Clear Sky Science · zh
评估用于微妙秀丽隐杆线虫品系区分的分辨率要求:经典描述符与 CNN–Transformer 模型
为什么微小的线虫与清晰的图像很重要
科学家经常使用一种显微线虫Caenorhabditis elegans来研究基因、衰老和药物如何影响神经系统。许多线虫品系肉眼看起来在外观和运动上几乎相同,但这些微小差异可以揭示它们的大脑和肌肉是如何工作的。本研究提出了一个实际问题:我们究竟需要多高的图像清晰度才能识别这些细微的运动变化?以及现代人工智能工具在何种程度上能从更高分辨率中获益?
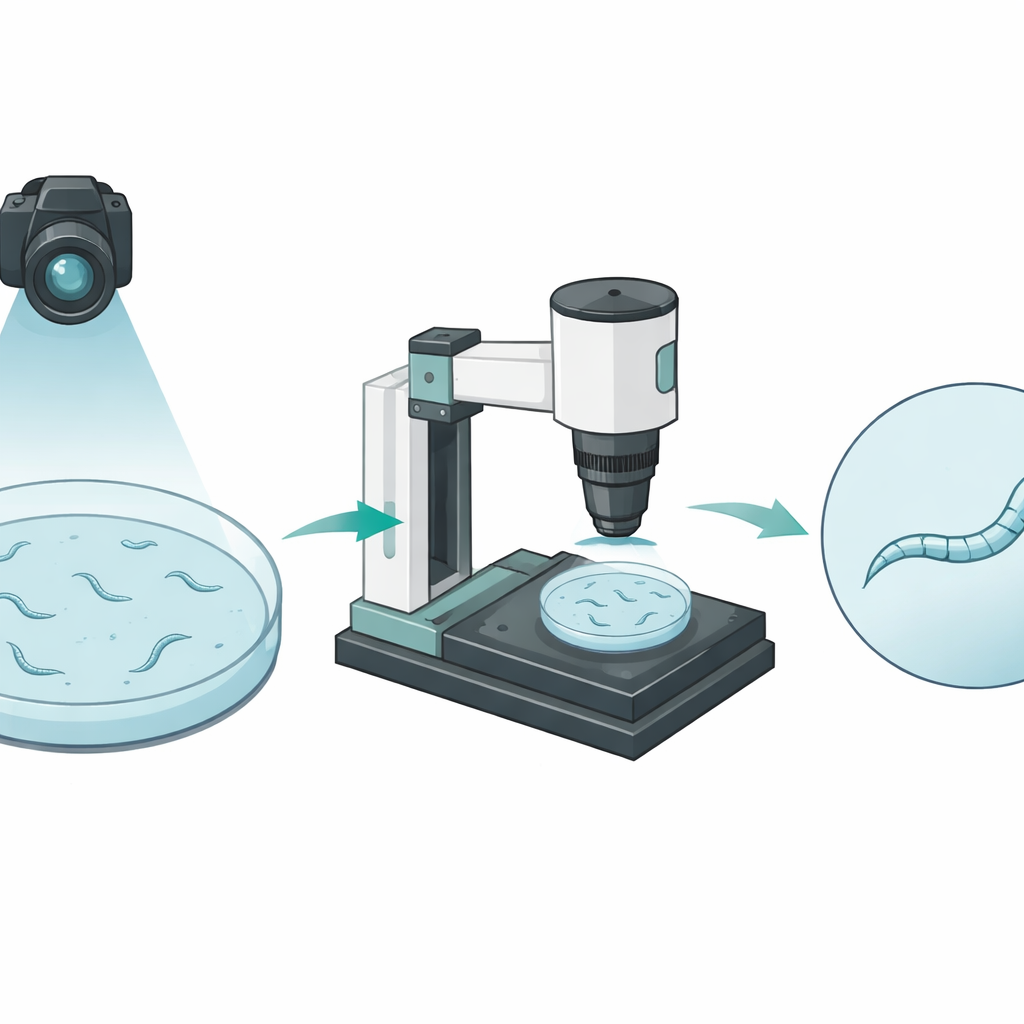
从远处与近处观察线虫
研究人员构建了一个自动成像平台,在两个截然不同的尺度上观察线虫。一对摄像头先从上方拍摄整个培养皿,跟踪许多爬行的线虫。这个广角视野能够记录每只动物移动的距离,但每只线虫在图像中仅占几个像素宽,像是在房间另一侧看到的简化线条。另一个带电机的显微镜可以放大到选定的一只线虫上,保持其在中心并聚焦持续一分钟。在这些特写视频中,线虫的身体宽度占据数十个像素,能显示出其移动时的细微弯曲和形态变化。
简单测量遇到瓶颈
为了比较两种视角能揭示的内容,团队记录了三类线虫。一类是作为参考的标准野生型品系。第二类是运动极其笨拙、容易被辨认的突变体。第三类是经工程改造、仅有轻微运动问题的品系,这类与参考品系即便用肉眼也难以区分。研究者从广角和特写录像中提取了传统度量,例如每只线虫移动的距离、速度以及其身体形态随时间的变化。如预期,两种视角都能清楚地区分出那个极其笨拙的突变体与另外两类。然而,无论单独还是组合,这些标准测量都无法可靠地区分出与正常品系仅有微妙差异的那类线虫。
让深度学习读取运动
接下来,作者转向更灵活的方法:一个直接读取图像序列而非人工挑选测量值的深度学习模型。每一帧首先通过一个卷积神经网络,该网络学习编码线虫的外观。这些逐帧特征随后被输入到一个 Transformer 模块,后者观察姿势在 60 秒片段内如何演变。当该模型在低细节、培养皿宽视角视频上训练时,它在区分微妙品系与参考品系方面的表现与随机机会无异。但在高细节显微镜录像上训练时,模型稳定地以约四分之三的准确率分类这两种品系,发现了标准描述符无法捕捉的微弱运动模式。
需要多少细节才够?
为确定图像清晰度的作用,团队通过将显微镜录像按 2、4、8 和 16 的因子缩小来逐步模糊图像,并每次都重新训练相同的深度模型。当线虫的身体仍然占据数十个像素宽时,性能保持较高,表明模型能容忍适度的细节丢失。一旦线虫缩小到只有大约十个像素宽或更少,准确率急剧下降并在不同实验间变得不稳定。在最粗糙的尺度下,结果接近于培养皿宽视角和简单统计方法的表现,这表明轻微运动缺陷的细微信号在图像中已经基本消失。
这对未来线虫研究的意义
对于只需区分明确运动缺陷的实验来说,宽视角低分辨率似乎已足够,经典的距离和速度测量也能很好地工作。但当目标是检测线虫弯曲与身体协调的细微变化——例如由轻微基因改变或温和药物效应引起的变化——本研究表明既需要高分辨率成像,也需要基于序列的深度学习模型。简言之,要在这些微小动物身上看到疾病或治疗效应的微弱“低声耳语”,我们不仅要看得够近,还要使用足够智能的工具来读取其运动中编码的细微模式。
引用: Peñaranda-Jara, JJ., Escobar-Benavides, S., Puchalt, JC. et al. Evaluating resolution requirements for subtle caenorhabditis elegans strain discrimination using classical descriptors and CNN–transformer models. Sci Rep 16, 8664 (2026). https://doi.org/10.1038/s41598-026-40784-0
关键词: C. elegans 运动学, 表型分类, 图像分辨率, 深度学习, 行为跟踪