Clear Sky Science · zh
当大型语言模型在评估共情式沟通时可靠的情形
为何机器共情与你息息相关
越来越多的人在感到压力、孤独或面临艰难抉择时求助于聊天机器人和数字助理。这些系统可以表现出关心与理解——但它们能否评判一条信息是否真正支持性和善意?本文探讨了大型语言模型(LLM,许多聊天机器人的核心技术)在何种情况下可以可靠地评估书面回复的共情感,以及这对日常工具(如健康应用、虚拟治疗师和客户服务机器人)意味着什么。 
研究支持性对话
研究人员分析了200段真实的文本对话,其中一方描述个人问题——如工作压力、家庭冲突、经济担忧或心理健康困扰——另一方尝试给予支持性回应。这些对话来自四个现有数据集,每个数据集对应一组用于评估共情的不同问题。有些侧重于回应者是否表现出理解或提供情感安慰;另一些则考察是否给出实际建议、鼓励对方多说,或是否将对话中心转向自己。综合起来,这些框架将“表现出共情”细分为21种可评分的具体行为,评分方式类似客户满意度调查的量表。
专家、众包与机器
为评估大型语言模型对共情评分的能力,团队比较了三类评判者:传播学/共情沟通方面的专家、在线众包打分者和现代语言模型。三位资深的共情沟通学者独立对每段对话的21项行为逐一评分。众包打分者——日常的互联网用户——在早期研究中已对相同消息提供了评分。最后,三种领先的语言模型在被以通俗易懂的指南和专家示例评分精心提示后,也被要求按相同量表为每段对话打分。这样的设置允许作者衡量每一组之间的相符程度,不只是与某个“正确”答案的吻合度,还包括彼此之间的一致性。 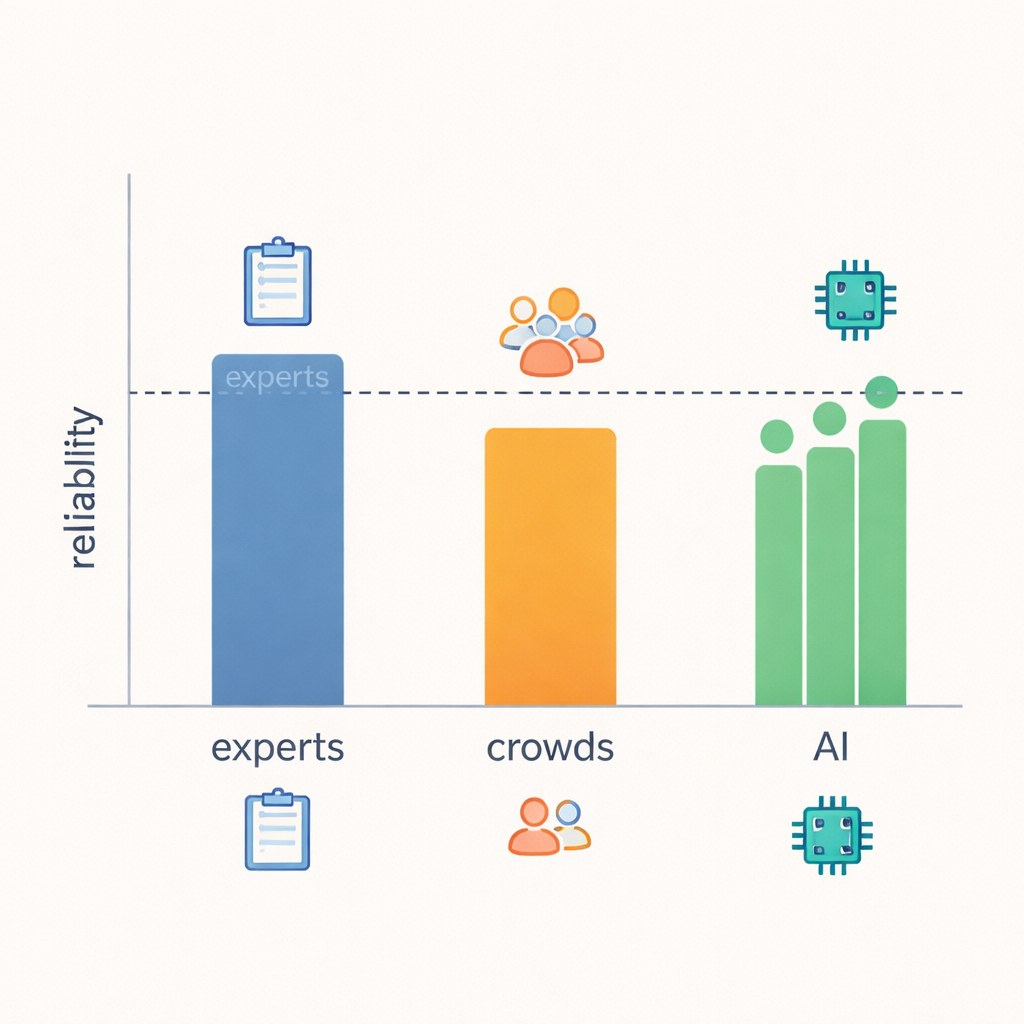
他们的意见有多一致?
核心发现是:大型语言模型的可靠性令人意外地接近专家水平。当研究者衡量评分一致的频率和分歧大小时,模型在大多数21项行为上与专家相当或接近,并明显优于众包打分者。在具有明确可观测信号的领域——例如回应是否给出实际建议、提出后续问题或将关注点拉回到说话者身上——专家、LLM甚至众包往往更容易达成一致。但在评判更模糊的概念时,例如回复是否真正“表现出理解”或回应者的意图为何,即便是专家也更常出现分歧,LLM的可靠性也随之下降。这表明,从文本本身判断某些共情层面本来就更难以捉摸,无论评判者是谁。
为何简单的分数可能具有误导性
许多AI研究使用常见的分类得分来报告成功率——将每个专家评分视为不容置疑的真值,并衡量模型匹配这些评分的频率。作者指出,在处理微妙的人类判断时,这种方法会描绘出失真的图景。例如,一个系统可能通过在不平衡量表上多数投票的猜测而获得高分,即使它在罕见但重要的情况中表现不佳。同样,主要给出“几乎正确”分数(只差一分)的方法,在严格的匹配指标下看起来会很差,尽管它的表现与人类专家相差无几。通过关注评审者间的一致性——不同评审者对同一事物打分的一致程度——该研究提供了对人类与机器可以可靠评估内容的更真实的视角。
这对日常AI的意义
对普通读者来说,结论既令人欣慰又需谨慎。配置良好的大型语言模型现在可以帮助检查书面回复(无论来自人工帮助者还是其他机器人)是否符合共情沟通的专家标准,而且它们在一致性上常常优于未经训练的人类评分者。这可以简化对用于医疗、教育和客户服务的聊天机器人的监控与改进。同时,研究也警示并非所有“共情测试”都同等有效:模糊或互相重叠的问题会导致人类协议薄弱,从而使机器判断也不稳妥。在信任AI来评估诸如情感支持这类敏感事务之前,我们应先确保专家本身能就“良好”标准达成一致——并据此决定机器可安全协助的领域与仍需人类判断的场景。
引用: Kumar, A., Poungpeth, N., Yang, D. et al. When large language models are reliable for judging empathic communication. Nat Mach Intell 8, 173–185 (2026). https://doi.org/10.1038/s42256-025-01169-6
关键词: 共情式沟通, 大型语言模型, 人工智能陪伴, 心理健康支持, 人–机交互