Clear Sky Science · zh
结合联邦学习与巡回模型可提升性能并为数字健康公平开辟机会
在不共享数据的情况下共享医学洞见为何重要
现代医学越来越依赖人工智能来从影像和病历中发现模式。但患者数据敏感,通常不能离开收集它的医院。这产生了一个矛盾:全球各地的医院如何在不将原始患者数据跨境或传到大型中央服务器的前提下,共同训练强大的人工智能工具?本研究提出了一种新的方法,旨在不仅提高准确性,还在资源充足的医院与资源匮乏的小诊所之间实现更公平的结果。
两种在不移动数据的情况下训练人工智能的方法
目前有两种主要策略允许医院在本地保留数据的同时共同训练AI。在联邦学习中,每家医院并行训练其本地模型副本;随后这些本地模型在中央服务器上合并为共享的“全局”模型。在巡回模型方法中,则只有一个模型在医院之间移动,依次在每个站点进行训练。这两种方法都保护隐私,但各有缺点。联邦学习在某些医院数据非常少或未覆盖所有患者类型时可能表现欠佳;合并薄弱或不平衡的本地模型可能导致全局模型主要反映大型富裕站点的特征。巡回模型对这些不平衡更具鲁棒性,但可能更慢且管理更困难。
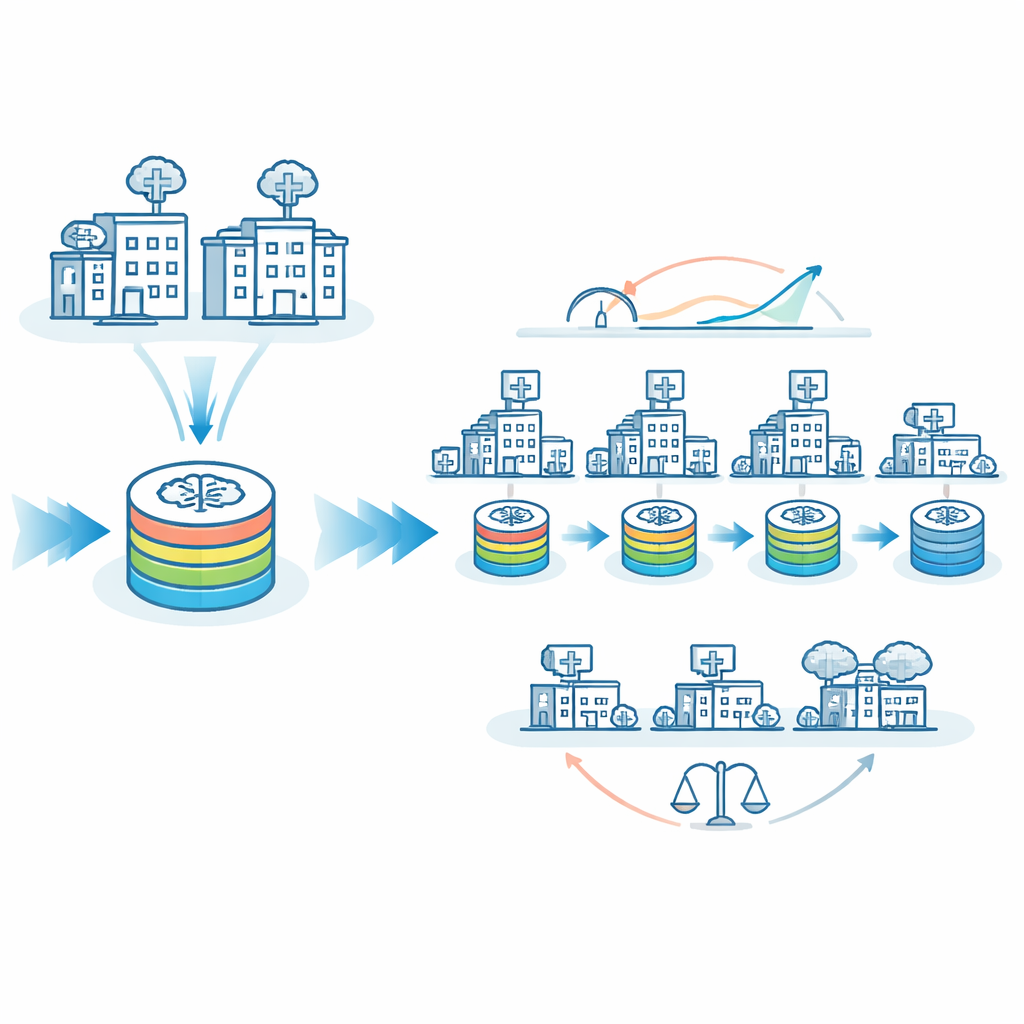
结合两者优点的混合策略
作者提出了FedTM,一种混合训练方案,融合了联邦学习与巡回模型的优点。训练分两个阶段进行。首先是“预热”阶段,只有数据量大且数据更完整、平衡的医院并行使用标准联邦学习技术训练模型,形成一个强有力的起始模型。接着是“精炼”阶段,此时该预热模型按序访问每个站点,包括那些可能只有少量脑部扫描甚至仅有一位患者的非常小的诊所。在第二阶段,模型在巡回过程中逐步更新,从每个站点吸收知识,同时其数据永远不需离开本地管理。
在帕金森病脑部扫描上的方法测试
为检验FedTM,研究人员使用来自全球83个影像站点的1,817例脑部MRI扫描来训练一个能够区分帕金森病患者与健康个体的AI系统。这是一个特别具有挑战性的场景:超过一半的站点贡献的扫描少于十例,只有大约三分之一的站点同时有患者与健康对照数据,且扫描协议差异很大。在这些现实世界条件下,纯联邦学习未能很好地学会该任务,而纯巡回模型表现较好但仍有提升空间。FedTM——尤其是在预热阶段包含七个最大且数据最平衡的站点时——明显优于两者:ROC曲线下面积(AUC),这一分类质量的标准度量,从仅用巡回模型时的77%提升到FedTM时约82%,在灵敏度、特异性和F1分数等其他临床重要指标上也有类似提升。
使人工智能在大医院与小医院之间更公平
医学人工智能的一个主要担忧是公平性:模型对小型、偏远或资源匮乏医院的患者是否与对大型学术中心患者一样有效?研究团队检查了AI在“较大”与“较小”站点的错误预测频率。仅使用巡回模型时,这两类站点的误分类率相差约8个百分点。经适当调优的FedTM使较大与较小站点的误分类率几乎一致,约为26%。换言之,模型不仅整体更准确,而且更为均衡。FedTM还将大部分计算负担转移到资源更丰富站点的预热阶段,将小站点所需运行的训练轮数几乎减半,同时保持总体训练时间相近。
这对全球数字健康意味着什么
FedTM为开发尊重隐私、提升性能并更公平地在全球共享收益的人工智能工具提供了切实可行的路径。通过允许即使拥有极少数据的站点也能影响最终模型,该框架有助于确保在新诊断工具开发时,资源匮乏或偏远地区的人群不会被抛在后面。虽然该研究聚焦于一种脑部扫描和一种疾病,但该方法原则上可以推广到许多其他医学问题。随着医疗系统越来越多地采用移动设备与可穿戴设备,且法规强调数据主权,像FedTM这样的混合策略可能成为构建值得信赖、包容且负责任的医学人工智能的关键。
引用: Souza, R., Stanley, E.A.M., Ohara, E.Y. et al. Combining federated learning and travelling model boosts performance and opens opportunities for digital health equity. npj Digit. Med. 9, 294 (2026). https://doi.org/10.1038/s41746-026-02483-y
关键词: 联邦学习, 巡回模型, 帕金森病, 医学影像人工智能, 健康公平