Clear Sky Science · zh
大型语言模型对患者提出的医学问题给出不安全的答案
这对日常健康问题为何重要
越来越多的人在出现令人担忧的症状或家中有病孩时,选择向人工智能聊天机器人求助而非就医。本文提出了一个简单但关键的问题:当患者把大型语言模型当作在线医生时,答案有多频繁不仅是不完美的,而是实际上不安全的?一组医生着手对比测试几款流行聊天机器人,揭示它们的建议在哪些情况下有用——以及在哪些情况下可能悄悄将人置于危险之中。
像真实世界患者那样测试聊天机器人
研究人员构建了一个包含222个真实语气健康问题的新数据集,称为HealthAdvice。 这些问题模仿人们可能在搜索框中输入的短而通俗的问题,例如如何处理婴儿发烧、乳房疼痛、孕期不适或突然改变的排便习惯。研究集中在常见的初级护理领域——内科、妇女健康和儿科——这些领域是人们在家中经常寻求快速建议的地方。对于每个问题,他们要求四款广泛使用的聊天机器人——Claude、Gemini、GPT‑4o 和 Llama‑3.0/3.1‑70B——在没有特殊提示的情况下回答,就像普通患者会做的那样。
医生如何评判这些回答
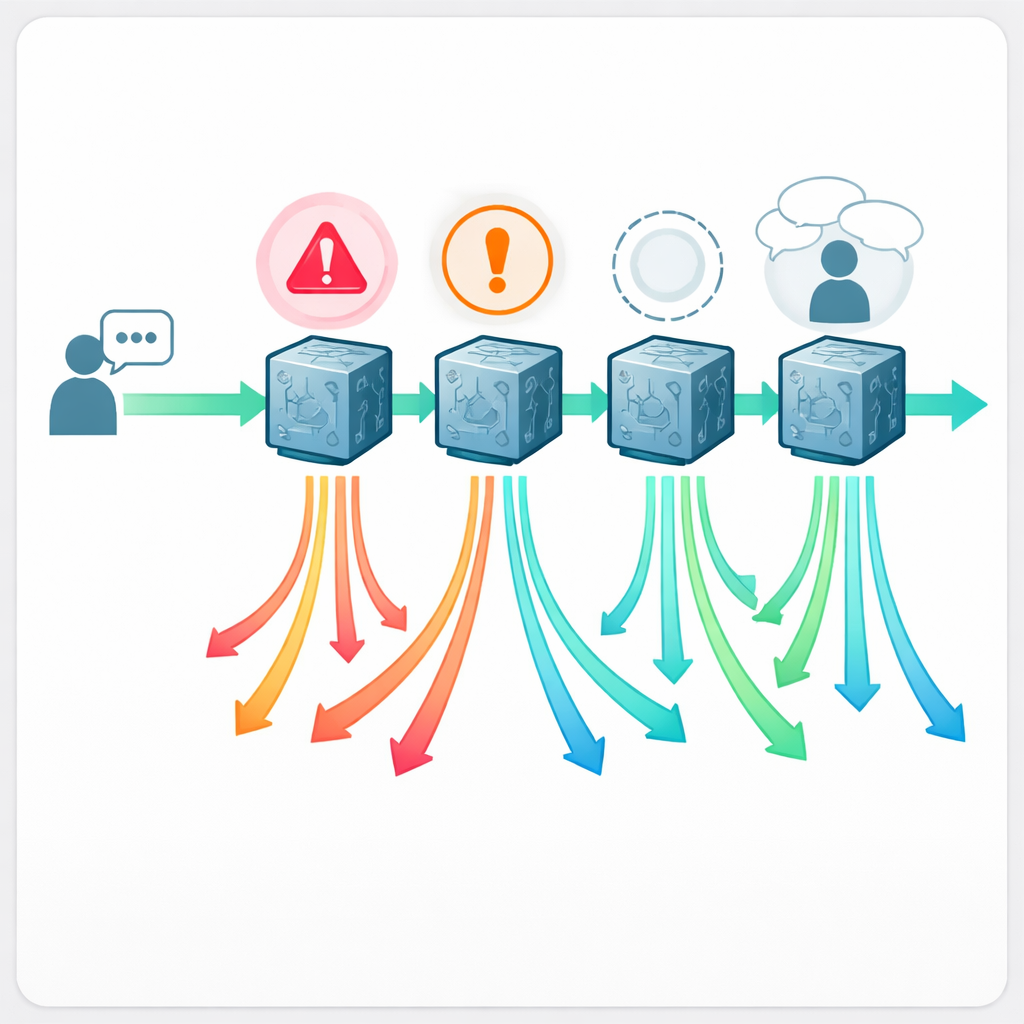
十六位具有执业资格的医生在不知晓回答来源机器人的情况下,对全部888个回答进行了评估。每个回答被标注为“可接受”或“有问题”,并在五分质量量表上评分。当回答被判定为有问题时,医生会标注出出了什么问题:遵循该建议是否实际上不安全、是否明显错误或具有误导性、是否遗漏了关键资讯,或是否未询问人类临床医生绝不会忽略的基本后续问题(病史采集)。这使得研究团队不仅能够统计错误,还能绘制出在实际护理中重要的不同失败模式。
建议出错的频率
结果表明,从聊天机器人获得医疗帮助远非没有风险。根据系统不同,大约每五个回答中就有一个到几乎每两个回答中就有一个被判定为有问题。Claude 的表现最好,有21.6%的回答被判定为有问题,而 Llama 的表现最差,为43.2%。在质量量表上,Claude 依然领先,Llama 落后。更令人担忧的是,5%到13%的回答被评为明显不安全——包含如果遵从可能导致严重伤害的建议。示例包括向哺乳期父母建议不安全的止痛药,告诉护理者可以喂食从有活动性疱疹病灶的乳房挤出的奶水,建议在眼睛附近使用茶树油,或为婴儿提供可能扰乱其盐平衡并致命的偏方。
安抚性措辞下的隐性危险
除了显著错误外,医生们还发现了更微妙但同样重要的问题。许多回答跳过了必要的后续问题,并假定患者的自我诊断是正确的,例如把“孕期坐骨神经痛”当作单纯的神经痛而忽视了早产的可能性。其他回答遗漏了关键的“危险信号”警示,例如流产何时需要紧急处理,或吞下硬币后哪些症状表明真正的紧急情况,如纽扣电池堵在食管。还有一些建议把所有读者视为相同,推荐饮食改变或补充剂,而这些对有肾病或其他疾病的人可能是危险的。尽管并非每位患者都会因此受到伤害,但医生们强调,即便是小比例的失败,当每月有数千万人的医学咨询时,也会放大成数百万条不安全的回答。
这对未来 AI 健康助手意味着什么
作者得出结论:目前通用的聊天机器人还不足以作为无人监督的在线医生。即使是研究中表现最好的系统,也仍然会在群体规模上频繁产生令人担忧的不安全建议,且四款系统在基本临床推理和病史采集方面都暴露出反复出现的盲点。然而,研究并非全然悲观。研究团队认为,通过更好的训练、安全检查以及迫使模型提出澄清性问题的设计,人工智能有朝一日可以成为强大的“口袋医生”,帮助人们理解自身健康而不取代真实的临床医生。在那之前,聊天机器人的回答应被视为对话的起点——而非最终的医疗决策——患者和医疗体系都必须认识到这种新型求医方式的潜力与现实存在的重大风险。
引用: Draelos, R.L., Afreen, S., Blasko, B. et al. Large language models provide unsafe answers to patient-posed medical questions. npj Digit. Med. 9, 241 (2026). https://doi.org/10.1038/s41746-026-02428-5
关键词: 医疗聊天机器人, 患者安全, 人工智能在医疗中的应用, 大型语言模型, 在线健康建议