Clear Sky Science · zh
用于智能手术的大规模自监督视频基础模型
手术室中的更智能辅助
现代外科医生越来越依赖摄像头和计算机来指导操作,但当前的人工智能仍难以完全理解手术过程中发生的事情。本文提出了一种新的方法,在数千个手术视频上训练 AI,使其能够更好地跟踪手术步骤、识别器械和组织,并评估手术进行的安全性与技艺水平。从长期来看,这类技术可以实时支持外科医生、改进培训,并有助于提高患者手术的安全性。
为什么教机器理解手术很难
让计算机理解手术并非只需喂给几张带标签的图片那么简单。每台手术都涉及移动的摄像头、不断变化的视角、烟雾、血液,以及互相遮挡的手和器械。此外,手术种类繁多,许多操作十分罕见。逐帧精确标注视频数据需要稀缺的专家时间,成本迅速飙升。早期的 AI 系统试图通过从未标注图像中学习来减轻这一负担,但它们大多只关注静态帧,后来才尝试加入时间维度。因此,它们常常错过手术展开的故事线:之前发生了什么、现在正在发生什么以及接下来可能会发生什么。
直接从手术视频中学习
作者认为,用于辅助手术的 AI 应该在视频而非孤立图像上进行训练。为此,他们汇集了迄今为止最大的内镜手术视频集合之一:3,650 个录像,包含 355 万帧,来源于公开研究数据集和大量在线手术素材。这些视频覆盖 20 多种手术和 10 多个解剖区域,从胆囊切除到肝脏手术和妇科手术。多样性使 AI 能够看到真实世界中同一手术的多种表现,包括不同医院、器械和摄像风格。
以视频为中心的新学习蓝图
基于这笔数据财富,团队设计了 SurgVISTA,一种专门针对手术视频调优的“基础模型”。SurgVISTA 不再试图标注每一帧,而是通过填补缺失内容来学习。在训练过程中,每个视频片段的部分区域会被遮挡,模型必须重建这些缺失区域。这迫使它关注组织、器械和运动随时间的变化。同时,系统的第二个分支被训练去匹配一位已有丰富手术场景知识的强图像专家模型所捕捉到的细致视觉线索。二者结合使 SurgVISTA 在同一统一网络中既能把握每帧的细节,也能理解整个手术的更广泛流程。
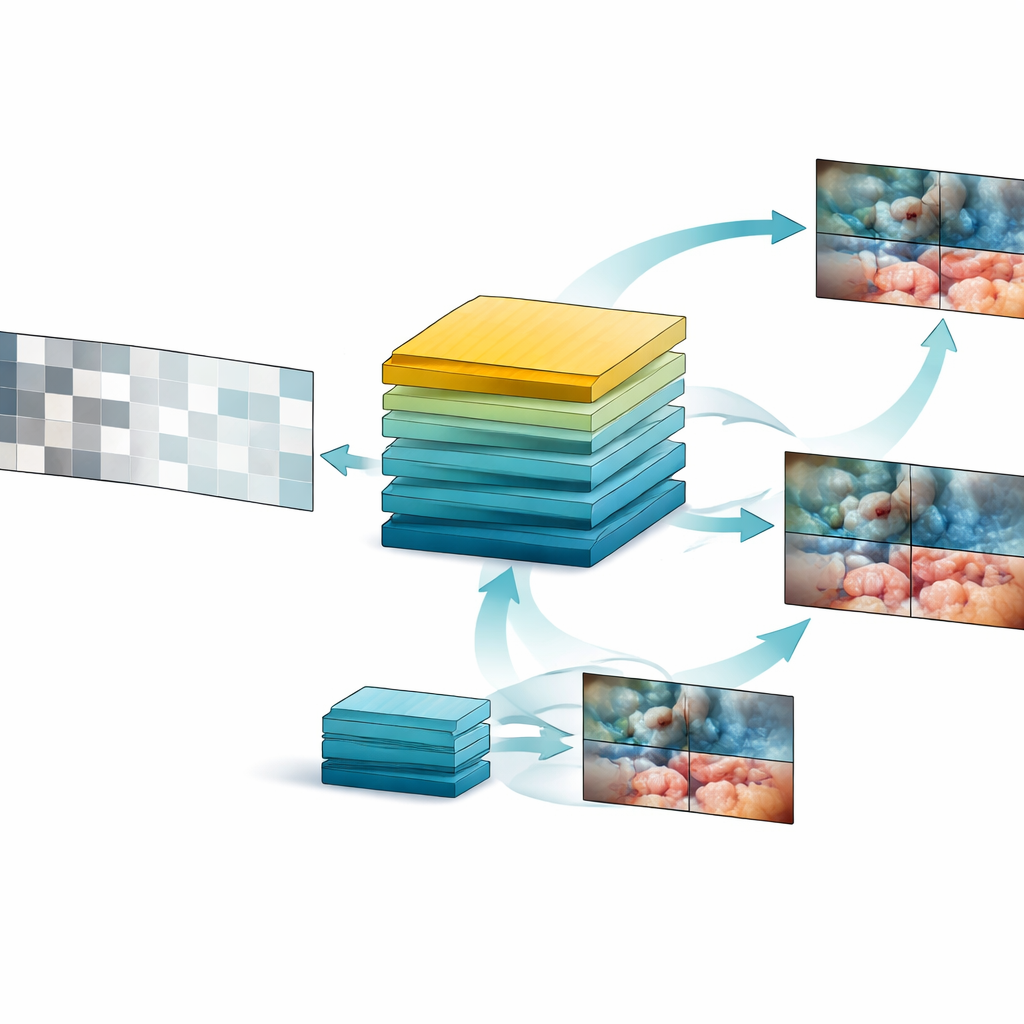
将模型付诸考验
为了检验这种方法是否真正奏效,作者在 13 个不同数据集上测试了 SurgVISTA,这些数据集涵盖 6 类手术和 4 项实际任务。任务包括识别当前手术处于哪个阶段、判定具体手术动作、捕捉器械—动作—目标组织之间的三向关系,以及评估关键步骤的执行安全性。在各项测试中,SurgVISTA 均超越了那些在日常视频上训练的领先模型,以及以静态图像为主的现有最佳手术专用系统。即便在训练中未见过的手术上,SurgVISTA 也表现出色,表明其学习到的模式并未局限于单一器官、器械组合或医院环境。
为何更多且更丰富的视频数据很重要
研究还探讨了随着训练数据增多性能如何变化。随着作者逐步扩展视频池的规模与多样性,SurgVISTA 的结果几乎在所有方面都有提升,包括那些没有出现在训练集中的手术。有趣的是,模型不仅从更多同类手术样本中受益,也从不同类型手术中获益:接触多样的手术“故事”帮助它发现可跨专科迁移的一般视觉与运动模式。额外的实验表明,来自图像专家的额外引导进一步提升了模型保留精细解剖细节的能力,这对于将重要结构与周围组织区分开来至关重要。
这对未来手术意味着什么
简而言之,这项工作表明,在大量真实手术视频上、考虑空间与时间的情况下训练的 AI,能够构建对手术室内发生内容的更深理解。SurgVISTA 尚未成为可以独立决策的工具,但它提供了一个强大的骨干,其他应用可以接入该骨干——无论是用于跟踪手术进展、标记危险时刻、支持培训,还是比较不同医院间的技术。作者指出,仍需更广泛的数据与临床测试,但他们的结果表明,基于视频的基础模型可能成为未来智能手术系统的关键组成部分,旨在使手术更安全、更一致并更贴合每位患者的需求。
引用: Yang, S., Zhou, F., Mayer, L. et al. Large-scale self-supervised video foundation model for intelligent surgery. npj Digit. Med. 9, 220 (2026). https://doi.org/10.1038/s41746-026-02403-0
关键词: 手术视频人工智能, 自监督学习, 手术流程, 计算机辅助手术, 时空建模