Clear Sky Science · zh
界定临床人工智能系统的运行安全性
为什么医疗领域的安全人工智能很重要
医院正在快速采用人工智能来解读影像并标记疾病,但有一个普通的准确性分数无法回答的问题:在什么时候让机器做出判断实际上是安全的?本文提出了一种实用方法,用以决定医生何时可以自信地依赖AI系统、何时应忽略其结论以及何时必须亲自仔细审查。目标不仅是构建更聪明的算法,而是以一种保护患者、减少不必要检查并减轻而非增加临床人员负担的方式将其嵌入日常护理。
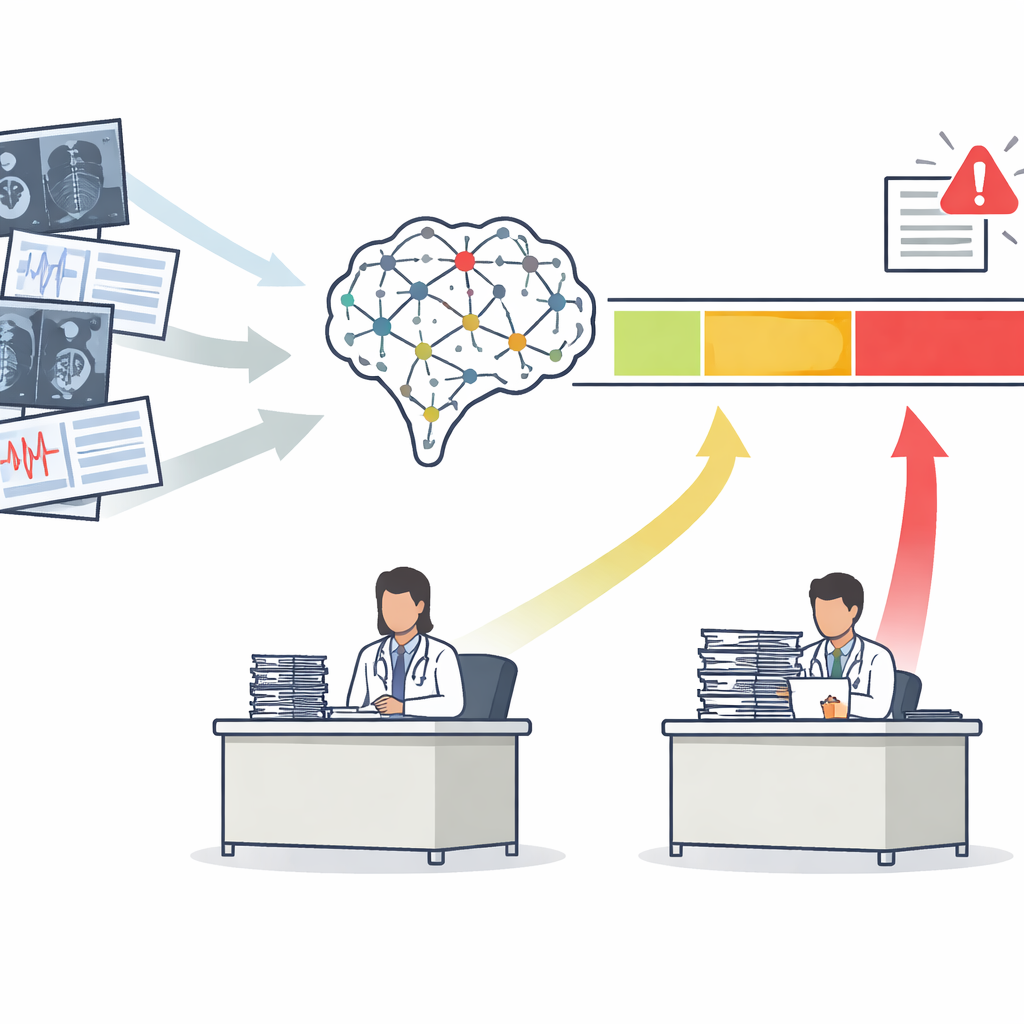
从单一分数到三个明确的行动区
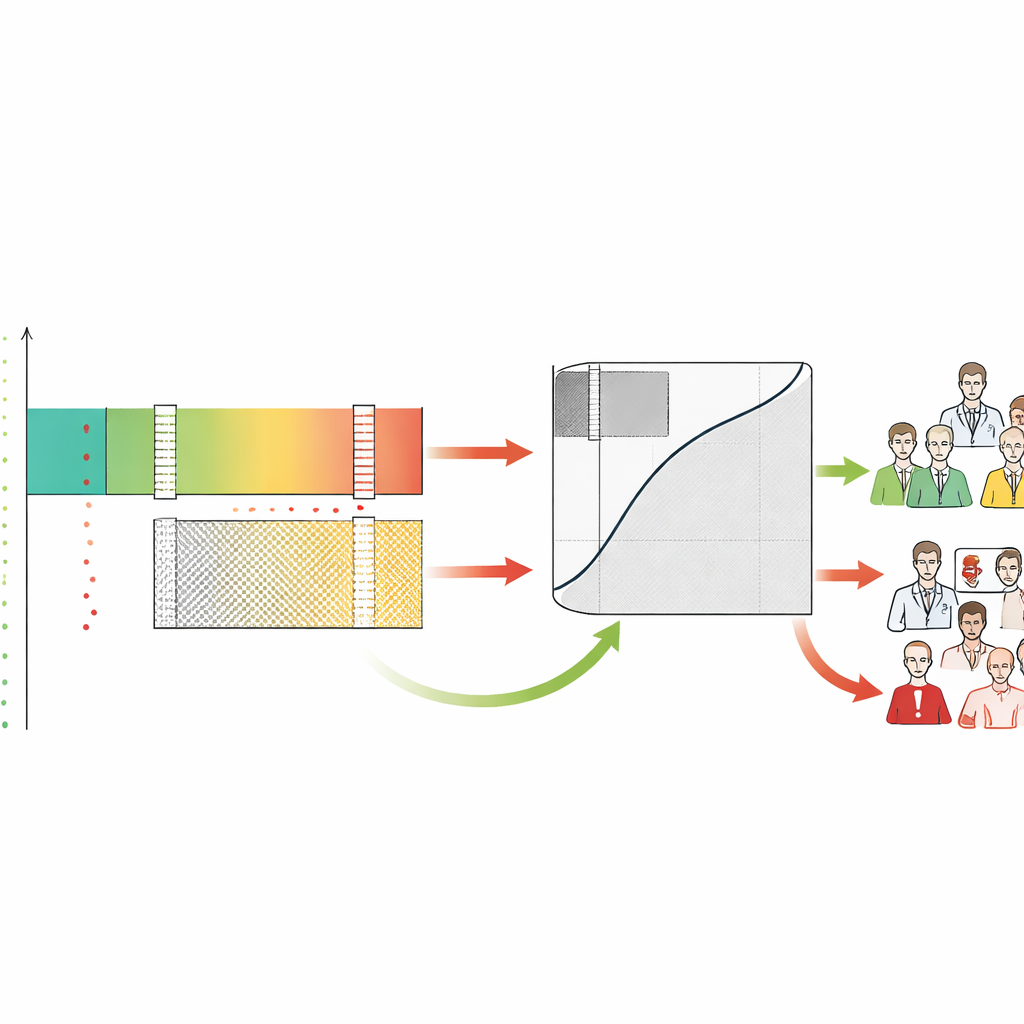
大多数医学AI工具输出单一风险分数,例如乳腺X线检查显示癌症的概率。传统上,开发者使用一条曲线来评估这些工具整体上区分病人与健康者的能力。作者认为这还不够。他们提出了“安全感知ROC”(SA-ROC)框架,该框架以相同的风险分数为起点,但将其重构为三个实用区域。高分的“确诊(rule-in)”区包含那些结果足够可靠以触发措施的患者,例如紧急随访。低分的“排除(rule-out)”区包含那些结果足够可靠以安全降低优先级的患者。两者之间是一个“不确定灰区”,在该区域中AI不够可信,必须由人类专家复核。
让临床人员自行设定安全门槛
至关重要的是,SA-ROC允许临床人员和机构事先定义自己的安全目标。他们选择在对阳性结果采取行动前希望达到的确信程度(被标记异常的最低可接受真实概率),以及在对阴性结果放松警惕前希望达到的确信程度(被判定为正常的最低可接受真实概率)。给定这些目标,框架在模型的分数中搜索以找到满足目标的确切边界。高于上边界的分数构成确诊安全区,低于下边界的分数构成排除安全区,介于两者之间的一切则成为灰区。该框架随后量化落在每个区域的患者数量以及AI仍未解决的、不确定的工作量——需要返回由人类处理的案例数。
揭示表面相似AI之间的隐藏差异
作者展示了两种在传统准确性上几乎相同的AI系统,在安全视角下可能表现出截然不同的行为。在模拟中,整体性能相同的模型由于其分数分布不同,产生了截然不同规模的确诊区、排除区和灰区。一个模型可能在自信地确认疾病方面表现出色,而另一个则可能在安全地筛除大量低风险患者方面更擅长。在两个经美国食品药品监督管理局(FDA)批准用于乳腺癌筛查的工具的真实案例研究中,标准准确率更高的系统在高置信度筛查方面实际上表现更差。在最严格的安全设置下——在低风险组中不允许遗漏任何癌症——被认为较弱的系统却安全地将近两倍数量的女性从放射科医师的待审队列中移除。由此,SA-ROC揭示了一种被传统指标所掩盖的“性能逆转”。
理解人机张力与工作负荷
通过将每个案例标记为确诊、排除或灰区,该框架还揭示了人类医生在这些区域的行为。作者发现放射科医师经常对AI判定为安全低风险的病例进行过度呼叫,在机器最可靠的区域产生了许多误报。相比之下,人类和AI在灰区中都表现困难,这验证了该区域确实需要专家关注。SA-ROC用一个数值捕捉灰区的大小,这代表了犹豫不决的代价。小的灰区意味着更多安全自动化和更少的人为工作负担;大的灰区则意味着许多病例仍需仔细人工复核,系统可能会增加而非缓解职业倦怠。
将安全规则转化为日常实践
除了测量功能外,该框架还被设计为一种治理工具,可将政策转化为具体的AI行为。医院可以通过两种方式使用它。第一,直接指定安全要求或对可接受发送到灰区的病例比例设限,然后让框架计算相应的阈值。第二,为不同结果赋予价值和惩罚——发现一例癌症、漏诊一例、下达不必要的检查或将病例交由人工复核——并让框架搜索能最大化总体利益的策略。这些策略可针对截然不同的目标进行调优,例如大规模筛查项目、专科转诊或研究队列,所有这些都可以使用相同的基础模型。
这对患者和临床人员意味着什么
简而言之,这项工作提供了一种方式,不仅能说“这个AI很准确”,还能说“这里是它在临床中何时以及如何值得信赖的精确说明”。通过将AI输出划分为与明确安全承诺相对应的安全、非安全与不确定区域,SA-ROC帮助卫生系统决定机器何时可以独立行动、何时必须由人类牢牢掌控。它强调传统准确性分数可能具有误导性,真正的安全取决于模型在错误代价最高的极端情况下的行为。如果该框架被广泛采用并在更大规模的真实世界环境中验证,它可能支持更可靠的自动化、减少不必要的警报与检查,并将最困难的AI病例——灰区——转化为对算法与医疗本身都具有针对性学习与改进的焦点。
引用: Kim, YT., Kim, H., Bahl, M. et al. Defining operational safety in clinical artificial intelligence systems. npj Digit. Med. 9, 281 (2026). https://doi.org/10.1038/s41746-026-02450-7
关键词: 临床人工智能, 运行安全, 医学影像, 决策支持, 风险分层