Clear Sky Science · zh
基于数据驱动设计的 LNA 抑制剂用于在 Ribo-Seq 文库中高效去除污染物
为何清理测序数据很重要
现代生物学常依赖读取数百万个微小的 RNA 片段来理解细胞如何合成蛋白质。但这些强大的测量方法,尤其是一种称为核糖体分析(Ribo‑Seq)的方法,常被与研究无关的 RNA 片段污染,浪费测序通量和经费。本研究描述了一种简单、以数据为驱动的方式来设计专门的分子“阻断剂”,有选择地去除这些不想要的片段,从而几乎将相同实验获得的有用信息翻倍。
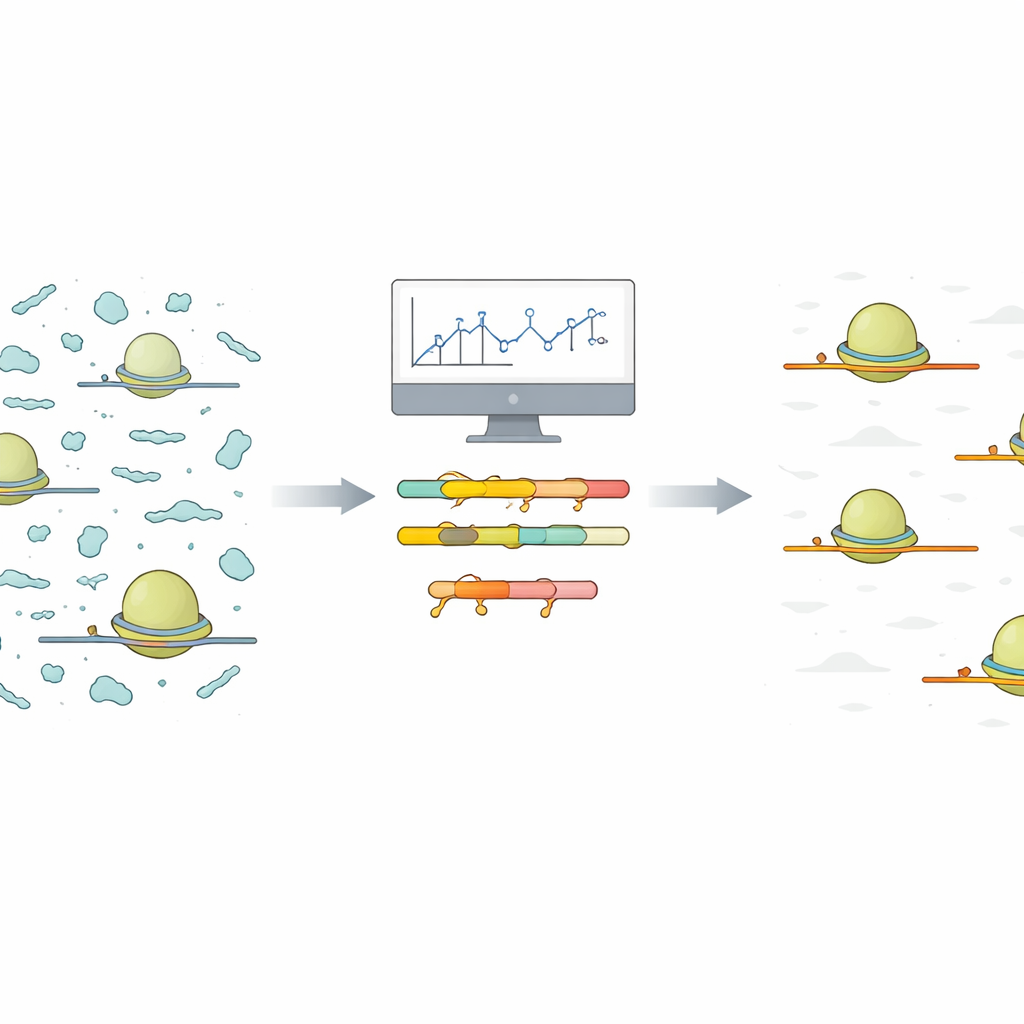
嘈杂的核糖体快照问题
Ribo‑Seq 捕捉细胞中哪些信息分子正在被主动翻译成蛋白质的瞬时快照。为此,研究者分离出与短片段信使 RNA (mRNA) 一起的核糖体,其他部分被降解,受保护的片段被测序并比对回基因组。然而在实际操作中,许多其他小的非编码 RNA 片段也会通过这一流程。由于这些污染片段既丰富又高度可变,它们会消耗大量测序读数,导致用于真正蛋白质编码信号的读数减少,从而影响研究者关心的数据量。
现有净化方法为何力不从心
标准策略试图用预先设计的捕获探针或酶去除丰富的核糖体和其他非编码 RNA。当目标 RNA 完整且可预测时,这些方法效果良好,但 Ribo‑Seq 刻意将 RNA 切成许多不同长度的片段。这样的片段化会扰乱固定探针的靶位点,使得耗竭效率大打折扣。此外,污染物的确切混合物取决于被研究的物种、生长条件,甚至所用的核酸酶。现有的净化流程通常还涉及多个孵育和纯化步骤,既耗时又可能导致样品损失或引入偏差。
基于真实数据设计的定制阻断剂
作者提出了一种简化的流程:从在与计划全量实验相同条件下进行的小规模、低成本的试验测序开始。他们提供了一个 R 脚本,读取该试验运行的比对读数并基于序列自动将相似的污染片段分组。对于每个组,脚本报告出出现在这些片段中的最短共有序列。这些短的共享序列是用于专门分子——称为锁核酸(LNA)寡核苷酸——的理想靶位点。LNA 是带有化学修饰的短链,能与互补 RNA 紧密结合。脚本还生成直观的热图和汇总图,帮助用户看清哪些污染物占主导以及需要多少 LNA 靶点才能实现显著净化。
在扩增步骤中一步完成净化
该方法不是物理上从样品中拉出污染物,而是在构建测序文库的 DNA 扩增步骤中将 LNA 寡核苷酸作为阻断剂使用。作者在初始逆转录步骤或后期 PCR 扩增中分别测试了加入这些阻断剂的效果。结果发现,在扩增过程中加入 LNA 更高效且所需浓度更低,可将测试用污染物降低超过千倍,并且对链向性无依赖。实用设计建议包括交替使用标准 DNA 和 LNA 单元、对拟南芥(Arabidopsis)建议最小长度为 14 个单元,并对尾端进行修饰以防止阻断剂自身被意外延伸。
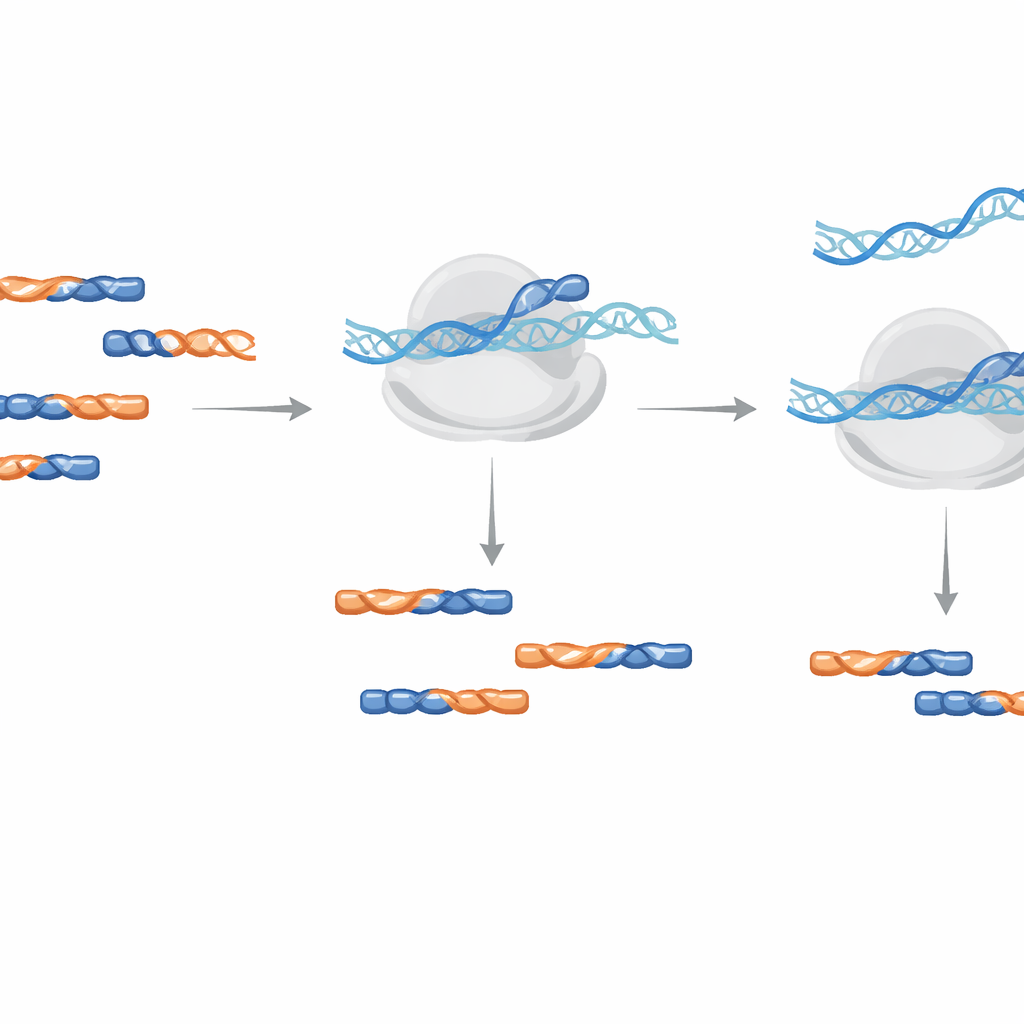
更多有用读数且不扭曲信号
为展示实际性能,团队为拟南芥在典型生长条件下常见的污染物群体设计了五个 LNA 阻断剂。当他们在文库扩增期间加入该混合物时,已鉴定污染物的比例下降了超过 30%,而有用的蛋白质编码读数几乎翻倍。关键是,当他们比较有无 LNA 处理的文库在基因水平上的读数时,数值几乎完全一致,表明阻断剂去除了垃圾片段而不会扭曲真实 mRNA 足迹所反映的生物学信号。
对未来实验的意义
这项工作表明,一个简短的试验运行,配合易用的分析脚本和少量定制的 LNA 阻断剂,就能在一次移液步骤中将杂乱的 Ribo‑Seq 文库转变为更干净、更具信息量的数据集。研究者每次测序能获得更多有意义的读数,节省成本并简化实验设计,同时保持对基因翻译的准确测量。作者还提供了常见植物条件下的现成污染物谱和阻断剂设计,并建议可以为更多生物构建类似资源,从而让高质量的核糖体测序在更广泛的研究社区中更易获得。
引用: Ricciardi, D.A., Peter, F.E. & Böhmer, M. Data-driven design of LNA-blockers for efficient contaminant removal in Ribo-Seq libraries. Sci Rep 16, 8565 (2026). https://doi.org/10.1038/s41598-026-43117-3
关键词: 核糖体测序, RNA 污染物, 锁核酸, 测序文库净化, 翻译调控