Clear Sky Science · zh
比较去中心化的机器学习与 AI 临床模型与本地和集中式替代方案:一项系统评价
为何在不共享数据的情况下共享医疗洞见很重要
现代医学越来越依赖人工智能来更早地发现疾病、选择合适的治疗方案并预测谁的风险最高。然而,最好的 AI 工具需要大量患者数据,而医院无法简单地合并其记录,因为存在严格的隐私法律和伦理问题。本文回顾了十多年的“去中心化”学习研究——即允许医院在不共享原始患者数据的情况下共同训练 AI 的方法——并提出一个务实的问题:这些保护隐私的方法与传统方法相比,实际表现如何?
在保护隐私的同时从患者中学习的新方法
在传统的集中式学习中,医院将所有数据复制到一个大型数据库并在此处训练单一模型。在本地学习中,每个机构在自己的数据上构建自己的模型,完全不进行协作。去中心化学习提供了一条中间路径。例如,在联邦学习中,每家医院在本地训练模型,然后仅将模型的参数(如神经网络中的“旋钮”)发送出去以合并为共享模型;患者记录永远不会离开本地。Swarm learning 则去除了中央协调者,使机构能够直接交换模型更新。其他去中心化方法将多个本地模型的预测进行集成,或将模型在不同站点之间拆分。这些方法已在从癌症检测和 COVID-19 诊断到心脏病、糖尿病、脑部疾病和精神病学状况等多种问题上进行测试。
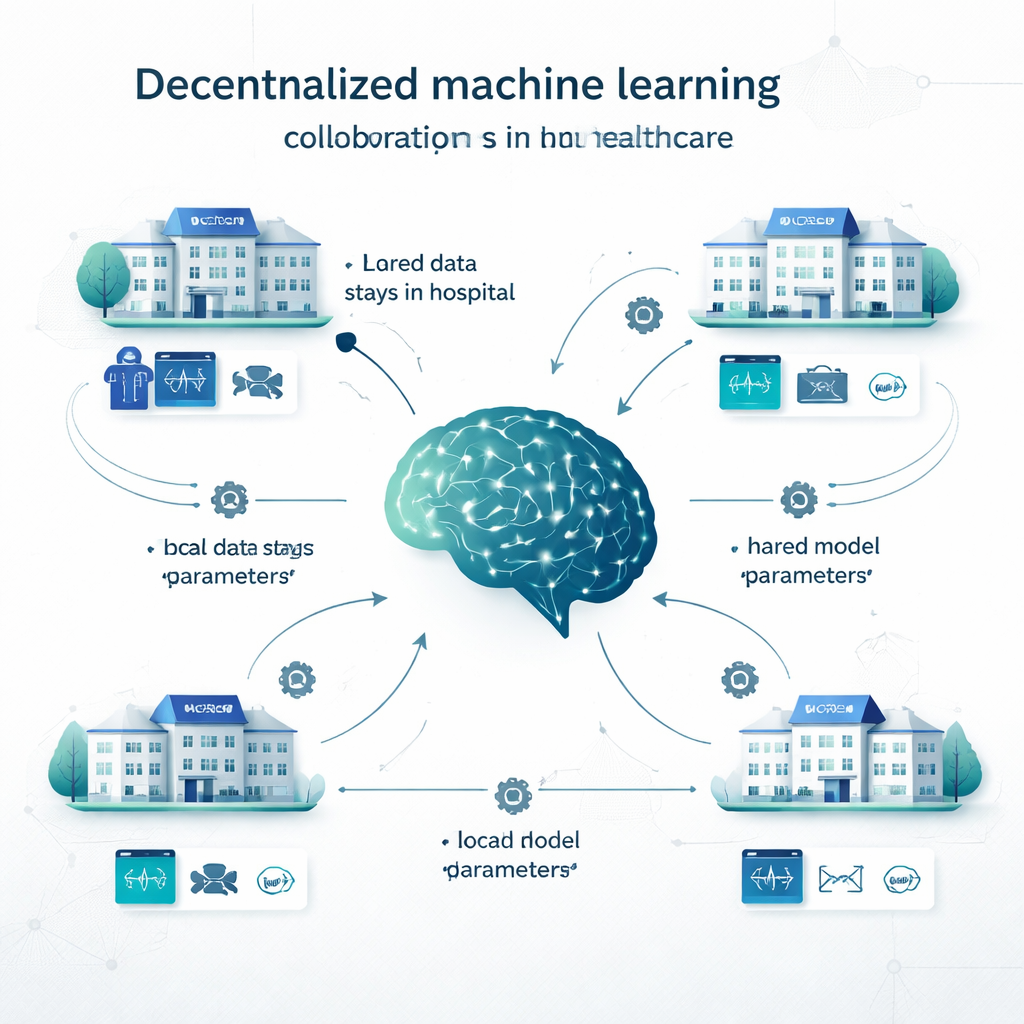
研究者审查了什么
作者系统性地检索了 11 个主要数据库,并对 2012 年至 2024 年 3 月间发表的 165,010 篇研究进行了筛选。在去除重复项和不涉及真实临床决策的研究后,剩余 160 篇文章。总体上,这些论文报告了 710 个去中心化模型和 8,149 项与集中式或本地模型的直接性能比较。大多数研究集中于诊断,但也有许多关于图像分割(例如描绘肿瘤)、预测生存或并发症等未来结局以及联合任务的研究。所涵盖的数据类型几乎包括医学中使用的所有主要来源:电子健康记录、CT 和 MRI 扫描、X 光、数字病理切片、心脏和脑电信号,甚至基因数据。
隐私保护模型与集中式 AI 的对比表现如何
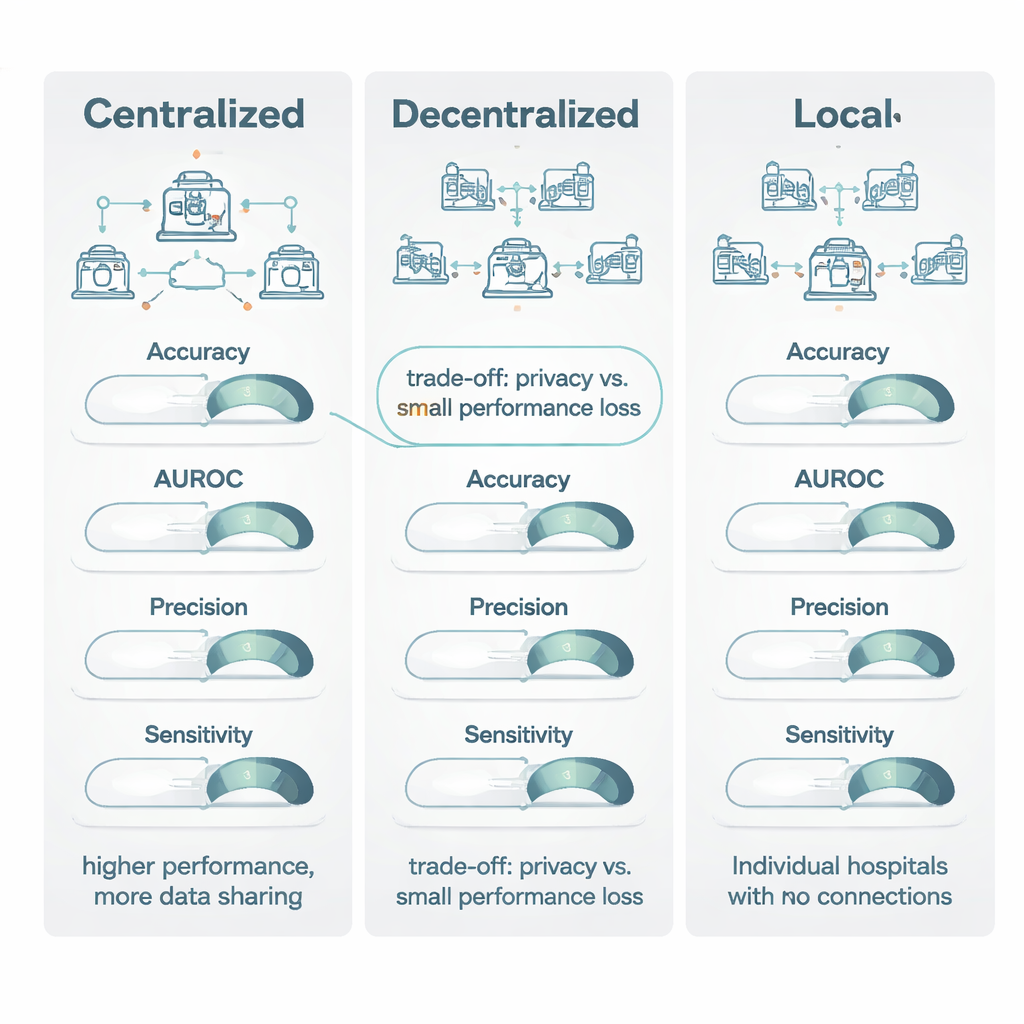
当将去中心化模型与在汇总数据上训练的集中式模型进行比较时,集中式学习通常略占上风。它在像准确率和常见的成像评分 Dice 系数这类“阈值型”指标上表现尤其好,大约有四分之三的情况下集中式获胜,且优势通常被认为是中等到较大。然而,在排序类指标上——例如描绘模型将患者按风险从低到高排序能力的受试者工作特征曲线下面积(AUROC)——去中心化与集中式模型差距较小,集中式仅有小幅领先。重要的是,当两种模型都达到作者所称的“临床可行”性能(分数至少 0.80)时,集中式模型的典型增益通常很有限:常常不到 1–1.5 个百分点。在许多情形下,这意味着“优秀对可接受”,而不是“可用对无用”。
为何去中心化学习优于单打独斗
在将去中心化模型与纯本地模型比较时,综述中出现的最强信号最为明显。跨越所有主要指标——准确率、AUROC、F1 分数、灵敏度、特异度,尤其是精确度——去中心化方法几乎总是表现更好,且常常优势显著。在正面比较中,去中心化学习在关键指标(如准确率、精确度和 AUROC)上的表现优于本地模型的比较中超过 80%。在许多情况下,本地模型未能达到 0.80 的临床有用性阈值,而相应的去中心化模型则轻松超过该阈值,灵敏度最多提高了 27 个百分点。作者将此归因于多中心模型获得的更广泛经验:通过“看到”来自多家医院的模式,它们不易被特定医院的扫描仪或记录惯例所误导,更能识别真正具有普适性的疾病特征。
在性能、隐私与实际应用之间取得平衡
该综述得出的结论是:在隐私法规和后勤允许合并数据且每一点性能都至关重要的情况下(例如非常罕见的疾病),集中式学习仍然是金标准。然而,在像 GDPR 和欧盟人工智能法案等法律或机构政策限制数据共享的情形下,去中心化学习提供了强大且临床可接受的替代方案。与完全保持模型本地化相比,去中心化方法在保持数据留在医院内的同时,在准确性和可靠性方面提供了显著提升。作者认为未来的工作应更清晰地报告隐私技术和计算成本,以便医疗系统在面对轻微性能权衡时,能基于隐私和协作带来的实质性好处做出明智选择。
引用: Diniz, J.M., Vasconcelos, H., Rb-Silva, R. et al. Comparing decentralized machine learning and AI clinical models to local and centralized alternatives: a systematic review. npj Digit. Med. 9, 174 (2026). https://doi.org/10.1038/s41746-025-02329-z
关键词: 联邦学习, 医疗保健人工智能, 医疗数据隐私, 去中心化机器学习, 临床预测模型