Clear Sky Science · zh
通过考虑残基的注意力机制和预训练表示来提升 kcat 预测
为何更快的酶活性预测很重要
酶是维持细胞乃至整个产业运行的小型“工人”。它们加速驱动代谢的化学反应、制造药物并推动更环保的生产工艺。描述酶作用速度的关键参数是转换数,或称 kcat。在实验室测定 kcat 既耗时又昂贵,因此科学家转向人工智能,从序列和反应信息预测 kcat。本文提出了 PMAK,一种新的 AI 模型,它不仅比早期工具更准确地预测 kcat,还能指出酶中哪些部分对其活性最为关键。
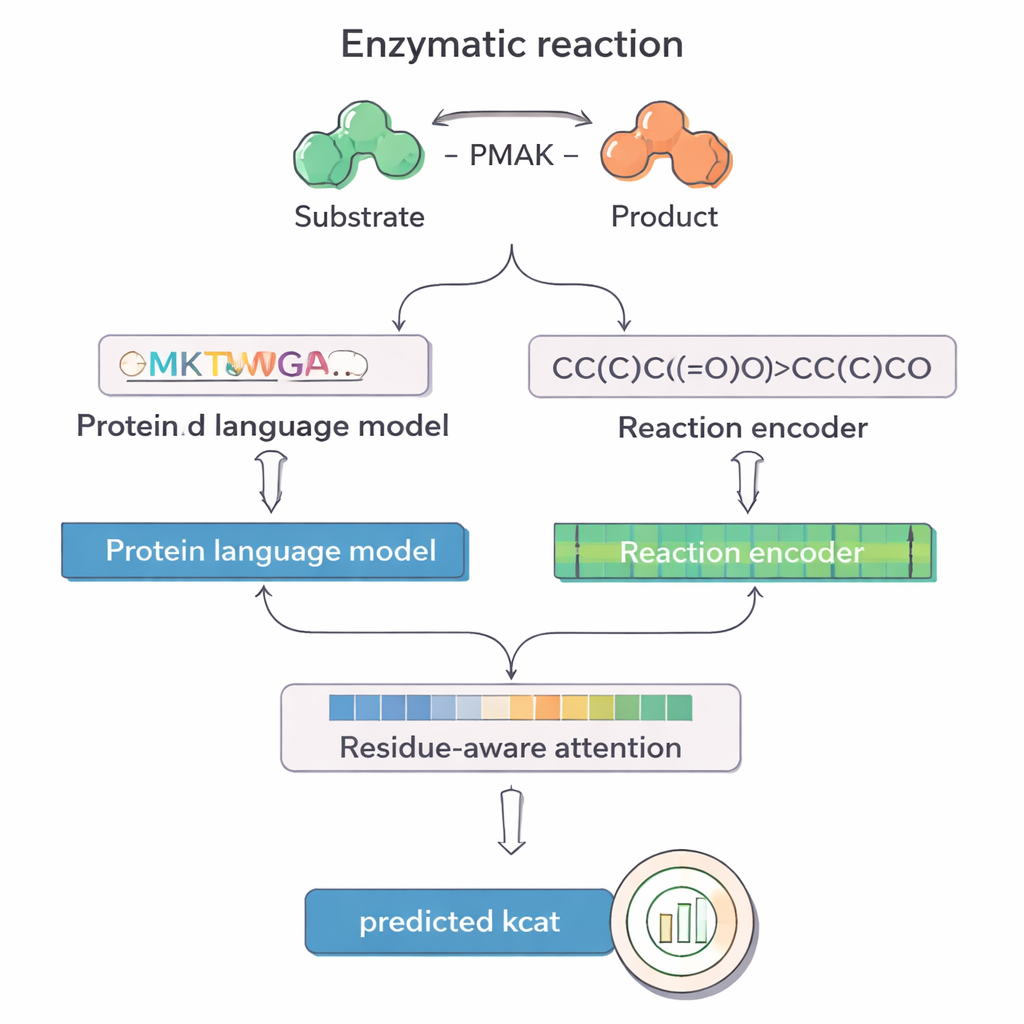
从繁重的实验到智能预测
传统上,确定 kcat 意味着在严格控制的条件下(如固定温度和 pH)精确测量酶将底物转化为产物的速率。对成千上万种酶进行此类测定不切实际,这限制了我们对整个代谢网络建模或设计新生物催化剂的能力。早期的计算方法试图弥补这一空白,但许多方法依赖手工构建的特征,或仅以简化方式考虑酶与单一底物。这些方法常常仅在新酶与训练数据中已见的酶高度相似时表现良好,对真正全新的酶、全新的反应或经工程改造的突变体则表现不佳。
教计算机“理解”酶与反应的语言
PMAK 利用了最初为文本开发但后被重新训练用于大量蛋白序列和化学反应的“语言模型”进展。其中一个模型 ProT5 将酶的氨基酸序列转换为富含信息的数值表示,这种表示捕捉了从数百万蛋白中学到的模式。另一个模型 RXNFP 则对以 SMILES 字符串表示的完整反应(编码所有反应物与产物)做同样的处理。PMAK 将这两种学习到的表示输入到一个神经网络中,对它们的维度进行对齐,使模型能够同时考虑酶与完整反应上下文,而不是将二者分开处理。
突出最重要的构件
PMAK 的一个核心创新是“残基感知注意力”机制。模型不是把酶中每个氨基酸都视为同等重要,而是学会为对当前反应最关键的特定残基赋予更高权重。这些注意力分数就像照在序列上的聚光灯:研究人员将其与蛋白质结构中已知的催化位点和结合位点比较时,发现 PMAK 一贯比随机更频繁地突出功能性残基。即便在将活性位点更广义地定义为包括三维空间中邻近残基时,模型的表现依然良好,表明它捕捉到了与催化相关的细微结构和化学线索。
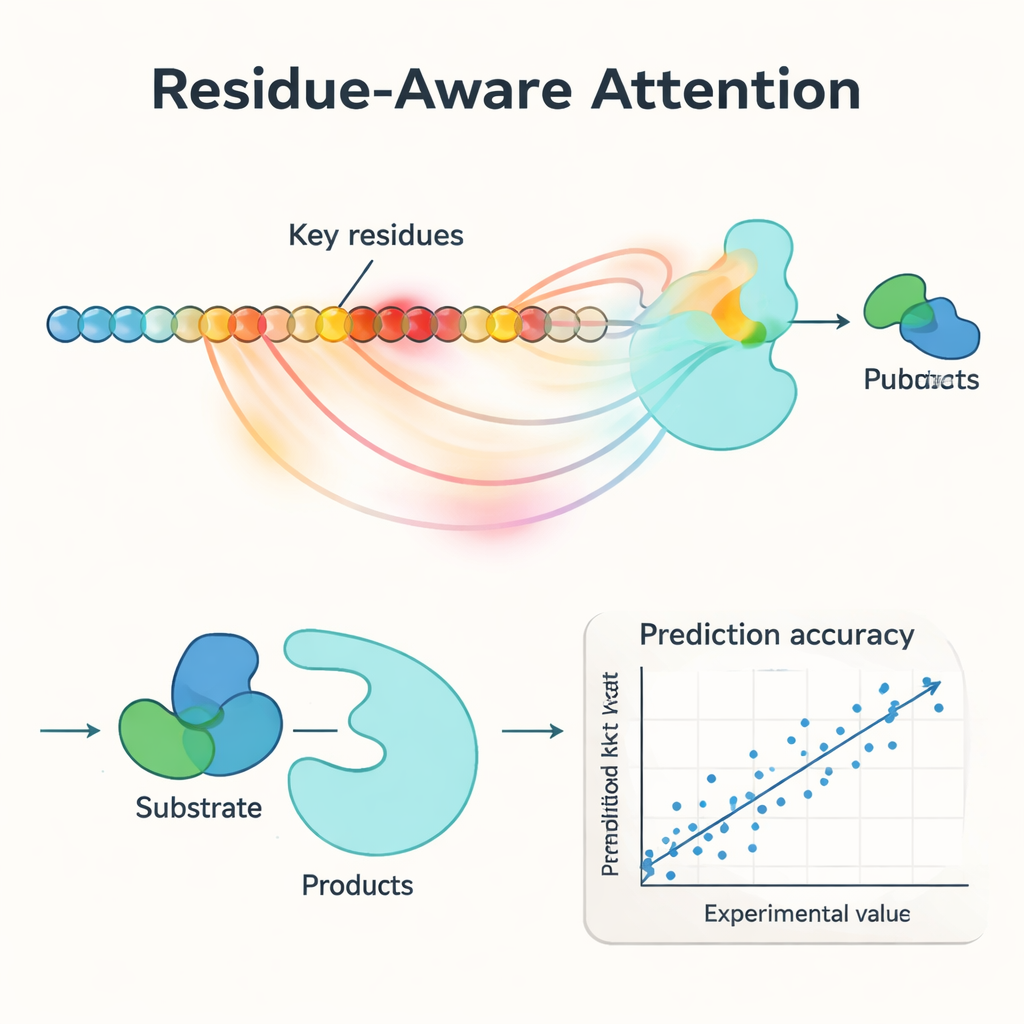
在新酶、新反应和突变体上表现良好
作者在一个精心整理的数据集上严格测试了 PMAK,该数据集包含超过 4000 个 kcat 值,涵盖近 3000 种酶和 2800 个反应。在“热启动”条件下——训练集和测试集中存在相似酶与相似反应时——PMAK 与或超越了现有最佳模型。更令人印象深刻的是,在“冷启动”测试中(测试集中出现的酶或反应在训练集中从未见过),PMAK 优于多种领先方法。即便针对序列与训练数据相似度很低的酶或在外观上与训练反应差异很大的反应,PMAK 仍然有用。PMAK 还在现实应用中提升了预测效果,例如估算细胞如何分配有限的蛋白资源,以及在酶工程数据集中预测突变的影响。
这对生物学和生物技术意味着什么
对于非专业读者而言,PMAK 可被视为一个聪明的助手,它从海量蛋白与反应“库”中学习,以猜测任一给定酶在特定反应中的反应速度——并解释哪些氨基酸驱动这种行为。通过将更高的准确性与残基级别的洞见结合,这种方法可帮助研究人员设计更好的酶、构建更可靠的代谢模型,并在无需进行所有实验的情况下探索突变如何影响功能。随着类似模型拓展到其他动力学特性,它们可能成为设计更清洁工业工艺、优化用于可持续生产的微生物以及深化我们对生命分子机器如何实现其惊人速度之理解的关键工具。
引用: Cai, Y., Ge, F., Zhang, C. et al. Enhancing kcat prediction through residue-aware attention mechanism and pre-trained representations. Commun Biol 9, 273 (2026). https://doi.org/10.1038/s42003-026-09551-9
关键词: 酶动力学, 深度学习, kcat 预测, 蛋白质工程, 代谢建模