Clear Sky Science · ar
تحليل مشاعر تقييمات الفنادق عبر لغات متعددة بواسطة التعلم الاتحادي متعدد الوكلاء وشبكات الانتباه الرسومية غير المتجانسة
لماذا تهم تقييمات الفنادق على الإنترنت
أصبح اختيار فندق يبدأ في الغالب بتصفح تعليقات المسافرين الآخرين. تأتي هذه التقييمات بعدة لغات ومن مواقع كثيرة، ويمكن أن تصنع الفارق في سمعة الفندق وإيراداته. تصف هذه الورقة نظامًا جديدًا يقرأ تقييمات الفنادق بعدة لغات في آن واحد، ويكشف ما إذا كانت إيجابية أم سلبية، وينبه مديري الفنادق مبكرًا عندما تكون سمعتهم على وشك التغير — وكل ذلك مع إبقاء بيانات النزلاء مخزنة بأمان حيث كُتبت.
لغات ومنصات متعددة، مشكلة واحدة
اليوم ينشر المسافرون تقييمات بالإنجليزية والصينية والفرنسية والألمانية وأنماط لغوية مختلطة عبر مواقع الحجز مثل Booking.com وTripAdvisor وAgoda وCtrip. غالبًا ما تقوم الأدوات الحالية بترجمة كل شيء إلى لغة واحدة ثم تحليله، مما قد يشوه المعنى، لا سيما في اللغات الصغيرة أو الخاصة ثقافيًا. أدوات أخرى ترسل كل نص التقييمات إلى خادم مركزي واحد، ما يثير مخاوف خصوصية ويتعارض مع قوانين حماية البيانات الصارمة. النتيجة أن الفنادق قد تفوت تحولات دقيقة في رضا الضيوف أو تفشل في ملاحظة هجمات منسقة من التقييمات المزيفة في الوقت المناسب للاستجابة.
التعاون دون مشاركة البيانات الخام
يقترح المؤلفون إعدادًا "اتحاديًا" حيث يقوم كل زوج موقع‑لغة مشارك بتشغيل وكيل برمجي محلي خاص به. تتعلم هذه الوكلاء من تقييماتهم المحلية، لكن بدلًا من إرسال النص الخام إلى محور مركزي، يشاركون فقط تحديثات رياضية لنموذج مشترك. تجمع طبقة تنسيق هذه التحديثات وترسل نموذجًا محسنًا مرة أخرى إلى جميع الشركاء. تدابير حماية إضافية، مثل إضافة ضوضاء محسوبة بعناية وتشفير التحديثات، تجعل من الصعب للغاية على أي شخص إعادة بناء ما كتبه ضيف بعينه. يتيح هذا التصميم للنظام التعلم من 154,680 تقييمًا عبر أربع لغات مع الامتثال لأنظمة الخصوصية الحديثة.
رؤية التقييمات كشبكة حيّة
بدلًا من التعامل مع كل تقييم كوحدة نصية معزولة، يحول النظام كون التقييمات كله إلى شبكة غنية. في هذه الشبكة، تمثل العقد الضيوف والفنادق والتقييمات واللغات ونقاط الزمن، وتلتقط الروابط من بقي أين أقام، ومتى كتب، وبأي لغة. ثم يقوم نوع خاص من الشبكات العصبية "بالنظر" عبر هذا النسيج، مع إيلاء اهتمام أكبر للروابط الأكثر معلوماتية، مثل المراجعين الموثوقين أو الأنماط المتكررة في لغة معينة. تتيح هذه المقاربة للنموذج التقاط الإشارات العالمية ("موقع ممتاز"، "غرفة غير نظيفة") والعبارات أو العادات الخاصة بكل لغة التي غالبًا ما تفوتها النماذج متعددة اللغات الاعتيادية.
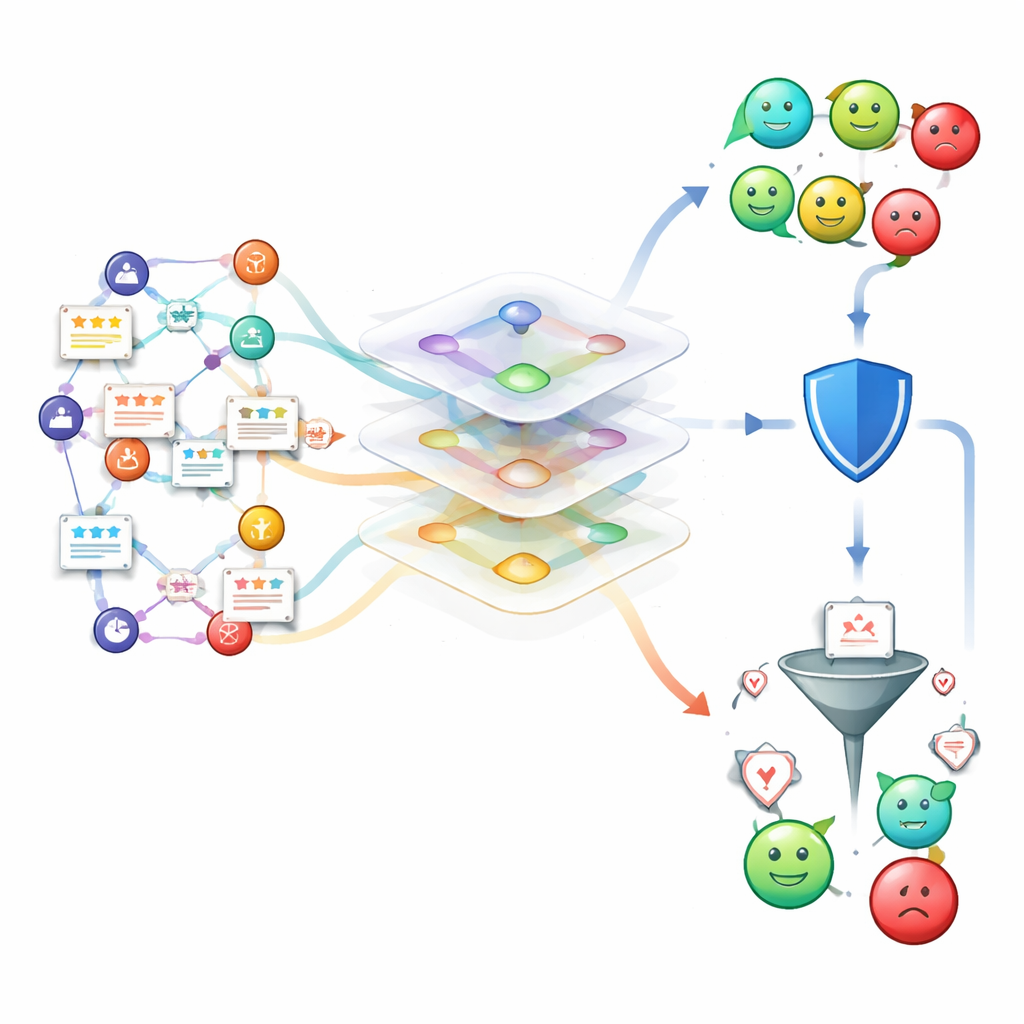
من درجات المشاعر إلى رصد السمعة والتنبيهات بالتقييمات المزيفة
فوق هذا المحرك متعدد اللغات، يبني المؤلفون مراقب سمعة يتتبع كيف يتغير موقف الفندق بمرور الوقت. يبحث النظام عن ارتفاعات حادة في التعليقات السلبية، وتحسنات بطيئة لكنها متواصلة بعد تحديثات الخدمة، واندفاعات غير معتادة في النشاط قد تشير إلى تلاعب منظم. يحلل أسلوب الكتابة والتوقيت وسلوك المراجع لتصفية التقييمات المزيفة أو المشبوهة، ويحدث درجة سمعة الفندق في الزمن القريب الحقيقي. في الاختبارات، حدد النظام التقييمات المزيفة بدقة تزيد على 93% وكان قادرًا على الإشارة إلى تحولات كبيرة في السمعة، في المتوسط، قبل نحو ثلاثة أيام فقط من ظهورها بوضوح في صفحات التقييم العامة.
ماذا يعني هذا للمسافرين والفنادق
بالنسبة للقارئ العام، الخلاصة أن هناك الآن إمكانية دمج التقييمات من لغات ومنصات متعددة في صورة موحدة لوعي الخصوصية عن جودة الفندق. يصنف النظام المقترح مشاعر التقييم بدقة أعلى من نماذج اللغة الرائدة، ويعالج البيانات بعناية أكثر من الخدمات المركزية، ويكشف كلًا من المشكلات الحقيقية وأنماط التقييم المشبوهة مبكرًا أكثر من الأدوات التقليدية. عمليًا، يعني هذا أن المسافرين يمكنهم الاعتماد على تقييمات وملخّصات أكثر موثوقية، بينما تحصل الفنادق على لوحة تحكم إنذار مبكر تشجعها على إصلاح المشكلات بسرعة والرد على الضيوف بشكل أكثر فعالية — كل ذلك دون كشف بيانات التقييم الشخصية خارج المكان الذي نُشرت فيه أصلاً.
الاستشهاد: Han, X. Cross-language hotel review sentiment analysis via multi-agent federated learning with heterogeneous graph attention networks. Sci Rep 16, 12681 (2026). https://doi.org/10.1038/s41598-026-41500-8
الكلمات المفتاحية: تقييمات الفنادق, تحليل المشاعر, التعلم الاتحادي, كشف التقييمات المزيفة, السمعة الإلكترونية