Clear Sky Science · zh
3D 魔镜:从单张图像重建服装的因果视角
无需试衣间也能试衣
想象用手机拍一张全身照,就能立即看到自己的 3D 形象,可以旋转视角、改变观察角度,甚至与朋友互换服装。本文解决了支撑这种“3D 魔镜”体验的核心技术问题:如何仅用一张普通的穿着者 2D 照片,生成其服装的高细节 3D 模型,而不依赖昂贵的 3D 扫描或受控的棚拍照片。
为什么把 2D 照片变成 3D 如此棘手
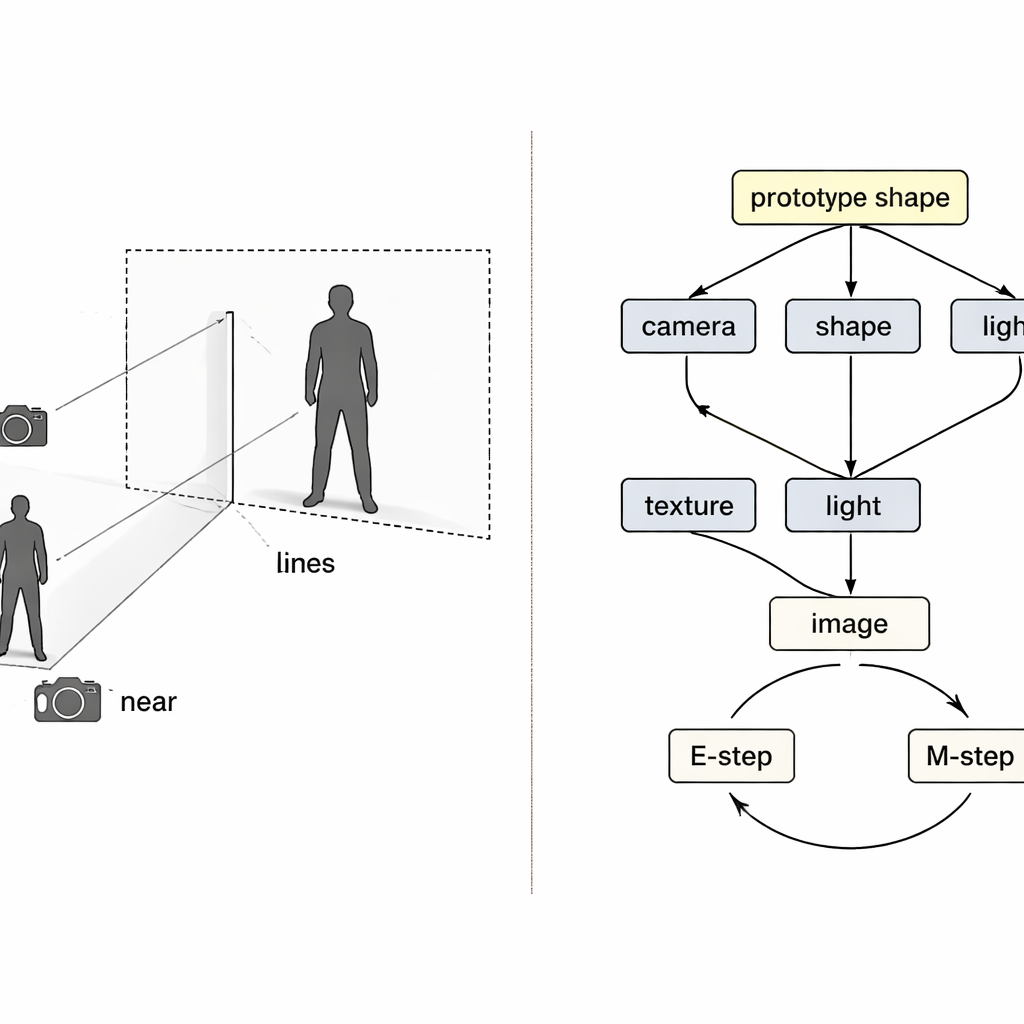
把平面图像还原为 3D 物体是一个经典难题。现有系统通常从固定的数字人体模板出发,再将其变形以匹配图像。对于像手臂和腿这样较为刚性的部位,这种方法相当有效,但对于飘逸的连衣裙、垂坠的大衣、头发或手提包等不遵循简单标准形状的物体就不适用。另一个障碍是数据:网络上有数以百万计的时尚照片,但几乎没有大量精确测量的 3D 服装供训练。最后,单张照片本身就隐藏了重要信息:靠近镜头的小外套和远处的大外套可能看起来完全相同,光照与面料纹理也会混淆学习算法。这些歧义让神经网络很难“猜出”正确的 3D 结构。
教 AI 区分因与果
作者并不把问题视为像素到 3D 的黑箱映射,而是借鉴因果推理——即因果关系的数学理论。他们将最终图像视为四个隐藏原因的结果:相机的位置、服装的形状、纹理(颜色与图案)以及光照。一个特殊的“结构因果图”展示了这些因子如何组合产生观测到的图像。在该图的引导下,系统使用四个独立的神经编码器,各自负责一个因子。配合受物理启发的 3D 渲染器,它们形成一个闭环:输入图像和前景掩码,输出带颜色的 3D 网格,然后将其投影回图像以与原图比较。
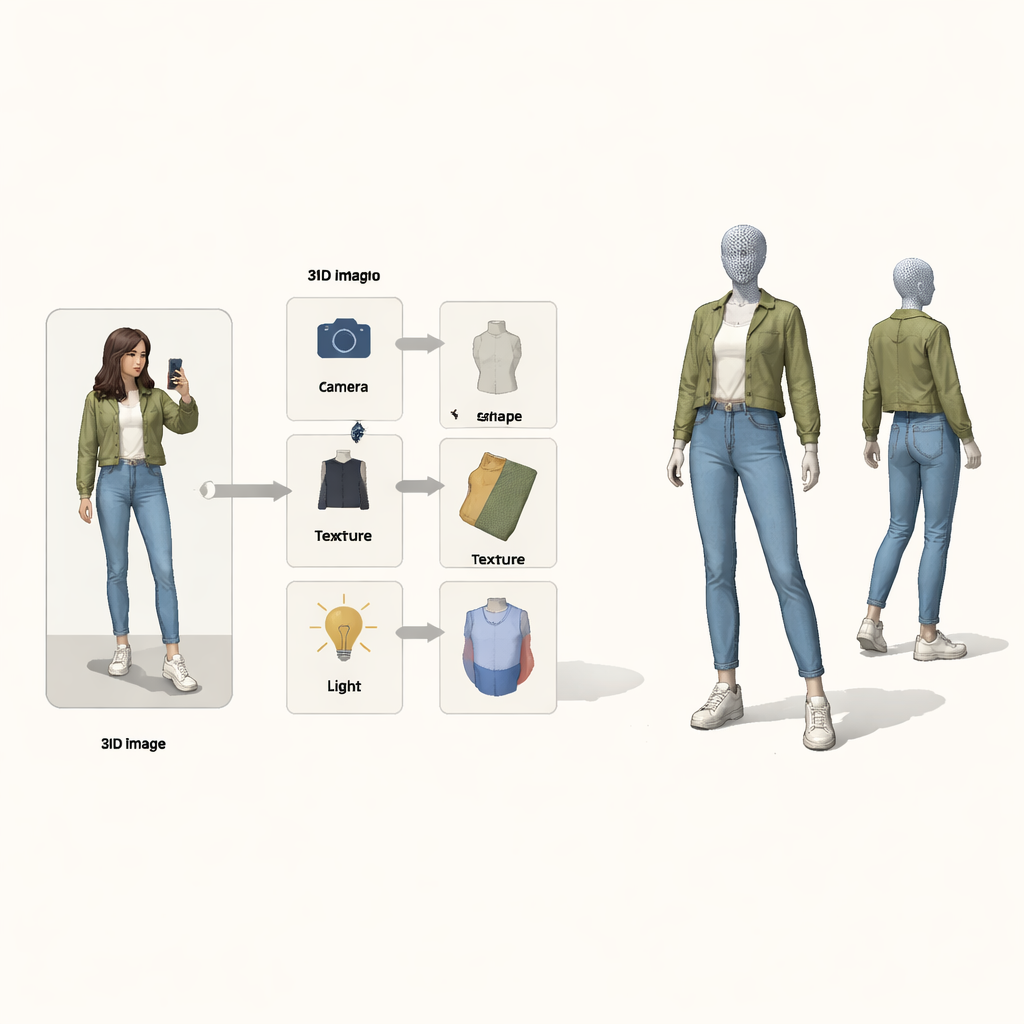
一个逐步修正的学习循环
即便使用独立编码器,训练仍可能出问题。如果重建不完美,很难判断哪个编码器出了错,普通的学习会同时调整所有编码器。作者将此视为因果中的经典“汇聚点(collider)”问题,即不同的原因可能错误地相互补偿。他们的解决方案是在训练中编织两个期望最大化(EM)循环。在第一个循环中,临时冻结三个编码器,仅更新第四个,这样误差就能被清晰归因,该模块学到的职责更纯粹。在第二个循环中,一个共享的“原型”3D 形状——起初为简单的球体——被缓慢更新,成为数据中平均的人体或鸟类形状。单个样本只学习相对于此原型的小偏差,而相机模块则全面负责物体看起来大小或远近,从而直接应对尺寸与距离的混淆。
从时尚照片到鸟类,再到更多应用
为验证方法,研究者在两个包含街拍照片的大型时尚数据集和一个标准鸟类图像集上训练模型。重要的是,他们只使用 2D 前景掩码,而非 3D 的真实网格。在人类服装重建上,他们的系统在匹配服装真实轮廓方面优于流行的人体模板方法,并且对非刚性元素(如头发和手提包)处理得更忠实。在鸟类数据上,其结果达到或超过了领先的单张图像 3D 重建方法,并生成更真实的新视点。这些 3D 模型足够灵活,可支持有趣的应用,例如在人之间交换服装纹理,或生成合成训练数据以提升用于监控研究中的行人重识别系统。
这对日常数字世界意味着什么
对非专业读者而言,关键结论是:令人信服的 3D 头像和虚拟试衣工具不再需要昂贵的 3D 扫描仪或僵硬的模板。通过显式建模因果关系——将相机、形状、纹理和光照分离,并将它们锚定到共享原型——作者展示了系统如何将单张照片“解释”为一个 3D 场景。尽管该方法在从未见过的视角上仍存在困难,例如对只拍摄正面的人恢复背部视图,但它标志着朝着在实际、杂乱的野外图像上可用的实用 3D 魔镜迈出了重要一步。
引用: Zheng, Z., Zhu, J., Ji, W. et al. 3D Magic Mirror: clothing reconstruction from a single image via a causal perspective. npj Artif. Intell. 2, 29 (2026). https://doi.org/10.1038/s44387-026-00082-6
关键词: 虚拟试衣, 3D 重建, 因果学习, 计算机视觉, 时尚人工智能