Clear Sky Science · zh
IMFLKD:一种基于知识蒸馏的去中心化联邦学习激励机制
为什么共享可以既安全又公平
现代人工智能依赖数据,但我们的大部分数据都存储在个人手机、医院服务器或公司云端,无法被随意复制或共享。联邦学习为众多设备在不暴露原始数据的情况下共同训练共享模型提供了途径,但现有系统仍面临隐私泄露、中心化单点故障以及对高贡献者回报不公平等问题。本文提出了一个新的框架 IMFLKD,将区块链、知识蒸馏和信誉评分这三种强大思想结合起来,以实现更具隐私保护性、更具鲁棒性并在长期内更公平的集体学习。
在不泄露秘密的情况下共同训练
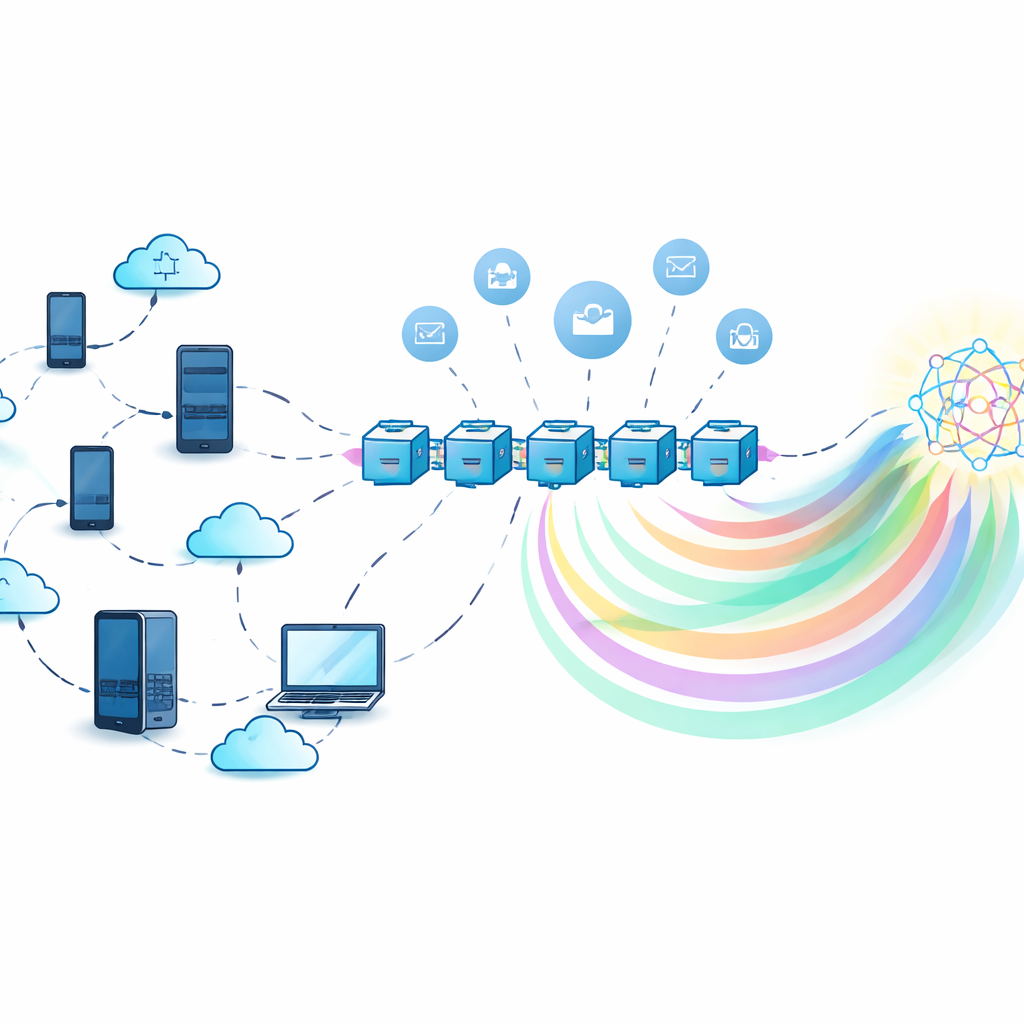
在经典联邦学习中,中央服务器收集来自多个参与者的模型更新并进行合并。这确实避免了原始数据的传输,但服务器自身成为了诱人的攻击目标:若其故障,整个系统停滞;若其不值得信任,便可能滥用或泄露蕴含在模型更新中的信息。作者改用去中心化的区块链账本来协调训练。每个参与者在本地用自己的数据训练模型,然后与区块链上的智能合约交互,智能合约记录贡献、聚合信息并分配奖励,从而无需依赖单一中心化权威。
共享知识,而不是庞大模型
为降低通信成本并进一步保护隐私,框架依赖知识蒸馏。参与者不是传输完整的模型参数,而只发送“软标签”——模型对一组共享输入的预测概率分布——这些信息更轻量,也较少暴露单个用户数据的细节。由于真实的共享数据集可能不存在,系统使用一种条件变分自编码器生成合成的“伪公开”数据集,该数据集大致匹配整体标签分布但不暴露任何原始记录。参与者在本地数据上训练、对该合成数据集做出预测,然后使用来自所有参与者合并知识的聚合信号来改进模型。
衡量谁真正有贡献
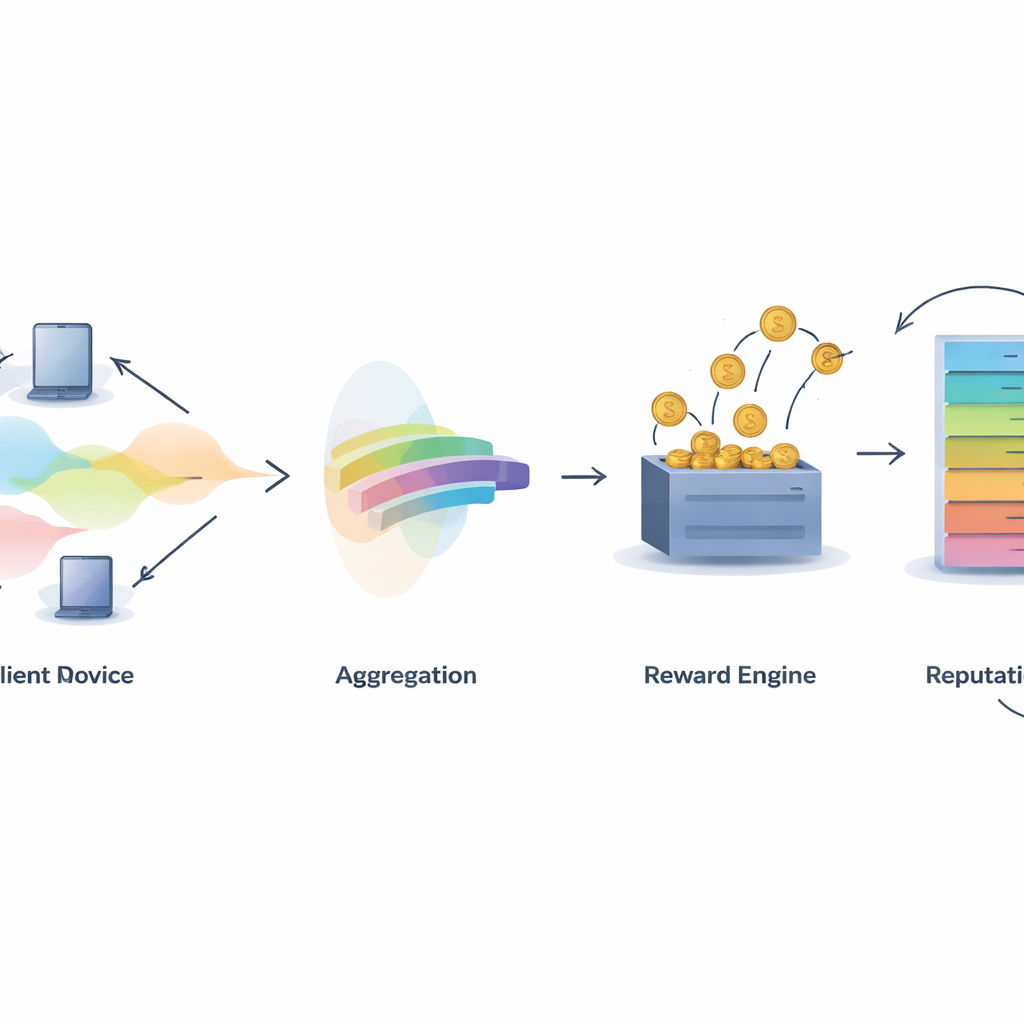
在任何协作系统中,决定谁应得到功劳是一大难题。IMFLKD 通过基于标签聚合的两阶段贡献评估方法来应对这一问题。首先,一个轻量的贝叶斯算法检查所有参与者的预测,推断每个样本的最可能真实标签以及每个模型的质量评分,并随着新任务到来而更新这些评分。这种方法可在线运行,无需存储历史数据,并能通过降低经常与新共识相左的模型权重来处理噪声或恶意参与者。实验表明,与简单多数投票相比,这种标签聚合能把精度提升约 10%,同时保持足够快速以适应大规模、资源受限的环境。
将质量转化为奖励与信誉
一旦贡献质量被评估出来,IMFLKD 使用一种称为加权同行真实信号(weighted peer truth serum)的激励方案将其转化为奖励。参与者的表现与经过质量加权的同行共识进行比较:那些预测与高质量同行一致的参与者获得更多奖励,而偏离或经常不一致的参与者会受到惩罚。这使得诚实报告在长期内成为最有利的策略,即便面对合谋行为也能保持激励效果。除此之外,系统为每个参与者构建多维度的信誉评分,综合数据质量、活跃度和行为稳定性,并对较旧行为施加时间衰减因子。信誉随后反馈到后续回合,影响参与者预测的权重以及是否被选中参与未来任务。
在集体智能中建立信任
总体上,IMFLKD 框架表明可以在众多独立设备之间以高效、注重隐私并能抵抗搭便车者与攻击者的方式协调学习。通过将合成数据生成、严格的贡献评分、博弈论式的奖励机制与基于区块链的动态信誉跟踪相结合,系统鼓励参与者在多轮训练中保持诚实与稳定。对于非专业读者而言,结论是:我们可以利用分布式数据(如医疗记录、传感器读数或个人设备数据)的集体力量,而无需将一切交给单一公司或服务器,同时确保真正提供最有用信息的人能够获得最多的利益。
引用: Ying, X., Yan, K., Gao, X. et al. IMFLKD: an incentive mechanism for decentralized federated learning based on knowledge distillation. Sci Rep 16, 10567 (2026). https://doi.org/10.1038/s41598-026-46234-1
关键词: 联邦学习, 区块链, 知识蒸馏, 激励机制, 信誉系统