Clear Sky Science · zh
可重用性报告:评估一种元学习基础模型在预测天然产物抗菌活性方面的表现
更快地寻找新抗生素
抗生素耐药性在上升,但发现新药的过程非常缓慢,常常依赖于实验室里的反复试验。本研究探讨了一种最初在大量药物数据上训练的强大人工智能,是否可以快速调整以预测哪些来自植物的天然化合物可能具有抗菌作用——仅使用少量新的实验数据。如果成功,这类工具可以帮助科学家将宝贵的实验室时间集中在最有前景的候选物上,加速下一代抗生素的发现。
为什么植物化学物质很重要
我们许多最有效的抗生素最初都来自植物和微生物的天然产物。这些分子可以抑制细菌生长,但在自然中发现新的活性分子有点像大海捞针。研究人员必须将大量化合物对许多细菌菌株进行测试,每次测试都很昂贵。更糟的是,这一领域中稀缺大规模、标注仔细的数据集,而现代深度学习方法正需要此类数据才能表现良好。这使得抗生素发现成为“基础模型”的理想试验场:这类大型通用人工智能系统可以通过少量示例快速微调以完成特定任务。
一个基础模型学习对抗病菌
团队关注的基础模型名为 ActFound,最初在预测不同化学物质对生物靶点影响强度的大规模数据上训练,数据来自诸如 ChEMBL 和 BindingDB 等资源。ActFound 并非为每个化合物预测单一数值,而是通过比较同一实验中的化合物对并估计哪一种更具活性来学习。这种“成对”学习,结合称为元学习的训练策略,旨在帮助模型在只有少量标注示例时快速适应新的预测任务——这正是许多抗菌筛选中面临的情况。
在真实植物数据上测试模型
为评估 ActFound 的可重用性,作者在一个经整理的植物来源天然产物数据集上对其进行了微调,数据集包含对多种细菌生长抑制能力的测试。每个细菌菌株被视为一个独立任务,模型仅使用每个菌株 8 到 128 个化合物,或占可用数据的固定百分比来进行适应。他们还将 ActFound 与不使用成对比较的更简单的元学习和迁移学习模型进行了比较。在这些测试中,ActFound 未能达到其在其他类型药物数据上早期工作中表现出的准确度。然而,当数据非常有限时——大致每个菌株只有少数化合物可用时——ActFound 及其迁移学习变体通常与或优于其他方法。
相似性何时有利——何时成为障碍
ActFound 假设相似分子具有相似行为,当数据集围绕相关化学物质群体构建时,这一假设运行良好。然而,该天然产物数据集在化学上十分多样,且常常缺乏彼此密切相关的“家族”化合物。这种多样性虽有科学价值,却削弱了成对学习策略:当同一实验中的化合物彼此相差甚远时,模型难以学习到稳定的比较。作者还发现,原始 ActFound 论文中提出的一个用于提前预测模型在新任务上表现的简单诊断,在这些天然产物数据上并不成立,突显了将模型推广到新的化学空间时的重要局限。
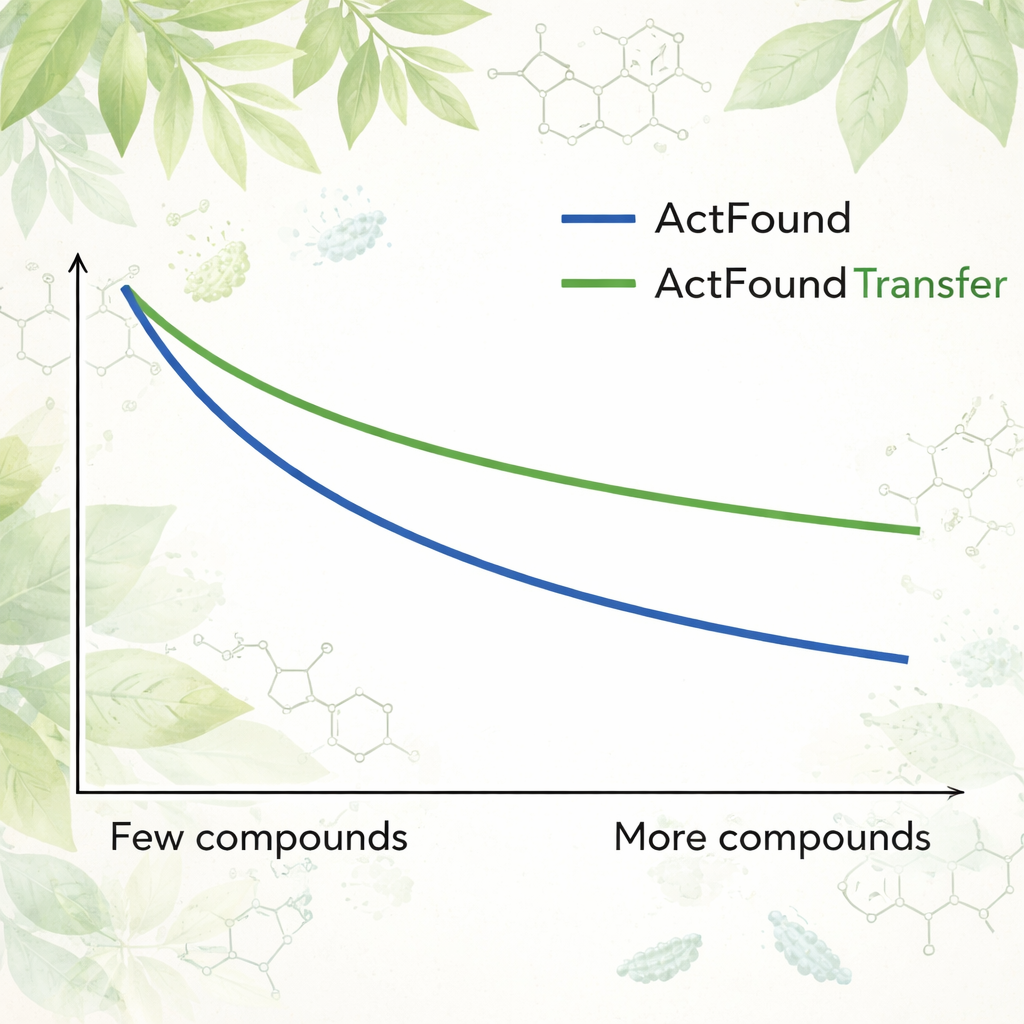
这对未来药物发现意味着什么
对非专业读者而言,结论是:像 ActFound 这样的基础模型在数据稀少时是药物发现中有前景的工具,但并非万能。在本研究中,当训练数据仅有少量植物化合物时,ActFound 及其迁移学习版本常常与或优于竞争方法,然而在这一高度多样的天然产物集合上它们表现吃力。研究表明,这些人工智能模型最有用的情况是数据中包含许多化学上相似的化合物——例如在聚焦于结构—活性关系的研究中——但对于预测全新类型分子的行为仍然不够可靠。换言之,人工智能可以帮助缩小搜索范围,但探索真正全新化学领域中最困难的部分仍然在前方。
引用: Butt, C.M., Walker, A.S. Reusability Report: Evaluating the performance of a meta-learning foundation model on predicting the antibacterial activity of natural products. Nat Mach Intell 8, 270–275 (2026). https://doi.org/10.1038/s42256-026-01187-y
关键词: 抗生素发现, 天然产物, 深度学习, 元学习, 药物筛选