Clear Sky Science · zh
驾驶任务中人类与算法的视觉注意力
为何这对日常驾驶很重要
随着汽车变得越来越自动化,一个关键问题仍然存在:自动驾驶系统是否真的以与人类相同的方式“看”路?本研究考察了人类驾驶员与人工智能在交通环境中如何聚焦视觉注意力,并表明有针对性地加入一段类似人类的注意力,可以让驾驶算法变得更聪明、更安全——而无需依赖庞大且耗能的AI模型。
人眼在道路上的移动方式
研究者首先让新手与有经验的驾驶员在模拟驾驶环境中执行三项常见的安全任务:发现危险、判断是否可以转弯或变道,以及检测异常、与环境不符的物体,同时追踪他们的眼动。他们发现驾驶员的注意力遵循一个可靠的三阶段节奏。在扫描阶段,场景刚出现时,眼睛在视野中广泛扫视,主要受物体位置驱动。在审视阶段,注意力锁定在单一最有信息量的区域——例如横穿马路的行人或阻挡的车辆——并研究其细节与意义。最后在再评估阶段,驾驶员将该关键对象与其他对象比较,目光来回移动以确认他们的判断。
机器看哪里与人看哪里的差别
团队随后为驾驶场景构建了一个基于注意力的深度学习模型,并将其内部的“注意力图”与人类眼动产生的图进行比较。在通用目标检测上训练模型会让其注意力在某种程度上更像人类,但针对具体驾驶任务的微调却常常使其偏离人类模式,尤其是在富含语义的审视阶段。总体来看,人类与算法注意力之间的相关性仍然有限,这表明当前驾驶AI难以发现人类注视位置及其原因背后的组织原则。
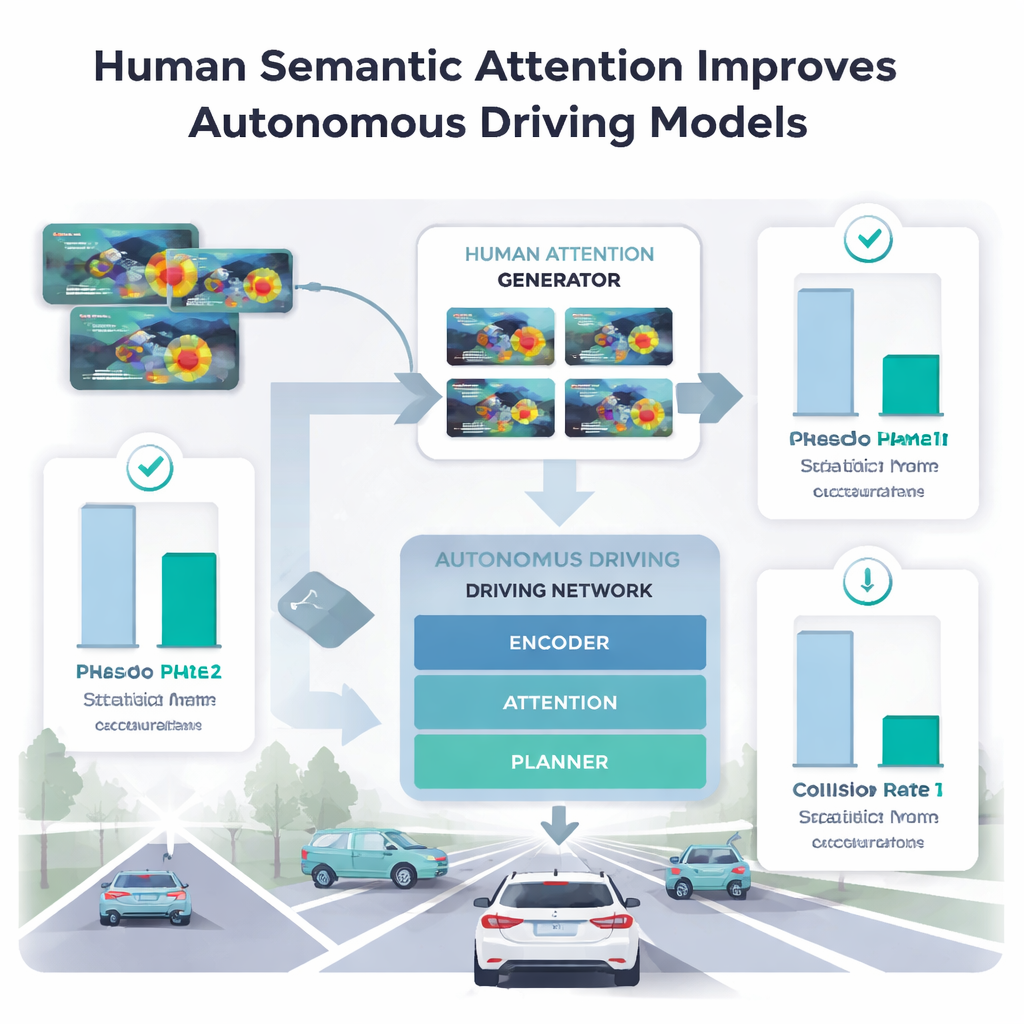
教汽车借用人类的聚焦方式
为了明确人类注意力的哪些部分真正有助于机器,作者将人类凝视的不同阶段输入到他们的驾驶模型中。直接为数百万张图像收集眼动数据并不现实,因此他们在仅来自五名驾驶员的小样本上训练了一个独立的“人类注意力生成器”。该生成器学会为新场景预测类人注意力热图。当主驾驶模型只使用空间上、早期的扫描阶段时,其在异常检测和轨迹规划上的表现常常变差,或者生成看起来更保守但更易发生碰撞的路径。相反,当使用审视阶段——即人类集中在单一最有意义区域时——准确率优于此前使用完整凝视序列的方法,且规划任务中的碰撞率下降。
大型视觉-语言模型仍然缺失的部分
研究者还测试了用于回答驾驶问题或为三维街景生成密集描述的大型视觉-语言模型。在强调高层次推理的问答任务中,加入人类注意力几乎没有帮助,有时反而有害,这暗示此类模型已掌握了许多所需的抽象知识。但在需要将精确词语对应到精确对象的高要求描述任务中,人类的审视阶段注意力仍然带来了显著提升。这表明大型模型在一般推理上可能表现良好,但在必须将词语紧密绑定到繁忙视觉场景中确切位置时仍会出错——而人类的凝视可以弥补这一差距。
这对更安全的自动驾驶意味着什么
简单来说,研究认为真正将人类与当今驾驶AI区分开来的,不仅是我们看哪里,而是我们如何瞬间判断场景中什么重要。那种压缩的语义注意力爆发——当我们仔细审视使情形安全或危险的单一区域时——恰好是许多算法所缺少的信号。通过从少量眼动数据中学习模仿这一阶段,驾驶系统可以在不完全依赖越来越大、越昂贵的AI模型的情况下,获得类人的道路场景理解。这种“语义捷径”可能是让未来自动驾驶汽车在现实交通的混乱和不可预测条件下更可靠的高效路径。
引用: Zheng, C., Li, P., Jin, B. et al. Human and algorithmic visual attention in driving tasks. npj Artif. Intell. 2, 23 (2026). https://doi.org/10.1038/s44387-026-00079-1
关键词: 自动驾驶, 视觉注意力, 人眼追踪, 视觉-语言模型, 交通安全