Clear Sky Science · ar
إطار تعلم عميق مضمّن للكشف عن العنف في الوقت الحقيقي وتوليد التنبيهات
لماذا تهم الكاميرات الأذكى للسلامة اليومية
المشاجرات والاعتداءات في الشوارع والمدارس ووسائل النقل العام غالبًا ما تتكشف في ثوانٍ، قبل أن يتمكن المشغّلون البشريون من مسح كل شاشات المراقبة وطلب المساعدة. تقدم هذه الدراسة طريقة لأجهزة صغيرة ومنخفضة التكلفة — أجهزة متواضعة بحجم لوحة Raspberry Pi — لمراقبة الفيديو في الوقت الحقيقي ووضع علامات تلقائية على السلوك العنيف المحتمل. من خلال ضم تقنيات تحليل الفيديو القوية في نظام فعّال يعمل محليًا على الجهاز، تُظهر الدراسة كيف يمكن للكاميرات الحالية أن تصبح حراسًا أسرع وأكثر موثوقية دون الاعتماد على مراكز بيانات بعيدة أو على الانتباه البشري المستمر.
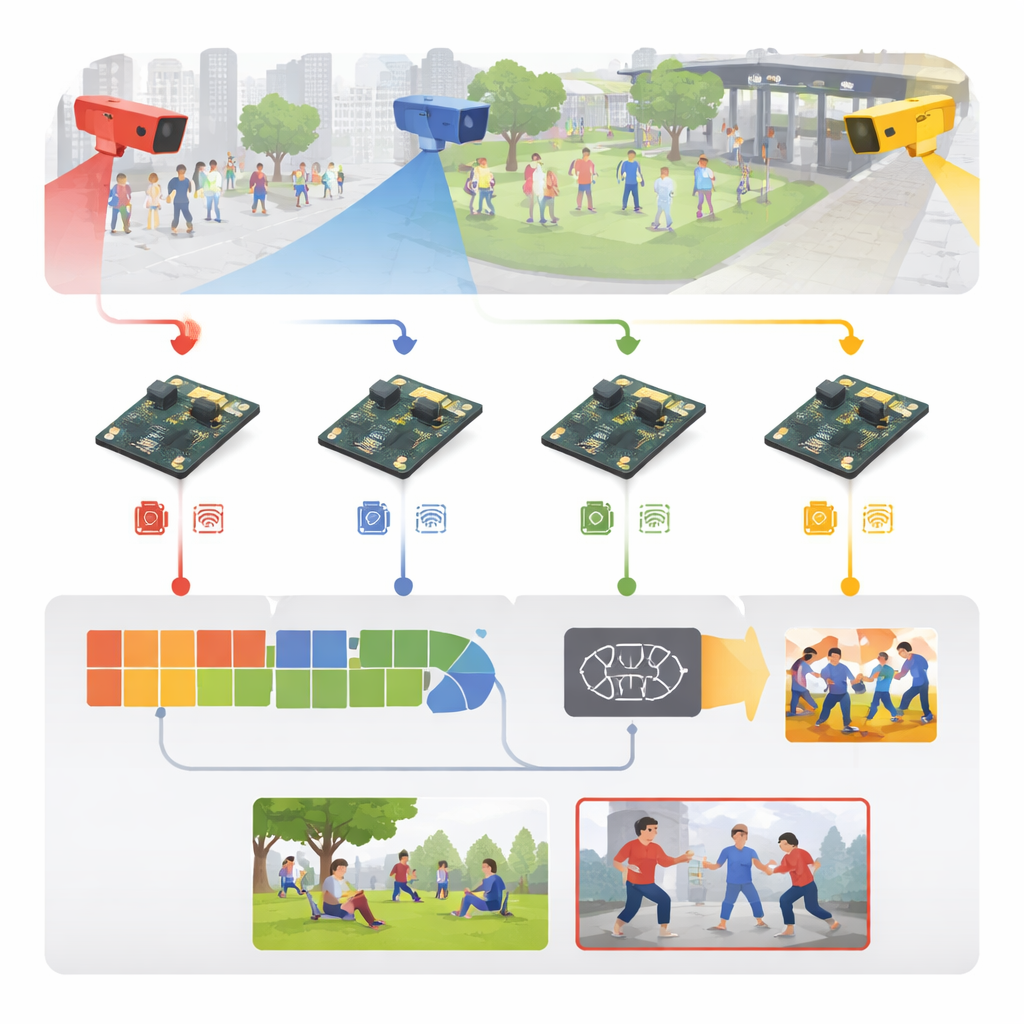
تحويل الفيديو الخام إلى إشارات تحذيرية مبكرة
يبدأ النظام بلقطات مراقبة عادية من أماكن مثل الملاعب والأرصفة والممرات الجامعية والممرات الداخلية. بدلًا من بث كل هذا الفيديو إلى خادم مركزي، ترسل كل كاميرا إطاراتها مباشرة إلى لوحة مضمّنة قريبة. هناك، تُموّحد الإطارات الواردة — تُعاد تغيير الحجم، تُنظف، وتُجرى عليها تغييرات طفيفة مثل قلب الصورة، والدوران، وتعديل السطوع أثناء التدريب — حتى يتعلم النموذج التكيّف مع ظروف إضاءة وزوايا رؤية وكثافات حشد مختلفة. كما أن المؤلفين يبنون مزيجًا غنيًا من مواد التدريب: خمس مجموعات بيانات عامة معروفة بالإضافة إلى مجموعة جديدة من ست فئات تتضمن اللكم والركل والهجمات المتعلقة بالأسلحة والعنف الجماعي والجري والتفاعل العادي.
كيف يعمل «الدماغ» المدمج داخل الصندوق
في قلب النظام محرك تعلّم مكوّن من مرحلتين مبسّطتين. أولًا، يفحص موديل صور خفيف الوزن كل إطار بحثًا عن دلائل بصرية — مثل خطوط الجسم ووضعية الذراعين والساقين وحواف الحركة — باستخدام عمليات التلافيف الموفّرة للتكلفة والمستعارة من نماذج رؤية الهواتف المحمولة. ثم تنظر وحدة ثانية عبر تسلسل قصير من الإطارات لتفهم كيف تتغير تلك الدلائل عبر الزمن، ما يلتقط الفرق بين مثال لطيف مثل ربّتة ودية وبين لكمة. يتم ذلك بهيكل تكراري فعّال يتذكر الحركة الأخيرة دون العبء الحاسوبي الثقيل لشبكات الفيديو الأكبر. تحول طبقة نهائية بسيطة هذا الفهم الزماني-المكاني إلى إحدى تسميات الأنشطة الست، فتميّز الحركة العادية عن العدوان المحتمل.
ملاءمة التعلّم العميق على لوحة صغيرة منخفضة الطاقة
تصميم نموذج ذكي هو نصف القصة فقط؛ أما جعلَه يعمل بسرعة على كمبيوتر بحجم الكف فالتحدي الحقيقي. يعامل المؤلفون النظام بأكمله كسلسلة هندسية: يبدأون بإصدار مُدرّب على محطة رسومات قوية، ثم يحوّلونه إلى صيغة محمولة ويقلّصونه بشكلٍ حاد. تُخفّض دقة الأرقام بحيث تشغل الأوزان ربع الذاكرة الأصلية، وتُقلم الأجزاء غير الضرورية من الشبكة. باستخدام أدوات تحسين متخصّصة خارج الجهاز، ينتجون نموذجًا مُعدّلًا يمكن تنفيذه بكفاءة على Raspberry Pi باستخدام وقت تشغيل مُحسّن. النتيجة نظام يعالج نحو 26 إطار فيديو في الثانية مع تأخير يقارب 38 ملّي ثانية لكل إطار، كل ذلك بينما يستهلك بضعة واطات فقط — سريع واقتصادي بما يكفي للعمل المستمر في الميدان.

الاختبار والثقة وحدود حكم الآلة
لفحص ما إذا كان المراقب المدمج دقيقًا وموثوقًا، وضعه الباحثون في سلسلة من الاختبارات. عبر مجموعات مرجعية من حلبات الهوكي إلى شوارع المدينة، وعلى مجموعة البيانات ذات الست فئات الخاصة بهم، صنّف النظام الأحداث بشكل صحيح في نحو 97 من كل 100 حالة وأظهر توازنًا قويًا بين التقاط الأفعال العنيفة وتجنّب الإنذارات الكاذبة. أظهرت المقارنات مع نماذج فيديو أكثر تفصيلاً — مثل الشبكات الالتفافية ثلاثية الأبعاد الكاملة والتصاميم القائمة على المحولات — أن هذا النهج الأخف قادر على مساواة دقتها أو التفوق عليها مع استخدام حوسبة أقل بكثير. كما بصّر الفريق أماكن «نظر» النموذج داخل كل إطار، فوجدوا أن تركيزه يتركز بطبيعة الحال على الأطراف المتحركة والاحتكاكات القريبة بين الأشخاص، بدلاً من تفاصيل الخلفية غير ذات الصلة، مما يساعد على بناء الثقة في قراراته.
ماذا يعني هذا لمساحات أكثر أمانًا وذكاءً
الرسالة الرئيسية للدراسة ليست أنها اخترعت نوعًا جديدًا كليًا من الشبكات العصبية، بل أنها أظهرت كيفية تعبئة تقنيات مثبتة في أداة عملية تعمل في الوقت الحقيقي على معدات متواضعة. من خلال الموازنة بعناية بين تصميم النموذج وإعداد البيانات وضغطه وقت النشر، يقدم المؤلفون نظامًا مضمّنًا يمكنه مراقبة الفيديو الحي، والتعرّف على العنف المحتمل، وإطلاق التنبيهات بزمن استجابة منخفض وباستهلاك طاقة قليل. كما يعترفون بالتحديات المفتوحة: لا يزال النظام عرضة للخلل بسبب الإضاءة الضعيفة والمشاهد المزدحمة أو الحركة السريعة الشبيهة بالرياضة، ويجب نشر أي تقنية من هذا النوع مع مراعاة الخصوصية والتحيّز والإشراف البشري. ومع ذلك، تشير هذه العمل إلى مستقبل قد تقترن فيه العديد من الكاميرات العادية بأجهزة صغيرة وهادئة تساعد على اكتشاف الخطر مبكرًا ودعم استجابات أسرع وأفضل اطلاعًا.
الاستشهاد: Salman, M., Abbas, N., ur Rahman, S.I. et al. An embedded deep learning framework for real-time violence detection and alert generation. Sci Rep 16, 10805 (2026). https://doi.org/10.1038/s41598-026-44939-x
الكلمات المفتاحية: كشف العنف, رؤية مضمّنة, الذكاء الاصطناعي على الحافة, مراقبة الفيديو, التعلّم العميق