Clear Sky Science · zh
在小数据情形下使用归纳先验预测并解释细胞类型特异性药物反应
这项研究对未来药物研发的重要性
在测试一种新药时,最大的未知之一是它对人体中不同细胞类型的影响会有多大差异。对一种细胞有益的化合物在另一种细胞中可能无效,甚至有害。要通过实验为数千种药物和无数细胞类型生成这些信息,既耗时又昂贵。本文提出了一种基于计算的方法,称为 PrePR-CT,能够在仅有有限数据的情况下学习并预测单个细胞类型对药物的反应。该工作指向了在投入昂贵的实验室和临床研究之前,以更快、更便宜且更精确的方式在计算机上探索潜在药物的可能性。
观察细胞内部而不仅仅关注药物
传统药物筛选常把细胞视为同质,主要关注总体平均响应。但实际上,免疫细胞、肝细胞和癌细胞对相同化合物的反应可能截然不同。作者认为,要预测这些差异,模型必须理解每种细胞类型的内部连线:哪些基因倾向于共同活跃,以及这些模式如何定义细胞的身份。他们通过检查未受干扰(对照)细胞中哪些基因一起升降,来构建细胞类型的“图谱”。每个图谱以网络形式表示,节点代表基因,连接表示强烈的共同活性。这些网络作为先验知识,描述在加入任何药物之前特定细胞类型的组织方式。
一个网络感知的学习引擎
PrePR-CT 结合了三类要素:细胞类型的基因活性网络、该细胞类型的基线基因表达以及对药物化学结构的紧凑描述。模型利用一种针对图的神经网络来解析细胞的基因网络并提取能捕捉其特征模式的摘要。同时,它将每种药物转化为基于分子结构的数值指纹。这些信息被送入下游预测模块,从已有实验中学习给定药物将如何改变该细胞类型的基因活性分布。该方法不产生每个基因的单一数值,而是估计平均变化以及在单个细胞间反应的变异性,这一点对于理解细微与强烈效应都至关重要。
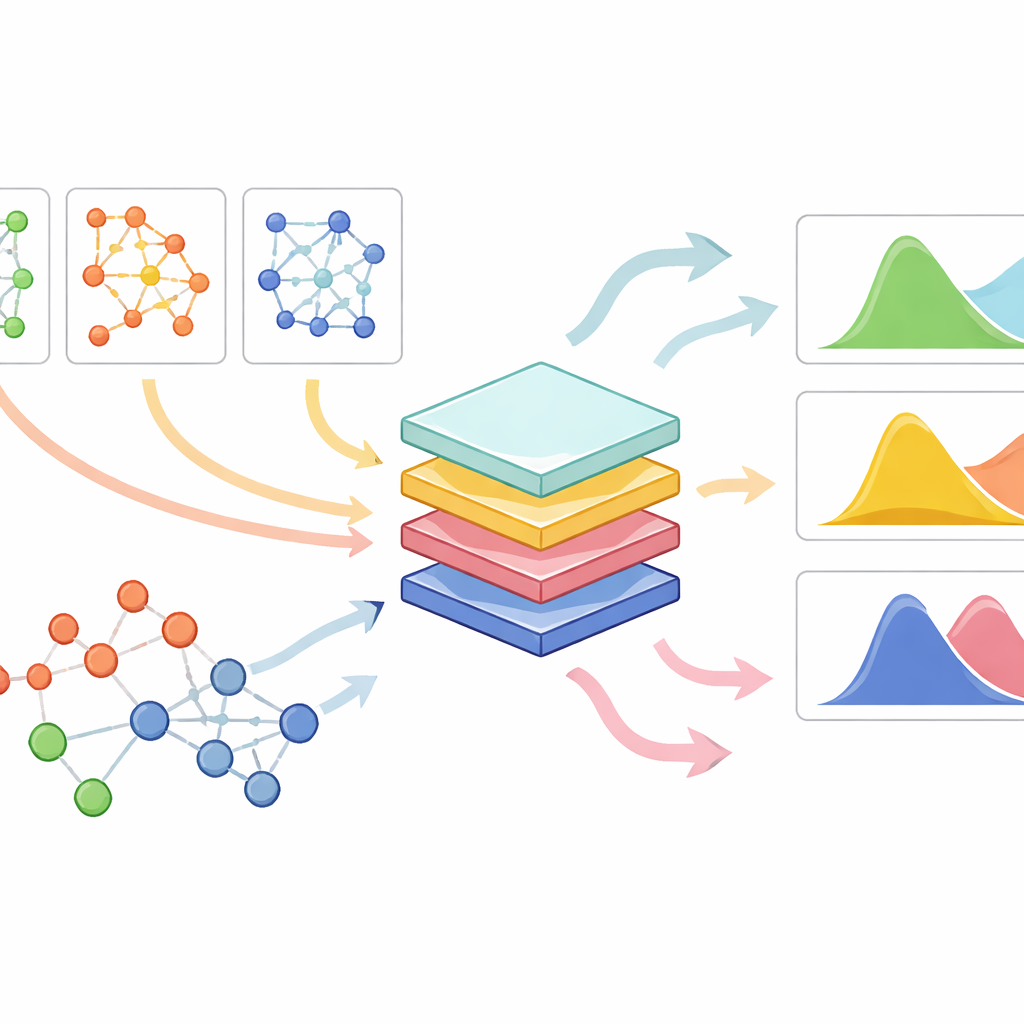
在多种细胞类型、药物与小数据集上工作
研究人员在广泛的数据集中测试了 PrePR-CT,包括暴露于免疫信号的人类血细胞、多种化合物处理的不同癌细胞系、暴露于污染物的小鼠肝细胞以及来自公共资源的大规模药物筛选。在具有挑战性的场景中,当训练时完全排除了某一细胞类型,模型仍能预测该新细胞类型对已知药物的反应,常常优于早期的生成模型。同样地,当排除的是新药而细胞类型熟悉时,该方法仅凭化学指纹就能成功预判其影响。重要的是,当训练样本为相对较少的细胞时,模型仍然有效——这是许多深度学习方法难以胜任的情形。
从黑箱到机制线索
除了原始预测外,作者还希望了解模型是否能提供哪些基因和通路驱动细胞反应的见解。基于图的架构包含一种注意力机制,可突出模型在每种细胞类型中认为特别重要的基因。许多这些“高注意力”基因并非标准差异表达分析中常见的嫌疑基因,但它们聚集在与所测试药物生物学一致的免疫相关通路中。当研究者有意在模型输入中扰动这些有影响力的基因时,预测质量下降,尤其是对反应最强烈的基因,表明注意力得分指向的是有意义的机制性参与者,而非噪声。
对设计更好药物的意义
简而言之,这项工作表明,赋予人工智能模型关于每种细胞类型如何连接的结构化视角——即其内部基因网络——能大幅提升它们预测药物如何重塑这些细胞的能力,即便在数据有限的情况下也是如此。PrePR-CT 并不能替代实验,但它可以帮助缩小值得测试的化合物和细胞类型范围,并提示为何某些细胞会有特定反应。随着数据集的增长和更多细胞特征的纳入,此类方法可能成为为特定组织或患者细胞类型定制疗法的关键工具,减少实验室中的反复试错,使更精确的药物更快地走向现实。
引用: Alsulami, R., Lehmann, R., Khan, S.A. et al. Predicting and interpreting cell-type-specific drug responses in the small-data regime using inductive priors. Nat Mach Intell 8, 461–473 (2026). https://doi.org/10.1038/s42256-026-01202-2
关键词: 药物反应预测, 单细胞转录组学, 图神经网络, 药物发现, 细胞类型特异性