Clear Sky Science · zh
大型语言模型提高基于电子病历的预测在不同国家和编码系统间的可迁移性
为何更智能的医疗数据共享至关重要
世界各地的医院和诊所都掌握着一座信息金矿:电子病历记录了人们多年来的诊断、治疗和结果。理论上,这些信息可以帮助医生及早识别高风险人群,在症状明显出现之前采取干预。实际上,当今的计算模型难以从一个国家或医院系统“迁移”到另一个系统,因为各处记录健康数据的方式不同。本研究提出了一种名为 GRASP 的新方法,利用人工智能的进展弥合这些差距,使在一个卫生系统中训练的模型能够在其他系统中可靠运行。
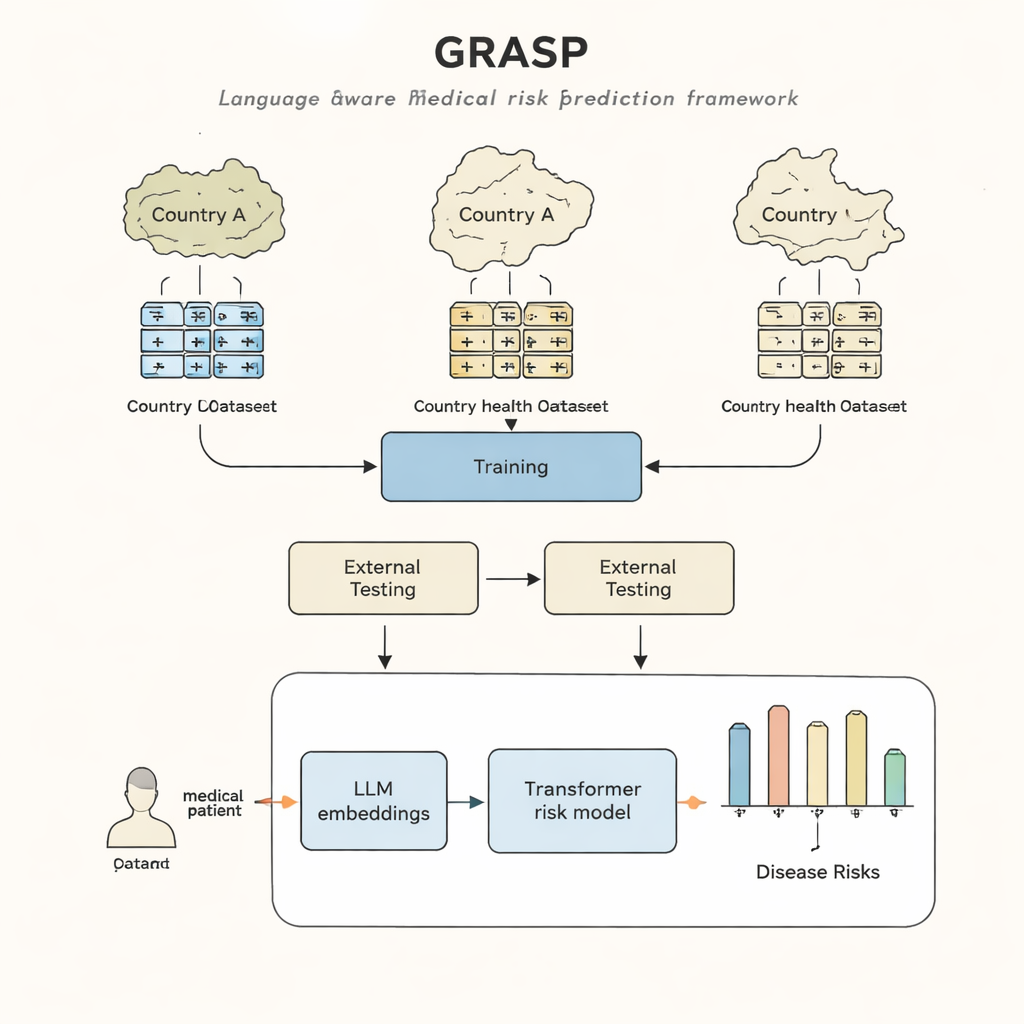
不同医院,不同“语言”
即便医生治疗相同的疾病,记录方式也常因编码体系和本地习惯而异。一家医院可能用某个代码记录“血糖偏高”,另一家则用不同的代码记录“高血糖”,第三家则可能采用完全不同的系统。虽然推动各方采用统一标准(例如大型国际编码方案)有其价值,但进程缓慢、成本高昂,且仍然无法消除重要差异。因此,在一个国家的病历上训练出的疾病预测模型在其他地方应用时可能会丧失精度,限制了这些工具的普惠性。
让人工智能读懂含义,而非只看代码
GRASP 的出发点很简单:与其把每个医疗代码当作毫无意义的 ID 号,不如让大型语言模型阅读其背后的人工描述,例如“急性上呼吸道感染”,并将该含义转换为数值“嵌入”向量。这些嵌入把相关概念在共享空间中靠近,即使它们来自不同的编码系统或国家。GRASP 对数百万个标准医疗术语预先计算此类嵌入并将其存入查找表。患者的病史随后以这些丰富向量的序列表示,输入到 Transformer 网络(一种擅长处理多样输入集合的神经网络)中,用于估计该人对 21 种主要疾病的风险以及总体死亡风险。
跨国家与记录系统的测试
研究人员使用近 40 万名英国生物样本库(UK Biobank)参与者的数据训练了 GRASP,然后在不重新训练的情况下在两种截然不同的环境中进行测试:芬兰的 FinnGen 项目和纽约市的一家大型医院网络。GRASP 与包括流行方法 XGBoost 以及未使用基于语言嵌入的类似 Transformer 在内的强基线相比,表现持平或更好。在芬兰,GRASP 表现尤为优异,对哮喘、慢性肾病和心力衰竭等疾病显示出明显的提升。值得注意的是,即使将美国医院数据保留在不同编码方案而未转换为共享标准,GRASP 仍然比仅基于人口学的预测更准确,因为它可以仅通过理解描述文本来对齐编码。
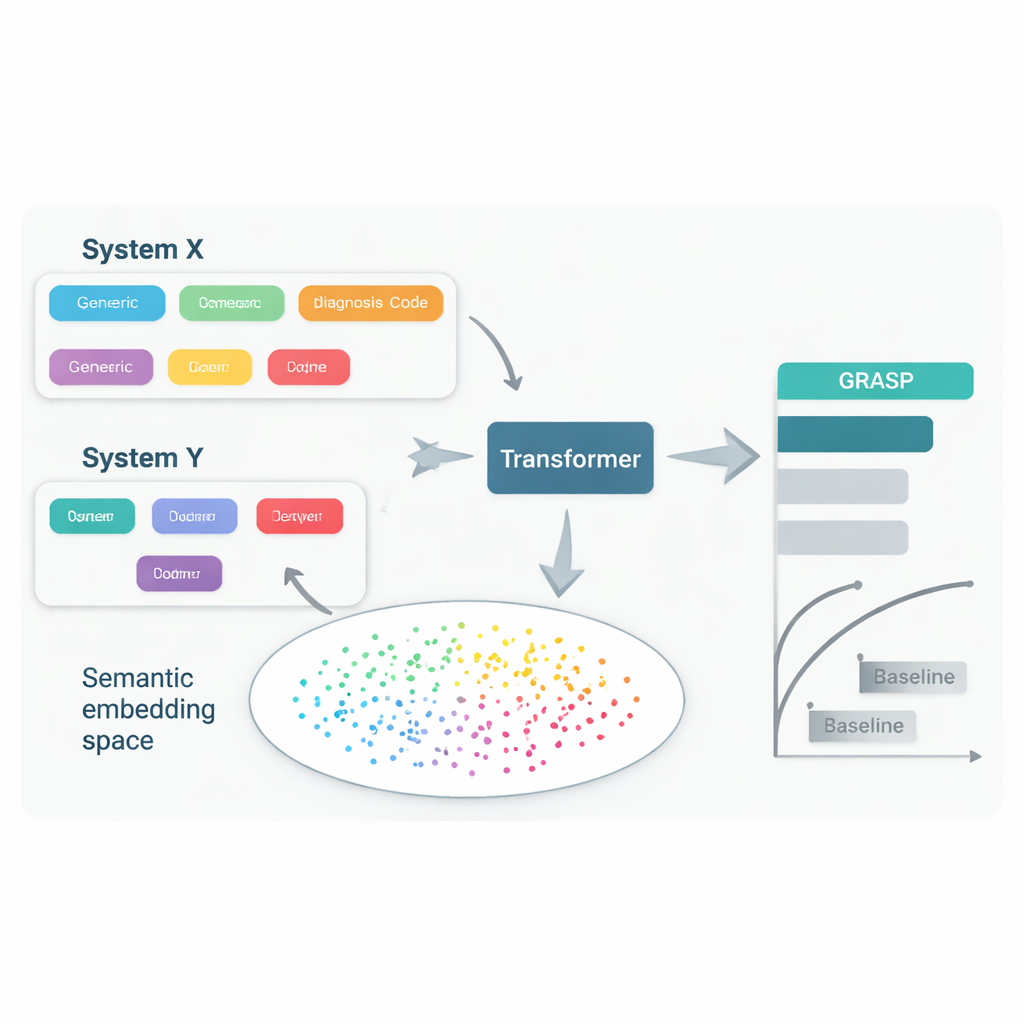
用更少的数据得到更多信息
GRASP 的另一个优点是效率。由于语言模型已学会许多医疗概念之间的关联,预测网络无需从头重新发现这些联系。当作者在规模更小的英国数据子集上训练 GRASP——最少仅使用 1 万人样本——它仍优于在相同有限样本上训练的竞争模型,无论是在英国本地还是迁移到国外时。GRASP 的风险评分也与若干疾病的遗传易感性更紧密地对齐,这表明它捕捉到的是疾病易感性的更深层面,而不仅仅是在一个数据集中记忆模式。
这对未来医疗意味着什么
对非专业读者而言,关键是 GRASP 展示了基于现代语言的人工智能如何在不强制采用单一僵化编码方案的情况下,帮助不同卫生系统“说同一种语言”。通过读取医疗术语的含义,GRASP 能在跨国家和不同记录格式中提供更具泛化性的疾病风险预测,而且所需的患者样本更少。尽管这种方法在日常临床使用前仍需经过详尽测试、再校准和公平性检查,但它指向了这样一个未来:在一处开发出的强大风险工具可以被安全且高效地分享给世界各地的医院和诊所。
引用: Kirchler, M., Ferro, M., Lorenzini, V. et al. Large language models improve transferability of electronic health record-based predictions across countries and coding systems. npj Digit. Med. 9, 177 (2026). https://doi.org/10.1038/s41746-026-02363-5
关键词: 电子病历, 疾病风险预测, 大型语言模型, 医疗数据共享, 医疗保健人工智能