Clear Sky Science · zh
使用开源生成式人工智能与机器学习进行主题分析:一种用于归纳性定性编码簿开发的新方法
这对日常问题为何重要
无论人们填写调查问卷还是回答访谈问题,他们都会留下关于工作、学校、健康或社区生活的丰富叙述。阅读几十个回答并不难;但要理解成千上万条回答则并非易事。本文描述了一种新方法,帮助研究者利用开源人工智能来梳理大量书面评论并提取主要观点,同时仍由人类来主导解释。目标是使细致、具有微妙区别的定性研究在通常仅适用于大数据统计的规模上也成为可能。
更智能地阅读数千条评论
作者关注一种在社会科学中广泛使用的方法——主题分析,在该方法中,研究者阅读文本并寻找反复出现的模式或能够回答研究问题的“主题”。传统上,这意味着逐条手工为每个评论编码并构建编码簿——一个结构化的主题与子主题列表。对于几十次访谈这一过程可以行得通,但当面对数万条开放性回答时就变得难以承受。文章提出:可否使用免费可得的生成式文本模型和其他开源工具来辅助完成这些早期、重复性的工作,而不取代人工判断?
介绍 GATOS 工作流程
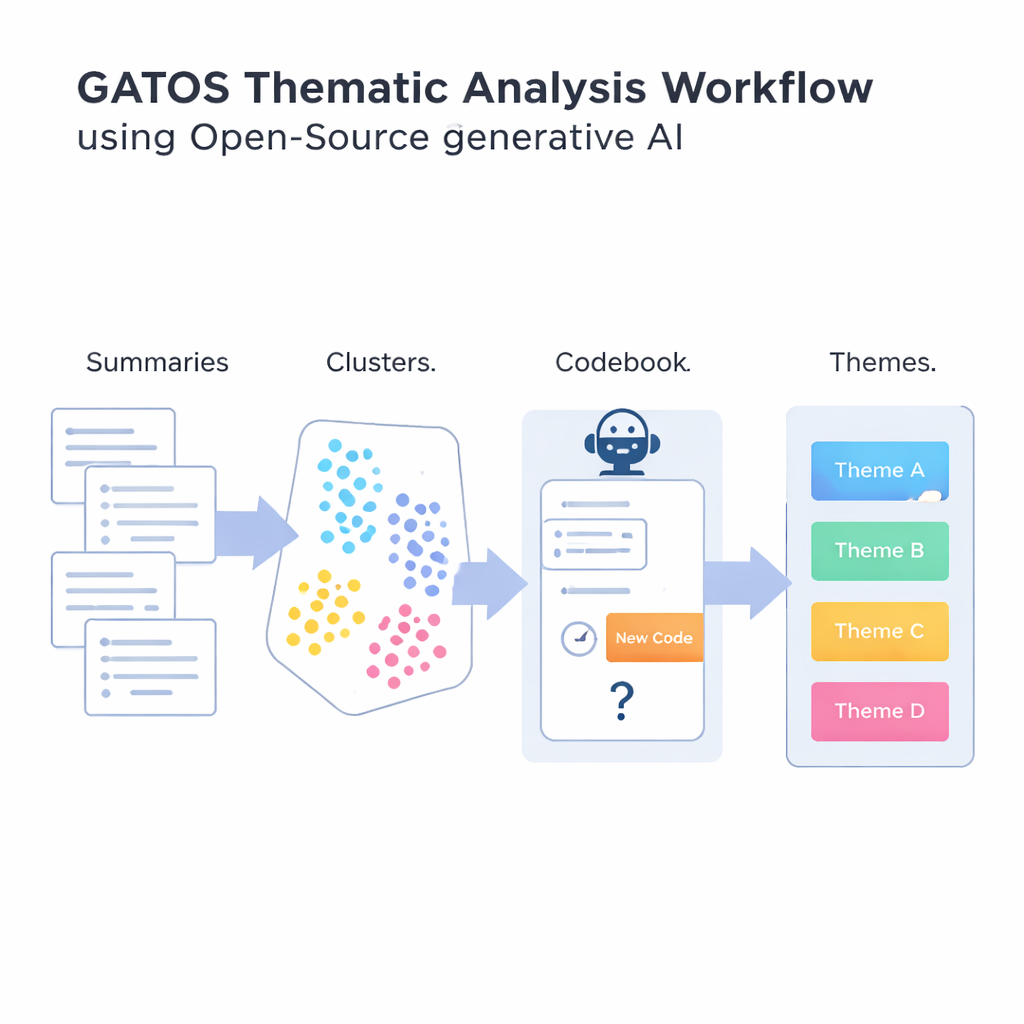
为回答这一问题,作者提出了生成式人工智能支持的主题组织与结构化工作流程,简称 GATOS。该工作流程将若干步骤串联起来。首先,一个开源语言模型阅读单条回答并为每个人的陈述写出简短、聚焦的摘要要点。接着,另一个工具将这些摘要转化为数值表示,以便计算机能够比较并将相似观点归为一组。这些摘要被聚类为可能反映共同主题的组,例如关于工作与生活平衡的关注或对沟通不清的不满。
让人工智能提出建议,但不泛滥新点子
最新颖的一步出现在系统开始构建初稿编码簿时。对于每个相关摘要的簇,另一个生成模型会查看该簇中的观点以及编码簿中已有的代码,然后推理是否需要真正的新代码,或现有代码是否足够。如果出现了新的角度——例如“可靠的视频会议工具”作为一个具体关切——它会提出一个简短的标签和定义并将其加入。如果不需要,则选择重用已有条目。最后一步将相关代码分组为更广泛的主题,从原始评论到组织化洞见形成一张结构化地图。在整个过程中,强调要避免产生大量近重复的代码,同时仍捕捉人们体验中的细微差别。
用逼真的模拟数据测试该方法
由于真实世界的研究很少附带已知的“答案),团队使用合成(计算机生成)数据对 GATOS 进行了测试,在这些数据中隐藏的主题事先已知。他们创建了三个大型、逼真的数据集:关于团队合作的同伴反馈、对职场伦理文化的看法,以及对 COVID-19 大流行后重返办公室的意见。对于每个数据集,他们首先定义了八个主题和若干子主题,然后使用语言模型从不同角色(例如工会成员、管理者或学生)生成数百条真实感强的回答。在对这些数据运行 GATOS 后,人工审阅者将 AI 生成的主题与原始隐藏的子主题进行比较,以评估它们的对应程度。
效果如何,有哪些权衡?
在三个测试案例中,该工作流程较为准确地恢复了大部分原始子主题:绝大多数都有至少一个强匹配,仅有少数没有找到合适的对应项。重要的是,随着系统处理更多数据,它提出的新代码越来越少,表明它在学习重用已有观点而非不断发明各种变体。作者认为,这种可在本地运行的开源设置可以缓解隐私顾虑,并便于不同研究团队复现实验。同时,他们也强调合成数据比许多真实情境要简单,工作流程仍可能产生重叠代码,且仍需要人类研究者来精炼、解释并评判最终的编码簿。
这对非专业人士意味着什么
对于学术界外的读者来说,结论是开源人工智能可以帮助社会科学家和其他研究者倾听更多人的声音,而不会把他们的话简化为粗糙的数字。GATOS 工作流程并不是要取代人工分析者,而更像是一个非常快速且组织良好的助手,提出模式和草拟标签,最终由人来决定这些模式的真实含义。如果后续研究在真实世界数据上证实这些结果,像 GATOS 这样的工具可能会让基于人们实际表述的丰富信息来制定职场政策、教育项目和公共决策变得更容易,而不是仅依赖选择题式的调查。
引用: Katz, A., Fleming, G.C. & Main, J.B. Thematic analysis with open-source generative AI and machine learning: a new method for inductive qualitative codebook development. Humanit Soc Sci Commun 13, 209 (2026). https://doi.org/10.1057/s41599-026-06508-5
关键词: 定性数据分析, 主题分析, 生成式人工智能, 开源语言模型, 社会科学研究方法