Clear Sky Science · zh
解决机器学习建模中关于罕见且破坏性停电事件的数据不平衡问题
更准确的风暴预报为何与你息息相关
当一次重大风暴导致停电时,我们会以非常个人化的方式感受到影响:没有灯、没有采暖、食物变质、通信中断。公用事业公司试图提前预测这些停电,以便部署维修队伍并保障公众安全。但最严重的风暴本质上是罕见的,这意味着关于它们的数据出奇地稀少。本文展示了一种新型人工智能如何“想象”出真实感强的罕见风暴,填补记录中的空白,从而在最关键时刻提高停电预测的准确性。
从罕见灾害中学习的挑战
大多数停电由天气引起,尤其是飓风、东北风暴、雪雨或结冰风暴以及强雷暴。随着气候变暖,这些事件变得更强烈,给老化的电网带来更大压力。然而,造成最大破坏的风暴按定义并不常见。传统统计工具和机器学习模型往往在大量轻微和中等风暴上学得最好,但在少数真正极端的案例上表现不佳。这种数据的不平衡导致对损害的低估,恰恰是在公用事业最需要可靠指导的时候。
教计算机创造新的风暴
为了解决这一不平衡,作者构建了一个生成合成风暴的系统——也就是说,计算机创建的事件在外观和行为上像真实风暴,但不是任何单一历史事件的复制。他们聚焦康涅狄格州,将每个风暴表示为一个包含815个格点、每格有19类信息的网格,信息包括风、雨、气压、湍流、植被和输电线布局等。首先,他们根据“麻烦点”(需要维修队处理的损坏地点)出现的数量和位置,将294个历史风暴分为12个簇。那些罕见且高影响的风暴最终落入四个需要补强的小簇。
新AI模型如何构建真实的极端事件
该框架的核心结合了两种现代人工智能工具。变分自编码器将每个多层风暴图压缩为一个较低维度的“潜在”表示,同时保留重要模式,例如沿海地区更强的风力。在这个压缩空间上,扩散模型学习从随机噪声开始,逐步将其精炼为现实的风暴,且条件化为所需的停电严重性簇。系统随后使用一组度量对生成的风暴进行筛选,将其统计特性与真实事件比较——不仅检查风速等单一特征,还检查特征如何共同变化,通过相关性模式来捕捉。只有在给定簇中在物理和统计行为上都与真实风暴高度匹配的合成风暴才会被保留。
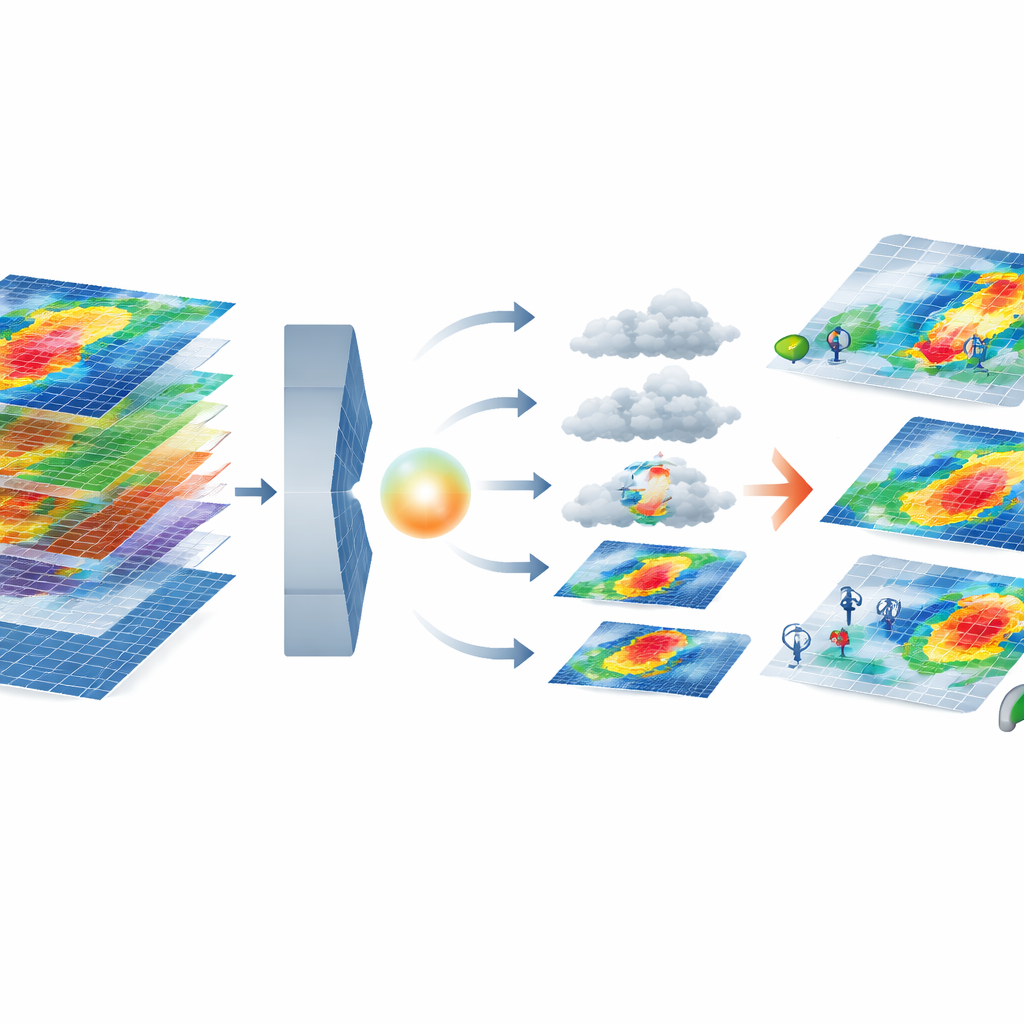
把合成风暴付诸检验
随后作者提出了关键问题:这些合成风暴真的能改善停电预测吗?他们用现有的停电预测模型进行了两次训练——一次仅用真实风暴,另一次在相同数据的基础上对罕见高影响簇加入经过严格筛选的合成事件。他们使用严格的逐风暴留一法进行评估,以模拟对新的、未见过事件的预测。通过合成数据增强后,模型的结构性误差显著下降,总体拟合度提高。对于那些罕见且最具破坏性的风暴,中心均方根误差约下降45%,诸如Nash–Sutcliffe效率等技能汇总指标从劣于基线提升到明显有用的水平。与未经过质量筛选的“随机”增强相比,后者带来的收益要小得多甚至为负,这凸显了严格过滤的重要性。
这对未来风暴意味着什么
简单来说,这项研究表明,让人工智能生成物理上一致的极端风暴——并对所信任的合成风暴进行选择性把关——可以使停电预报在造成最大破坏的事件上更加可靠。通过丰富关于罕见但毁灭性天气的稀疏数据,这一方法帮助公用事业更好地预估将面临多少损坏点及其分布位置。尽管研究示范是在一个州和一种灾害类型上完成的,同样的策略可扩展到野火、洪水及其他自然威胁,为日益严重的气候极端带来一种加强基础设施规划的新途径。
引用: Azizi, M., Zhang, X., Yasenpoor, T. et al. Addressing the data imbalance issue in machine learning modeling of rare and disruptive outage events. Sci Rep 16, 8876 (2026). https://doi.org/10.1038/s41598-026-41838-z
关键词: 合成风暴数据, 停电预测, 扩散模型, 极端天气, 数据不平衡