Clear Sky Science · zh
用于深度模型的预条件不精确随机 ADMM
更聪明的训练,成就更聪明的人工智能
现代人工智能系统——从聊天机器人到图像生成器——由规模庞大的神经网络驱动,而这些网络训练起来既困难又耗资巨大。随着公司和研究者把数据分布到许多设备与服务器上,如今的标准训练方法常常变慢、变得不稳定或根本无法应对真实世界数据的混乱。本文介绍了一类以 PISA 为核心的新训练算法,承诺为多种深度模型提供更快、更可靠的学习,同时对数据的数学假设要求更少。
当前训练方法为何捉襟见肘
大多数深度学习模型使用随机梯度下降及其变体训练,这种方法通过反复将模型参数朝减少误差的方向微调来推进训练。多年来,诸如 Adam、RMSProp 等优化器通过自适应步长或引入动量等手段试图使这些微调更智能。然而,这些方法通常假定训练数据被良好打乱、不同机器间在统计上相似,且某些数学量有界。实际上,尤其在联邦学习等场景中,手机或边缘设备持有的数据可能大相径庭,这些假设经常被违背,导致收敛缓慢或性能欠佳。
协调众多学习者的新途径
作者基于另一种优化框架:交替方向乘子法(ADMM),该方法善于将大问题拆分为可并行求解的众多小问题。他们的主要贡献 PISA(预条件不精确随机 ADMM)保留了 ADMM 的优势,同时规避了其常见缺点——例如需要对所有数据计算全梯度或执行昂贵的矩阵求逆。相反,PISA 允许每个客户端或工作节点仅用一小批数据更新各自的模型副本,然后通过一个中心变量来协调这些更新。精心设计的“预条件”矩阵重塑了更新方向,使得学习更平稳、更高效。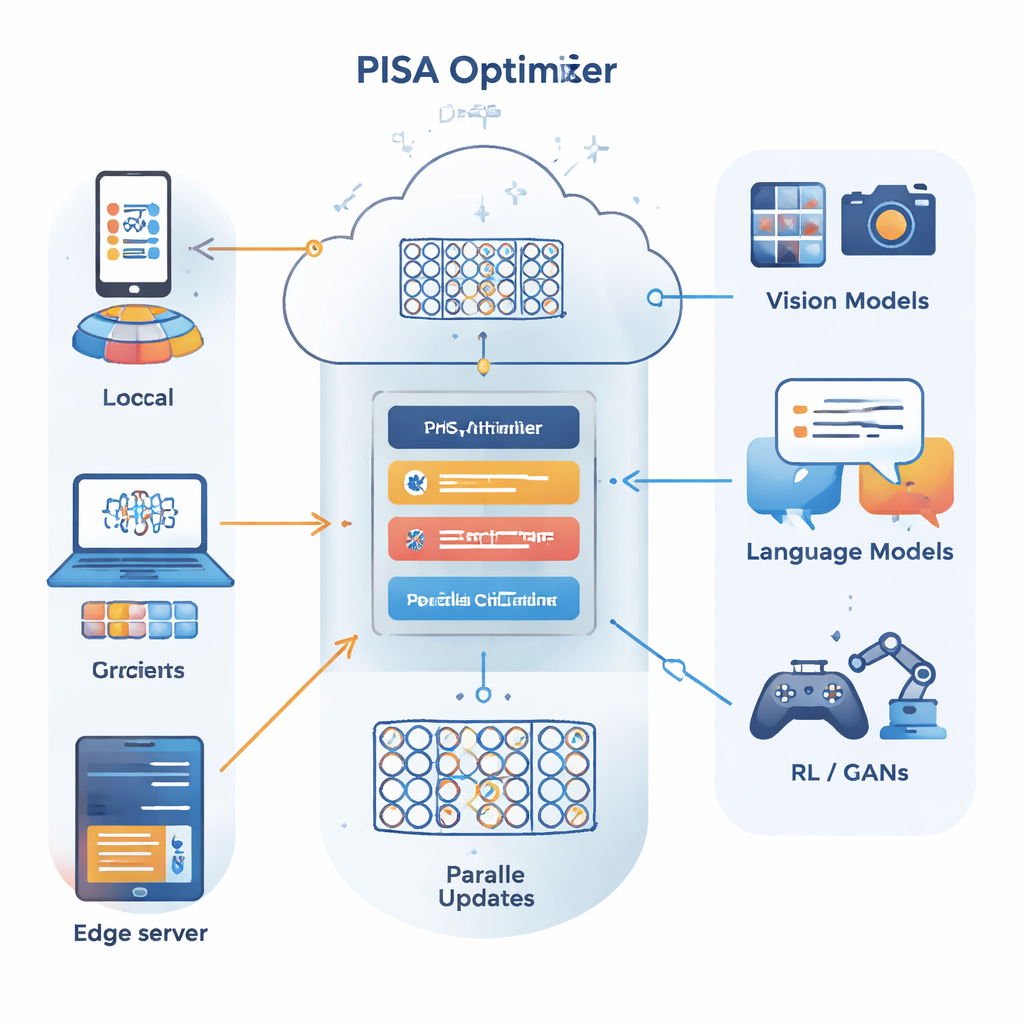
更弱的假设下更强的保证
PISA 的一个显著特点是其理论基础。作者证明了该算法在一项相对温和的假设下收敛:损失函数的梯度在有界区域内是 Lipschitz 连续的,这一条件被许多标准神经网络损失所满足。与大多数随机方法不同,PISA 不要求梯度无偏、不要求梯度方差有界,也不要求数据完全混合。尽管设置更宽松,该方法在函数值和参数更新稳定速度上实现了线性收敛率,使其在比较表中名列前茅。这使得 PISA 对于在现实部署中普遍存在的异构、非均匀数据分布尤其具有吸引力。
适用于真实深度网络的实用变体
为使框架对大型神经网络实用,作者提出了两个高效变体:SISA 和 NSISA。SISA 利用二阶矩信息——本质上跟踪过去在各参数方向上更新的大小——来形成简单的对角预条件器,类似于 Adam 和 RMSProp 的理念,但将其嵌入到 ADMM 结构中。NSISA 更进一步,引入了一种称为 Newton–Schulz 正交化的技术,受 Muon 优化器启发,以更好地将动量与参数空间中有用方向对齐。两种变体在保持 PISA 收敛性保证的同时,使计算量保持在现代 GPU 和大模型可接受的轻量水平。
在视觉、语言与生成模型上的表现
作者在广泛的深度学习任务上测试了 SISA 和 NSISA。在标签分布刻意偏斜的联邦学习实验中——这是一个艰难场景,每个客户端只见到部分类别——SISA 显著优于诸如 FedAvg、FedProx、FedNova 和 Scaffold 等流行方法,在 MNIST 和 CIFAR-10 等基准上取得了更高的测试准确率。对于在 CIFAR-10 与 ImageNet 上使用 ResNet 和 DenseNet 等模型的标准图像分类任务,SISA 达到了或超过了包括带动量的 SGD、AdaBelief 和 AdamW 等强劲优化器的表现。在对不断增大的 GPT2 语言模型进行微调时,NSISA 在实际耗时上比 Shampoo、SOAP、Adam-mini 和 Muon 等专用优化器取得了更低的验证损失,而且在最大模型上这一优势更为明显。它还使生成对抗网络训练更稳定,取得了更低的 Fréchet inception distance 分数,该指标衡量生成图像的视觉质量与多样性。
这对日常 AI 意味着什么
简而言之,这项工作表明,即便在数据混乱、不平衡或分散在众多设备的情况下,也可以更快、更可靠地训练强大的 AI 模型。通过重新设计底层优化过程而不仅仅调整学习率,PISA 及其变体提供了一个统一的工具,适用于视觉、语言、强化学习和生成任务。对于终端用户而言,回报可能是手机上更智能的个性化、更强大的语言和图像模型,以及在大型数据中心更高效的算力使用——这一切都得益于一个更贴合现代 AI 系统现实情况的训练算法。
引用: Zhou, S., Wang, O., Luo, Z. et al. Preconditioned inexact stochastic ADMM for deep models. Nat Mach Intell 8, 234–245 (2026). https://doi.org/10.1038/s42256-026-01182-3
关键词: 深度学习优化, 联邦学习, 随机 ADMM, 大语言模型, 异构数据