Clear Sky Science · zh
系统评估与指南:在手术视频分析中使用 Segment Anything 模型
为什么智能视频工具在手术室很重要
现代外科越来越依赖视频引导:微型摄像头窥视体内,外科医生在屏幕上操作精细器械。把这些信息丰富但杂乱的视频转化为清晰、标注明确的器械和组织地图,有望提高手术安全性、改善培训效果,并让未来的机器人协助更可靠。本研究选取了一个强大的通用视觉系统(最初在日常视频上训练),提出一个简单却重要的问题:它在未经大量医学数据重训练的情况下,能否“看懂”人体内部并在真实手术中发挥作用? 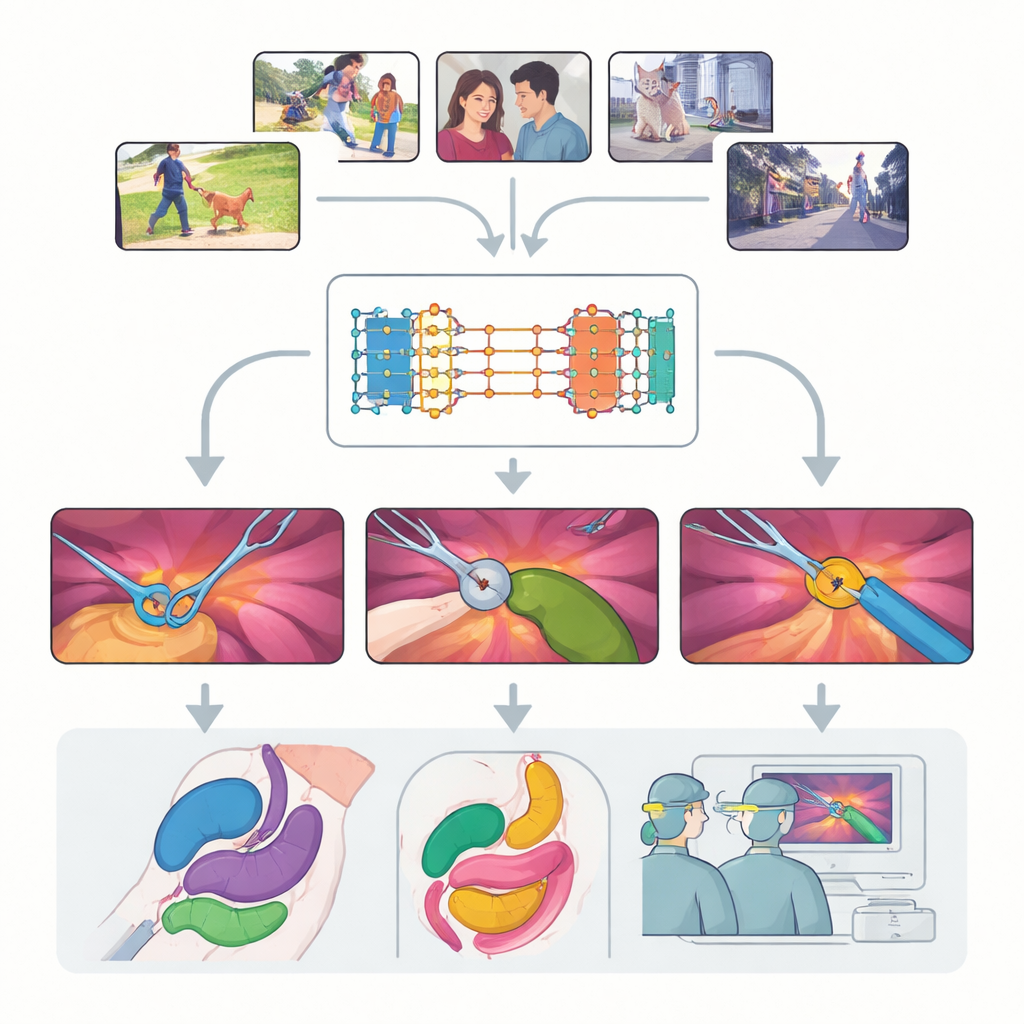
为任何场景打造的灵活视觉工具
研究聚焦于 Segment Anything Model 2(SAM2),这是一个大型 AI 系统,能够在收到提示(“提示”)后识别视频中的对象。不同于学习固定类别的传统模型,SAM2 是类别不可知的:只要用户用点、框或示例掩码指示,模型就能定位目标,而不在乎它是狗、汽车还是手术抓持器。SAM2 的一项关键进展是其记忆模块,它记住早期帧中对象的外观并利用这些记忆随时间跟踪对象。这使得 SAM2 对手术视频尤其有前景——在这些视频中器械会进出视野,组织也会不断变形。
在多种手术中对模型进行检验
作者对 SAM2 在九个多样化数据集、涵盖十七类手术的场景上进行了大规模、系统化评估,手术类型从腹腔镜胆囊切除到机器人前列腺手术和内镜检查不等。他们考察了三大挑战:器械跟踪、多器官分割,以及混合器械与组织的场景理解。对每种任务,他们测试了不同的提示方式——单点、多点、边界框和完整掩码——并探索提示在视频播放过程中需要多频繁刷新。他们还将开箱即用的模型与若干在手术图像上进行轻量微调的方法进行比较,以评估在不依赖大规模新数据的情况下性能能提升多少。
在体内什么方法最有效
总体而言,SAM2 在这一不熟悉的环境中表现出乎意料的强大。在未做手术专门微调的情况下,它已能有竞争力地分割器械和许多器官,尤其是在提供丰富提示(如边界框或掩码)时。每隔约 30 帧“重新初始化”提示——本质上是提醒系统各物体所在位置——能显著提升长时段复杂片段的跟踪效果。当研究者仅微调 SAM2 的特定部分(例如将提示转成掩码的模块)时,多器官场景的准确性大幅提升,同时训练需求仍然适中。相比之下,在有限的手术数据上调整整个图像编码器反而可能损害性能,这表明应当保留 SAM2 大部分通用视觉知识。
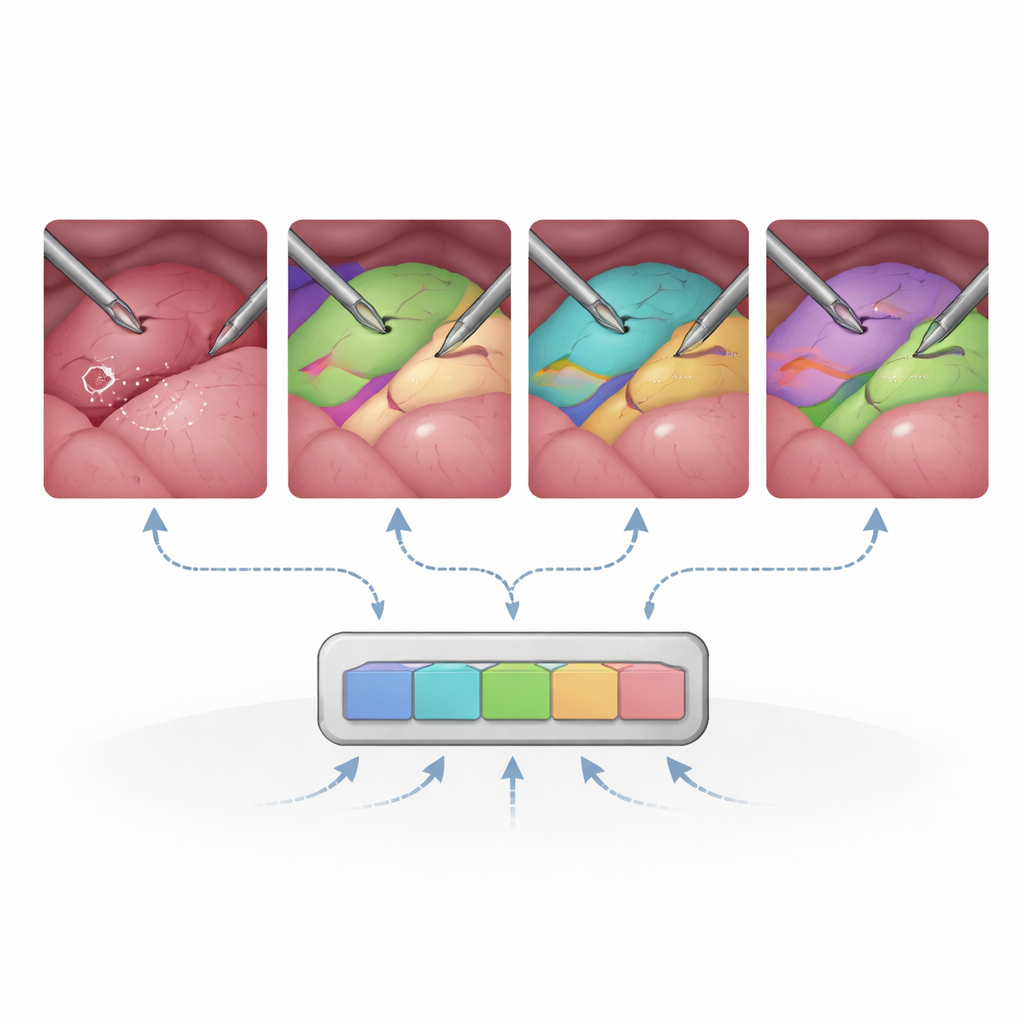
在杂乱、快速变化场景中的局限
研究也揭示了明显的薄弱环节。遇到视野狭窄、图像噪声大或光照差的情况,或组织边界不清晰(例如某些内镜操作),SAM2 表现欠佳。像血管和管道这样的细小分支结构重叠或轮廓相近时,模型难以将它们分开。使用视频记忆并非总是有益:在摄像机快速移动、场景高度动态的情况下,时间线索可能误导模型而非稳定其预测。这些发现表明,尽管通用基础模型能走很远,但某些手术场景仍需领域特定的调优以及更好地处理运动与外观变化的方法。
面向未来智能手术系统的指南
基于广泛测试,作者提炼出对研究者和临床人员在手术项目中使用 SAM2 的实用建议。他们建议以掩码或框提示作为起点,并针对掩码解码器进行简单的基于图像的微调;在长视频中加入定期提示刷新;仅在场景相对稳定时再探索更复杂的视频级训练。他们还展示了即使是稀疏标注的片段(仅对部分帧注释)也足以有效地适配模型。简而言之,结论令人鼓舞:单一的、广泛训练的视觉模型能应对多种手术分割任务,大大减少为每种手术构建全新工具的必要性。通过周密的提示策略与轻量定制,像 SAM2 这样的系统可成为下一代手术导航、自动化与培训工具的重要构件。
引用: Yuan, C., Jiang, J., Yang, K. et al. Systematic evaluation and guidelines for segment anything model in surgical video analysis. npj Digit. Surg. 1, 2 (2026). https://doi.org/10.1038/s44484-025-00002-2
关键词: 手术视频分析, 图像分割, 基础模型, 计算机辅助手术, 医学人工智能