Clear Sky Science · zh
弥合计算与实验之间的鸿沟:利用大型语言模型通过学习模型比较来优先筛选阿尔茨海默病治疗药物
这对家庭和患者为何重要
阿尔茨海默病夺走了人们的记忆、独立性和生活质量,但真正有效的治疗仍然稀缺。本研究探讨了一种更快地发现现有药物新用途的方法,通过将强大的计算模型与大型语言模型——与日常聊天机器人使用的同类人工智能——结合,筛查海量医学数据和科研论文。目标是把冗长的候选药物清单缩小到一组科学家和临床医生可以实际在患者中测试的、切实可行的药物。
为新用途重新利用旧药
从头开发一种全新药物可能需要十多年、耗资数十亿美元,且没有成功保证。另一种选择是“药物再利用”,即为已获批准用于其他疾病(如帕金森病或抑郁症)的药物寻找新适应证。由于这些药物已有明确的安全性资料,它们通常可以更快进入针对阿尔茨海默病的临床试验。然而,目前用于扫描生物数据库和医学文献的现代计算方法会产生庞大的候选列表——远超研究人员手工评估的能力,从而形成新的瓶颈。
将多种智能模型组合起来
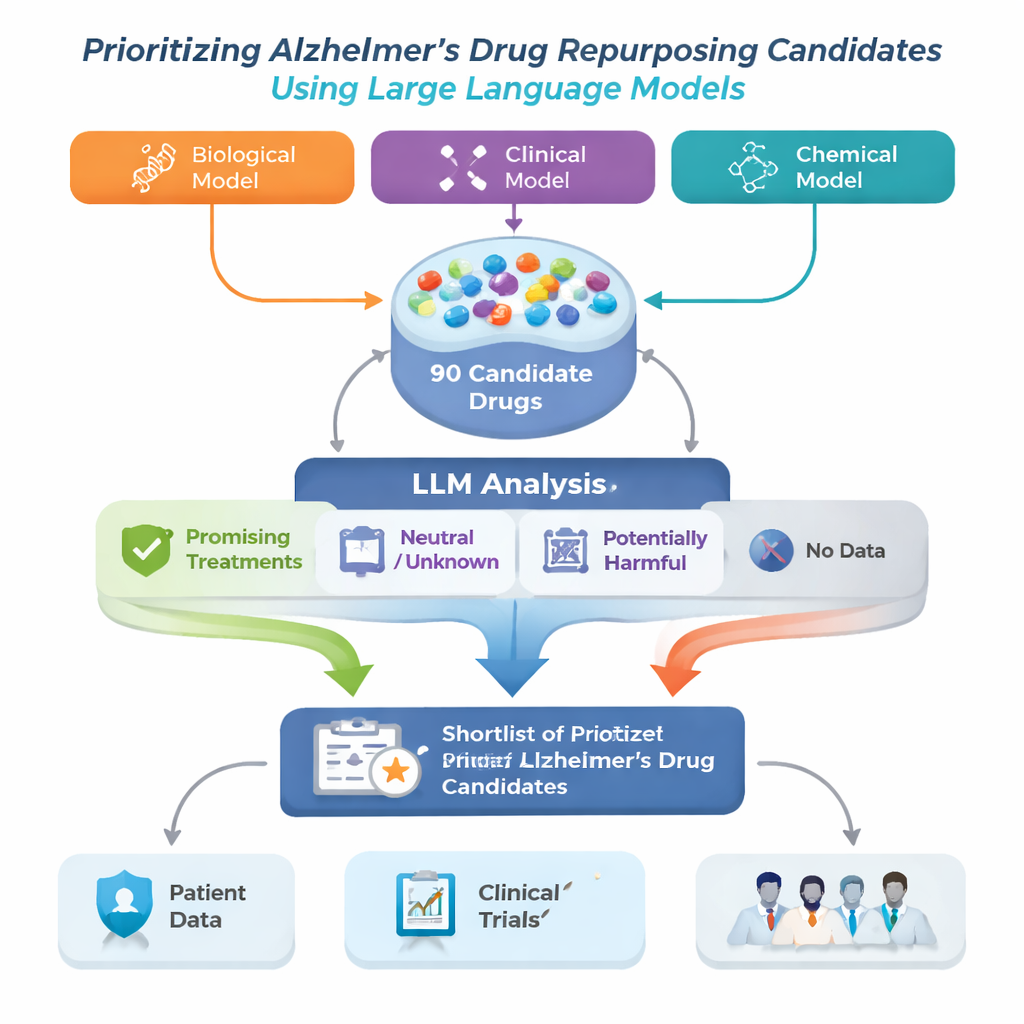
研究团队通过构建一个阿尔茨海默病药物再利用框架来解决这一问题,框架以三种不同的先进计算模型为起点。每个模型都检视一个大型生物医学“地图”,即知识图谱,该图谱将疾病、药物、基因和其他医学概念连接起来,并提出可能有助于阿尔茨海默病的药物建议。由于各模型对模式的识别不同,它们的候选列表并不完全重叠。作者将每个模型的前30项建议合并成一个包含90种候选药物的池,然后使用大型语言模型(LLM)扮演自动但谨慎的审阅者角色,阅读每种药物的已发表研究并判断证据对阿尔茨海默病是有利、中性还是有害。
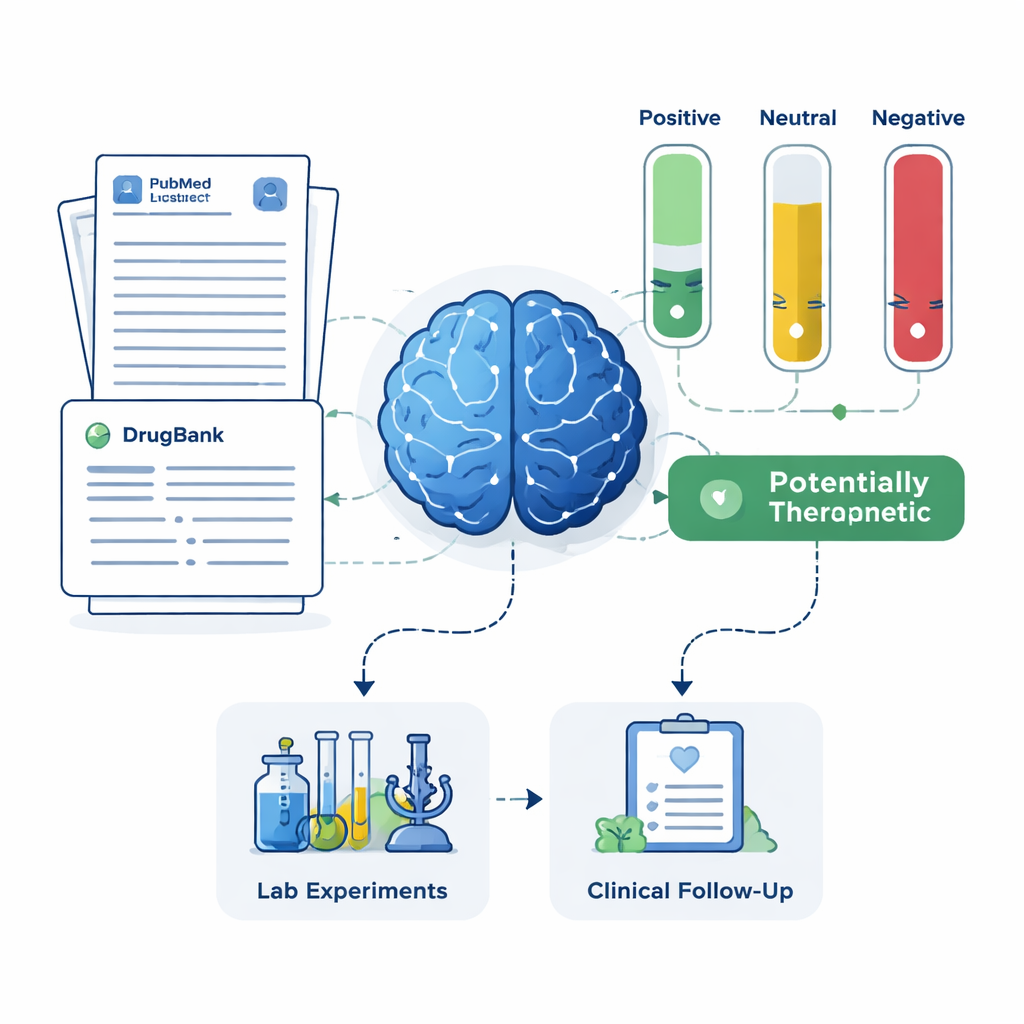
人工智能如何解读医学文献
对于每个候选药物,系统从PubMed检索多达200篇科学摘要,并从药物数据库获取详细药物说明。LLM被指示仅基于呈现给它的文本做出判断,并将每篇摘要标注为对阿尔茨海默病治疗持正面、中性或负面。这些标注随后被转换为简单分数:正面、中性或负面摘要所占的比例。使用两套规则——一套更严格,要求明确的正面证据;另一套更宽容,只要有任何益处的暗示就标记——框架将药物分为四类:有前景的治疗、可能有害、不明确或中性、以及完全没有阿尔茨海默病相关论文的药物。最后一类尽管研究甚少,却可能蕴含特别新颖的机会。
与真实患者和临床试验比对
为检验人工智能短名单在现实世界中的合理性,团队将其结果与两个独立来源进行了比较:一个大型阿尔茨海默病患者登记库和已注册的临床试验记录。该框架成功找回了美金刚(memantine),这是一种在患者数据中显示出强烈保护信号并具有广泛试验背景的现有阿尔茨海默药物,作为高优先级候选药物。它还突出了镁、米诺环素、匹马氯平(pimavanserin)、睾酮和多西环素等药物,这些药物具有不同程度的支持性研究,但曾被临床专家视为有前景。同时,系统也识别出文献提示可能有害或缺乏益处的药物,建议对这些药物降低优先级或进一步评估其副作用,而非作为治疗首选。
从计算预测到可行的下一步
通俗地说,这个框架像一个超快速且谨慎的研究助理,阅读数千篇论文、交叉核对大型医学数据库中的模式,并为人工专家提供一份更短、更有条理的阿尔茨海默病候选药物清单以供集中评估。研究表明,通过将不同类型的人工智能结合——基于图谱的模型用于产生想法,语言模型用于评估证据——研究者可以更快找到既有坚实证据支持的药物,也能发现值得进一步测试的新颖选项。尽管这种方法本身不能治愈阿尔茨海默病,但它提供了一种强有力的新途径,将计算生成的想法与实验室实验和临床试验的艰苦工作连接起来,可能加速走向更有效治疗的进程。
引用: Li, M., Niu, S., Xu, Y. et al. Bridging the computational-experimental gap: leveraging large language model to prioritize Alzheimer’s therapeutics based on comparison of learning models. npj Health Syst. 3, 20 (2026). https://doi.org/10.1038/s44401-026-00074-3
关键词: 阿尔茨海默病, 药物再利用, 人工智能, 大型语言模型, 知识图谱