Clear Sky Science · zh
使用机器学习检测反兴奋剂调查中的样本调包
为何抓住聪明作弊者至关重要
精英体育依赖信任:当运动员获胜时,我们希望相信结果是公平的。现代药检非常灵敏,然而一些运动员试图通过秘密调换尿样来规避检测。该研究展示了机器学习如何识别运动员重复使用先前采集的“干净”样本,这一伎俩用现行常规检查极难发现。该工作指向了通过悄然扫描庞大检测数据库以寻找篡改隐藏证据的新途径,从而保护公平竞赛。
现有检测中的一个隐蔽漏洞
反兴奋剂实验室通常检测尿液,因为许多禁用药物及其代谢产物在尿中可长期检测到。运动员的天然类固醇激素谱在运动员体征档案(Athlete Biological Passport)中被长期追踪,因此这些数值的突然跳变可能触发调查。将他人尿液调入会破坏这一长期模式,往往可被发现。真正的盲点出现在运动员秘密重复使用自己早先的无药物尿样时。在这种情况下,类固醇谱完美地融入其历史记录,如果样本在不同实验室或较长时间后检测,目前没有自动方法能注意到两份样本在本质上是相同的。
将尿液化学转化为可检索的模式
作者通过关注尿液中一组天然类固醇及其比值形成的详细“指纹”来解决这一问题。他们收集了来自世界反兴奋剂机构(WADA)认证实验室的67,651份类固醇谱,采自2021年至2023年,涵盖男女运动员。每份谱包含关键激素如睾酮及若干相关化合物,以及它们之间的比值。由于样本重复使用的真实案例罕见且保密,研究团队将这些真实世界数据与精心构建的合成谱对相结合:一些谱对通过加入小幅、现实的测量噪声被制成“相似”,另一些则通过随机配对不同运动员的样本被制成“不相似”。这为计算模型提供了平衡的训练材料,使其学会在实践中“几乎完全相同”是什么样子。
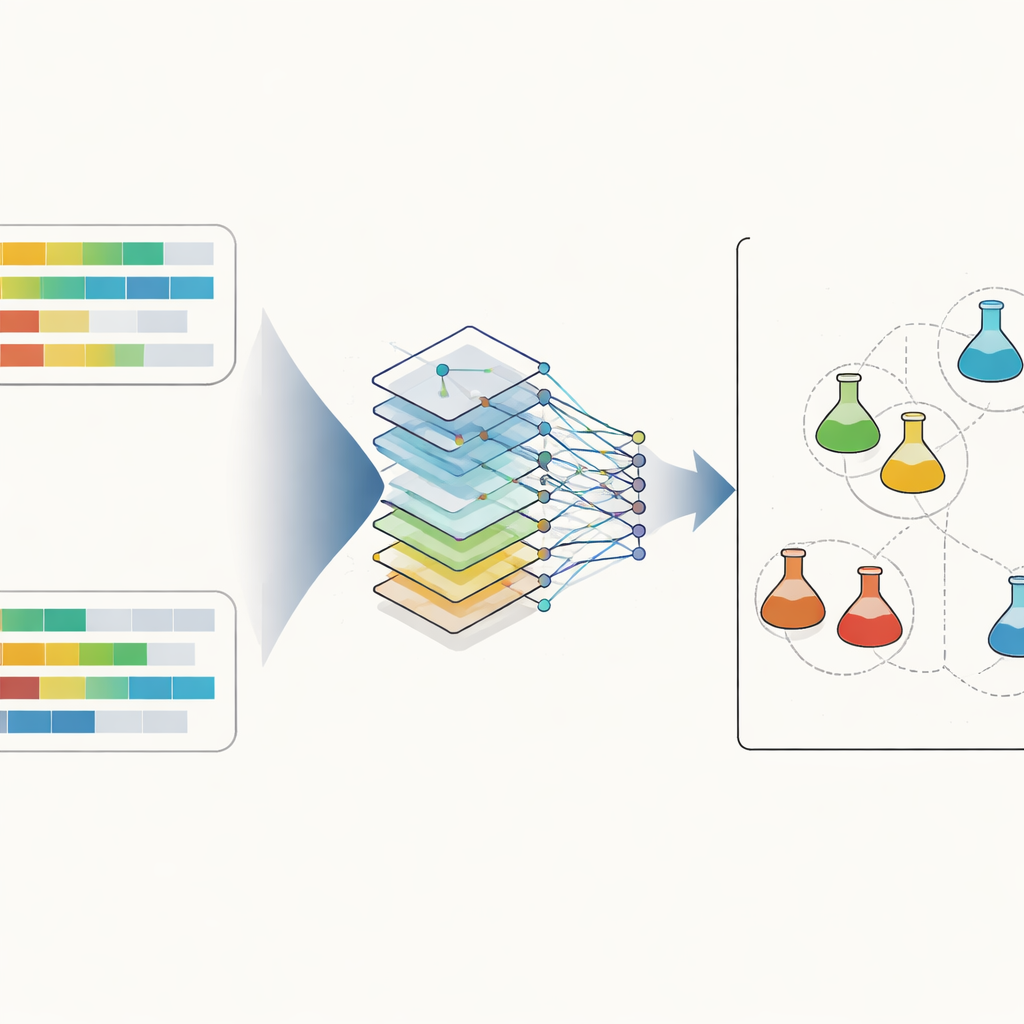
智能检测器如何工作
系统的核心是一种称为卷积网络的人工神经网络,广泛用于图像识别。在这里,输入不是图片,而是一对并列排列的类固醇谱。网络在特征上扫描以捕捉微妙的局部关系,例如两种激素及其比值如何共同变化。为了让数据更易处理和更具可解释性,研究者还使用了一种称为主成分分析的技术,将所有谱投影到三维空间,在那里简单的距离度量可以突显紧密匹配。在训练过程中,网络学会输出两份谱来自同一尿液的概率,从而区分真实的相似性与运动员之间及随时间出现的正常生物学差异。
将方法付诸检验
团队在多个方面评估了他们的方法。首先,他们在各年份的保留数据上进行了测试,使用在训练期间未曾见过但在预期的15%测量不确定度内被扰动的谱。卷积网络始终达到很高的准确率,能正确识别相似谱对并保持较低的误报率,且其表现优于诸如逻辑回归、支持向量机和基于树的模型等更传统方法。接着,他们用800多份“确认”样本对系统发起挑战——这些是真实的尿样,实验室在稍有不同的程序下对其重新分析。这些样本为重复或重复使用的样本提供了现实的替代。网络在男女样本上同样表现非常出色,具有优良的敏感性(捕捉真实匹配)和特异性(避免虚假匹配),表明它能够应对真实的实验室噪声和生物学变异。
对清洁运动的意义
对非专业读者而言,关键结论是现在有望自动扫描庞大的反兴奋剂数据库,查找所谓新尿样实际上是旧样几乎一模一样的迹象。所提出的机器学习框架并不取代现有的禁药检测;相反,它增加了一道强有力的后台核查,可将可疑相似的样本标记出来以便更深入的法医审查。尽管该方法在一定程度上依赖模拟数据并使用复杂的“黑盒”模型,透明度不完全,但它仍为体育管理机构提供了实用的新工具。如果将其整合到现有的运动员体征档案系统中,曾经难以察觉的重复使用干净尿样的伎俩将变得风险极高,从而增强人们对奖牌以实力而非操纵获得的信心。
引用: Rahman, M.R., Piper, T., Thevis, M. et al. Detection of sample swapping in anti-doping investigations using machine learning. Sci Rep 16, 9230 (2026). https://doi.org/10.1038/s41598-026-43502-y
关键词: 反兴奋剂, 尿液类固醇谱, 样本调包, 机器学习, 体育诚信