, um noch näher an realistische, sich ständig ändernde Kommunikationsumgebungen heranzurücken.
Zitation: Ou, M., Zhang, H., Yan, Z. et al. A novel distributed gradient algorithm for composite constrained optimization over directed network. Sci Rep 16, 5185 (2026). https://doi.org/10.1038/s41598-026-36058-4
Schlüsselwörter: verteilte Optimierung, gerichtete Netzwerke, Multi‑Agenten‑Systeme, sparsame Regularisierung, konvexe Probleme mit Nebenbedingungen