Clear Sky Science · zh
基于SURD增强型机器学习模型的慢性肾脏病早期检测
为何及早发现肾脏问题很重要
慢性肾脏病常常悄然进展,在肾脏受到严重损害之前很少出现明显症状。然而,简单的血液和尿液检测可以在数年前就揭示问题,在那时干预可以减缓甚至防止病情严重恶化。本研究探索了一种新方法,利用先进但可解释的计算模型筛查这些常规检测结果,以便更早标记高风险人群,并让医生理解背后的原因。
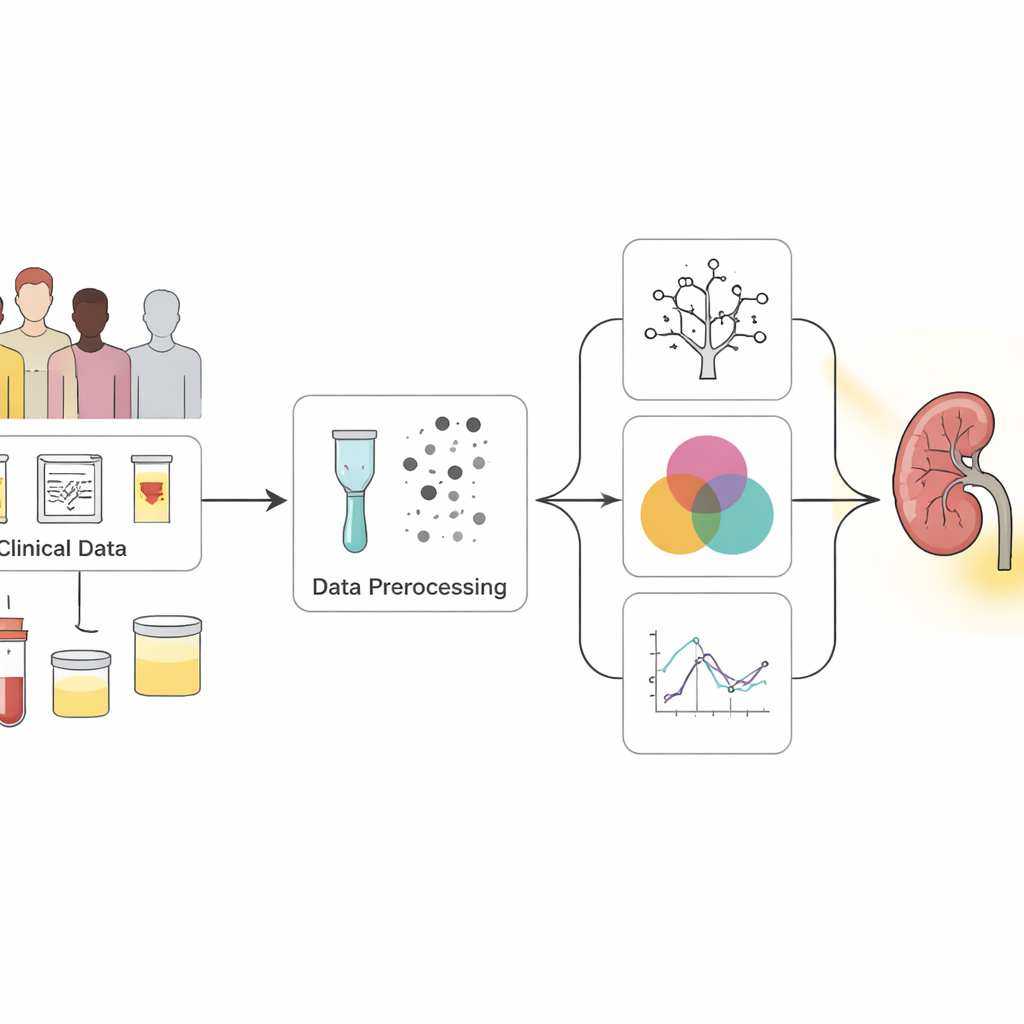
将杂乱的体检数据转化为清晰信号
研究者从一个广泛使用的公开数据集入手,包含400名个体,其中多数已被诊断为慢性肾脏病。每位被试有25项测量值,涵盖血压、血常规、尿液检查以及糖尿病和高血压等病史。许多条目不完整,因此团队使用谨慎的统计技术填补缺失值,而不是简单丢弃患者记录。他们还对数据进行了平衡处理,使健康与患病样本更均衡,帮助计算模型更公平地学习识别两类人群。
超越简单的相关性分析
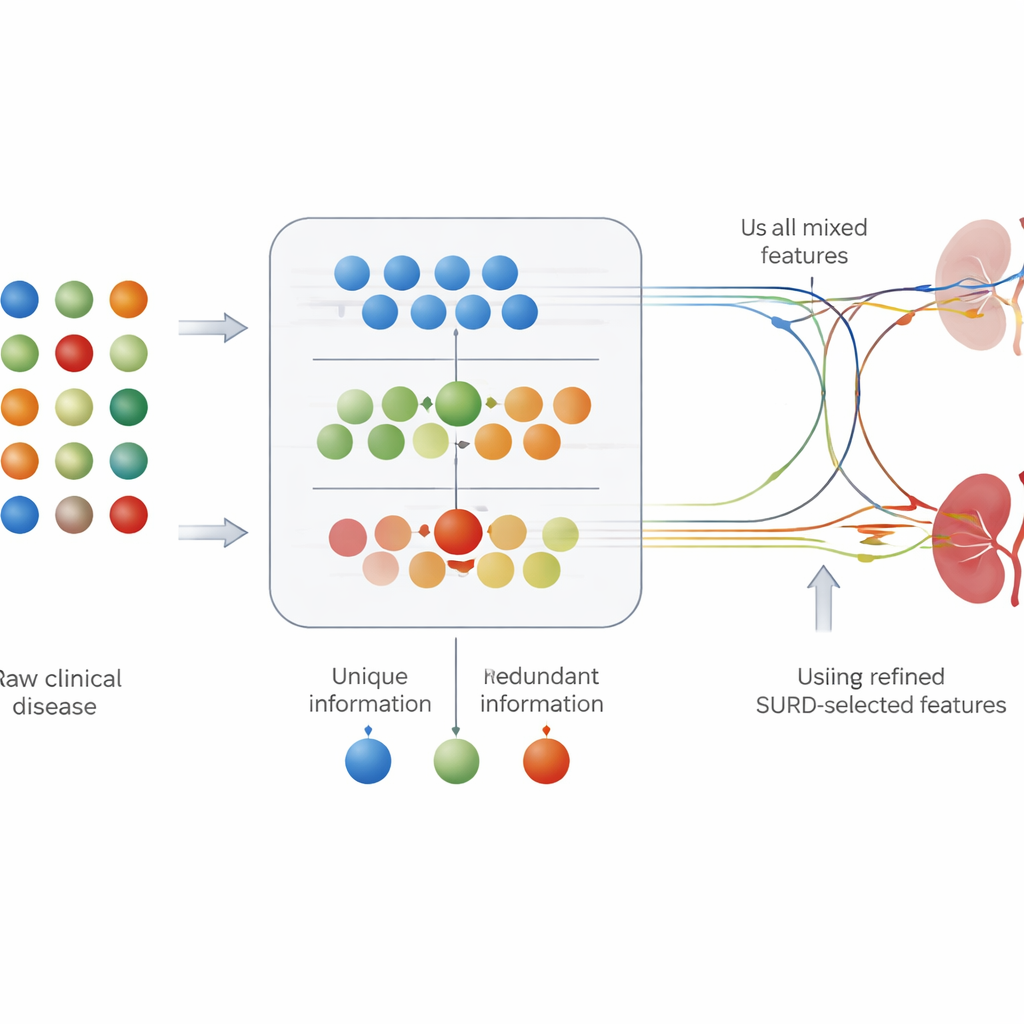
大多数医学预测工具把每项检测结果单独看待:它们考察某个测量值(如血糖)与疾病的关联强度。但在人体内,风险因子很少单独起作用。有些检测传达的信息几乎相同,另一些则只有在与其他检测结合时才有用。为捕捉这些关系,作者使用了一种称为SURD的框架,将每个特征的贡献分解为三部分:与其他检测共享的信息、独有的信息,以及只有当特征协同作用时才出现的信息。这样他们在把特征输入预测模型前,就能把实验室值和临床发现分为“独有”、“冗余”和“协同”三类。
训练多种模型并选择最可靠的
基于这些SURD分组特征,团队训练了十种不同的机器学习模型,从简单的决策树到更复杂的随机森林和神经网络等方法。他们比较了模型使用全部特征与仅使用“独有+协同”合并特征集时的表现。在几乎所有模型类型中,这一经SURD引导的精简特征集的表现不逊于甚至优于包含25个变量的完整集合,常常改善了对患病患者的正确识别与避免误报之间的平衡。特别是基于树的模型,如随机森林和提升树,在原始数据集上取得了几乎完美的得分。
在真实医院数据中检验该方法
在小型基准数据集上表现优异并不意味着模型在更复杂的患者群体中也能奏效。为防止这种误导,作者使用一个包含27000多名重症监护患者的大型医院数据库对其方法进行了验证。在这组数据中,基于SURD选择特征构建的随机森林模型仍能以极高的准确性区分有无肾脏疾病的患者。其表现明显优于更简单的决策树,表明该方法能够从精心整理的研究数据推广到更杂乱的真实医疗记录中。
看清哪些检测重要以及它们如何起作用
仅有准确性不足以满足临床应用;医生还需要知道哪些检测结果在驱动预测。该研究将SURD与现代解释工具结合,后者为每个特征在单个患者的模型决策中分配贡献值。该分析突出了一些熟悉的风险标志,如血肌酐(直接反映肾功能)、血红蛋白水平、尿液浓缩度以及糖尿病或高血压的存在。有趣的是,SURD显示其中一些因素主要是与他人协同作用,而肌酐则作为单独的强信息信号脱颖而出。综合这些技术,研究既提供了模型依赖哪些检测的整体视角,也给出针对单个患者的原因分解,说明为何某人被预测为高风险。
对日常医疗的意义
简而言之,这项研究表明可以构建出既高精度又相对透明的肾病风险计算器。通过将常规化验和病史数据中重叠的信息与真正独特的信息分开,SURD引导的模型在不成为神秘黑箱的前提下给出更明确的预测。尽管还需在更广泛和多样化的人群中进一步验证,这一方法终有可能帮助临床医生更早发现肾脏问题,聚焦最有信息价值的检测,并以通俗的方式向患者解释哪些健康方面在危及其肾脏。
引用: Xue, N., Bai, T., Jia, X. et al. Early detection of chronic kidney disease based on a SURD-enhanced machine learning model. Sci Rep 16, 10444 (2026). https://doi.org/10.1038/s41598-026-41050-z
关键词: 慢性肾脏病, 肾脏风险预测, 医学机器学习, 可解释人工智能, 电子健康记录