Clear Sky Science · zh
跨精神病谱系的多模态语音分析中的不确定性建模
在日常谈话中倾听隐秘线索
人们通常把精神病视为突发且戏剧性的事件——幻听、幻视以及与现实的脱节。但在危机发生之前很久,说话方式中的细微变化就可能出现:音色、用词选择,甚至句子的节奏。该研究探讨了计算机是否能够捕捉到语音中这些微弱信号,并且最关键的是,能够说明它对所“听到”内容的置信程度。这样一来,研究指向了未来可能帮助临床医师更客观跟踪心理健康并在从轻度风险到完全发病的整个范围内实现个性化护理的工具。
从随意交谈到临床访谈
研究人员记录了114名以德语为母语的志愿者的语音,涵盖精神病谱系的不同人群:既有早期精神病患者,也有未确诊但表现出低或高精神病样特质(称为分裂型人格特质)的人。每位参与者完成了四种语音任务,从结构化的临床访谈到更自由的自传式叙述、基于图片的讲故事以及日常对话。这些不同的情境很重要,因为严格引导的访谈可能会凸显某些症状,如情感平淡,而开放式叙述可能暴露出思维游离或异常感知。通过跨情境取样,研究团队可以观察语音在更接近真实世界的情况下对症状的指示有多可靠。
同时听取我们的说话方式与内容
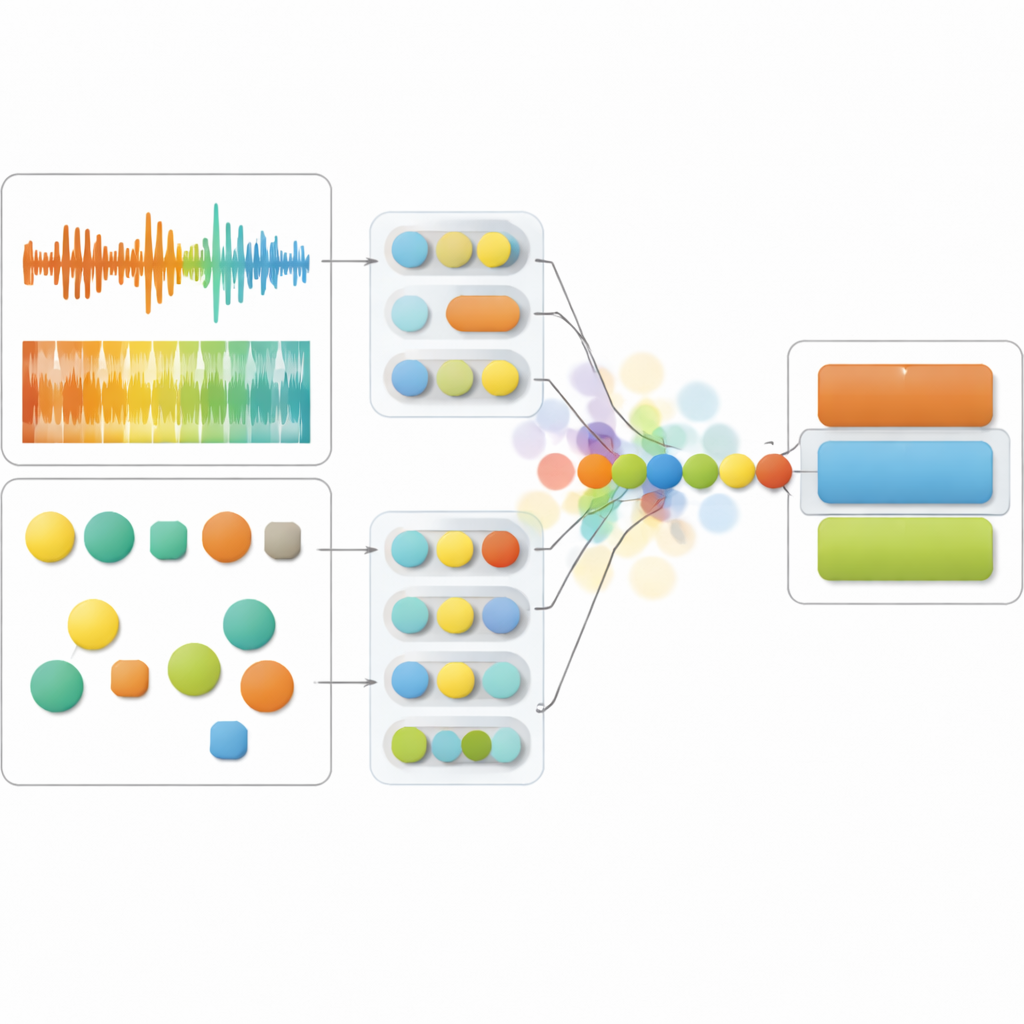
该研究的系统同时监听语音的两面。在声音层面,它跟踪音高变化、响度以及声音的精细结构等特征,这些特征共同捕捉了表现力、紧张感和流畅性。在语言层面,它分析词语本身——情感色彩、是否关注感知或社会联系,以及连贯程度。最初在大量音频和文本上训练的先进神经网络将这些原始信号转化为紧凑的数值指纹。核心模型随后在时间上融合这些指纹,从而能够逐时判断哪一通道——声音或语言——为某人心理状态提供了更可靠的线索。
教会模型承认不确定性
这项工作的不同之处在于,模型不仅输出预测结果,还会估计自身的不确定性。它不把音频和文本流视为固定不变,而是把它们表示为概率云,数据噪声大或异常时这些云会膨胀。如果录音失真或说话含糊,系统会降低对声音的权重,更依赖词语;如果转录不可靠或语音极度碎片化,则相反。这种具有不确定性感知的融合方法,称为时间上下文融合(Temporal Context Fusion),取得了良好性能:在区分低分裂型、 高频裂型和早期精神病群体时达到83%的F1分数,并表现出良好校准的置信度,意味着其声明的确定性与实际正确的频率密切吻合。
反映不同症状类型的语音模式
通过探查模型的内部机制,研究人员识别出哪些语音方面最稳定地与不同症状维度相关。表现出更强烈阳性症状(如异常体验或妄想性想法)的人,往往呈现更高且更可变的音高、声音频谱的快速变化以及更大的响度波动,尤其在开放式讲述中明显。他们的语言也包含大量感知相关词(与看、听或感知有关)和带有强烈情感色彩的词。相比之下,表现出更强负性症状(如社交退缩和情感淡漠)的人说话更单调,音高受限、发音灵活性较低,并使用较少的正面情绪词和社会类词。组织紊乱的特质,无论是在患者还是在高分裂型志愿者中,表现为响度不稳定、犹豫和碎片化的语言,充斥着风险相关词和认知过程词,暗示存在心智努力但缺乏清晰结构。
为何这对未来精神健康护理重要
综合来看,研究结果表明,语音携带着可测量的与精神病相关的特质痕迹,即便在未达到临床疾病标准的人群中也是如此,而且这些痕迹会随发言情境的不同而变化。具备不确定性感知的模型能够同时利用声音与语言来追踪阳性、阴性和组织紊乱特征的连续体,同时在证据薄弱时公开表明其不确定性。对普通读者而言,关键观点是:经由人工智能放大的细致倾听——且该人工智能了解自身的局限——最终可能帮助临床医生更客观地监测心理健康、减少猜测并更早发现有意义的变化。这类工具并非取代人类判断,而可作为第二只耳朵,突出日常语言中值得进一步关注的模式。
引用: Rohanian, M., Hüppi, R., Nooralahzadeh, F. et al. Uncertainty modeling in multimodal speech analysis across the psychosis spectrum. npj Digit. Med. 9, 218 (2026). https://doi.org/10.1038/s41746-025-02309-3
关键词: 精神病, 语音分析, 机器学习, 心理健康评估, 多模态人工智能