Clear Sky Science · zh
用于云环境工作负载预测的动态机器学习方法
为何智能流量预测很重要
每当你观看视频直播、在线观看大型体育赛事或在限时抢购中购物时,可能有成千上万的人同时点击。背后,云数据中心必须努力保持网站响应迅速,同时又不能在闲置机器上浪费资金。本文解决了一个简单但实际影响巨大的问题:云系统如何足够提前预判突发的网络流量潮,以便及时开启或关闭服务器,而不是靠猜测而导致过度支出?
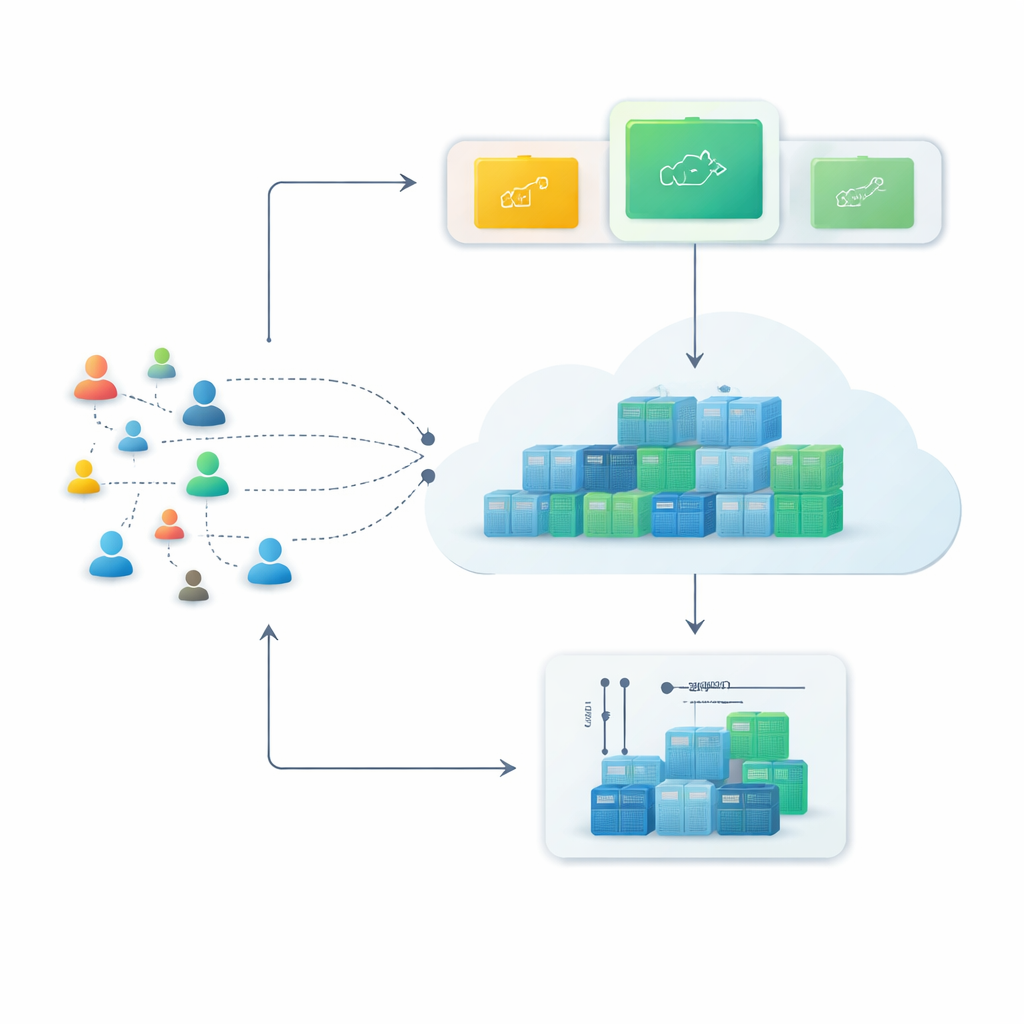
从僵硬的服务器到灵活的容器
现代云平台越来越依赖容器——可以在几秒内启动或停止的小型软件包。与传统虚拟机相比,容器更轻量、可更高密度部署,这使得它们非常适合在高峰时段快速扩展、事后再收缩的服务。然而,这种灵活性只有在系统能够预见风险时才有价值——即能够预测未来几分钟会有多少请求到来,并提前准备合适数量的容器。
为何一刀切的预测方法行不通
早期研究尝试了多种预测网络流量的方法,从经典统计学到深度神经网络。有些方法在需求平稳变化时表现良好;有些在流量突变(例如世界杯比赛期间)时更合适。问题在于没有一种方法能始终最佳。如果运维人员选定一种偏爱的模型并长期使用,当用户行为发生变化时,准确率可能会急剧下降,导致要么网站变慢,要么大量闲置机器持续消耗资金和能源。
永不停歇的学习闭环
为了解决这一问题,作者提出了一个闭环框架,称为监控–训练–测试–部署(Monitor–Train–Test–Deploy)。其思想是将预测视为一个动态的过程。首先,系统持续将到达的请求按时间戳记录为历史数据。接着,多个不同的预测方法并行训练,各自尝试从最近的历史中学习模式。然后在最新数据上测试这些候选模型,并根据预测与真实情况的偏差对它们打分。只有表现最好的模型会负责生成实时预测,进而决定运行多少容器。随着新流量到来,循环重复:若预测误差在两个周期内连续超出容忍范围,系统会自动重新训练并可能把控制权交给另一模型。
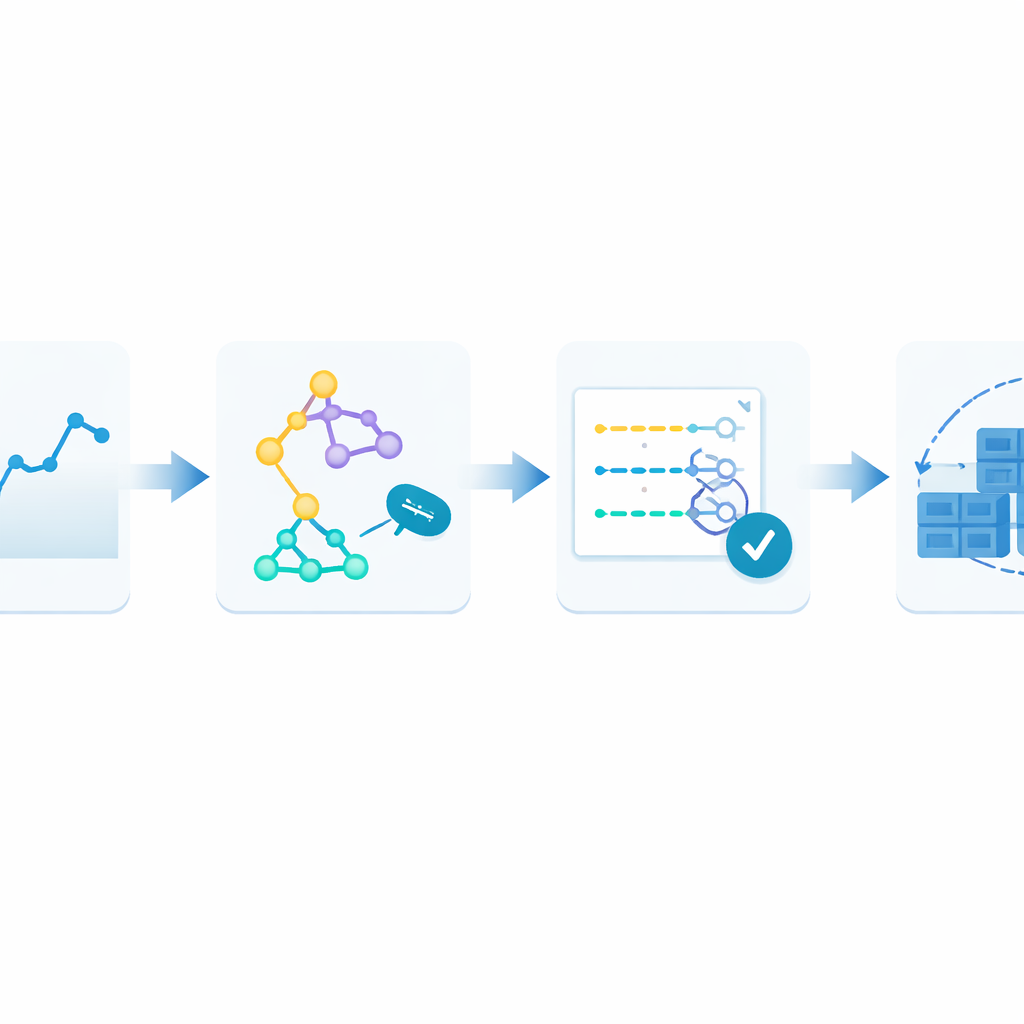
将框架付诸测试
研究人员使用合成和真实的网络活动轨迹评估了该方法。他们生成了几种理想化模式——平滑的钟形曲线、以不同速率平稳上升的负载以及高度不稳定的流量,同时还使用了1998年和2018年世界杯官网的记录,这些记录中兴趣会突然激增。针对每种情况,他们比较了三到四种常见的预测工具,包括基于统计的方法、支持向量模型、决策树集成,以及在后续实验中一种常见的循环神经网络。关键结果是“赢家”会随情境而变化:当需求平稳时,简单的统计模型表现出色,而在流量异常波动时,基于学习的方法明显更优。
准确性与效率的提升
通过不断切换到当前最适合观测行为的模型,该框架将预测误差最多降低约15%,相比于始终采用某一固定模型。同时重要的是,它并不需要始终运行所有模型。在线运行时仅有一个预测器处于激活状态;其他模型则定期被重新训练和评估,从而将计算负担保持在适中水平。作者还提出了逐步收紧的重训练阈值,使系统对重复错误的容忍度降低,减少长时间预测不佳的风险。
这对普通云用户意味着什么
在实际层面,该研究表明通过让预测模型竞争并随时间调整选择,云平台可以变得更智能。对于用户,这可能意味着在大型事件期间更顺畅的在线体验以及在人群突增时更少的延迟。对于服务提供者,它有望实现更精简的资源使用、更低的运营成本和更少的能源浪费。与其押注于单一“聪明”算法,这项工作主张采用一个持续学习、测试和修正的灵活控制回路,以应对日益不可预测的数字世界对需求的挑战。
引用: Nashaat, M., Moussa, W., Rizk, R. et al. Dynamic machine learning approach for workload prediction in cloud environments. Sci Rep 16, 10983 (2026). https://doi.org/10.1038/s41598-026-40777-z
关键词: 云工作负载预测, 自动扩缩容, 容器, 机器学习, 时间序列